
optimizing_cpp(1-4)
optimizing_cpp
一、简介
本笔记是对Agner Fog优化手册中cpp优化手册的笔记,记录下对自己有用的东西。
二.选择最优平台
编程语言的发展揭示了一个曲折的历史,反映了执行效率、可移植性、开发效率的冲突。
三种类型的编程语言较好的解决以上三种问题:编译型、中间代码和即时编译(intermediate code and just-in-time compilation)或者中间代码和解释器(例如某些java)、解释型。
在优化之前要选择最优的平台,步骤可以为选择硬件-选择编程语言-选择编译器-选择函数库
选择编译器时有以下几种考虑
- GNU:开源免费跨平台
- intel:可以自动cpu调度,为不同的cpu制定多核版本代码,但是在其他品牌的cpu运行效率不好
- clang:基于LLVM,性能很强
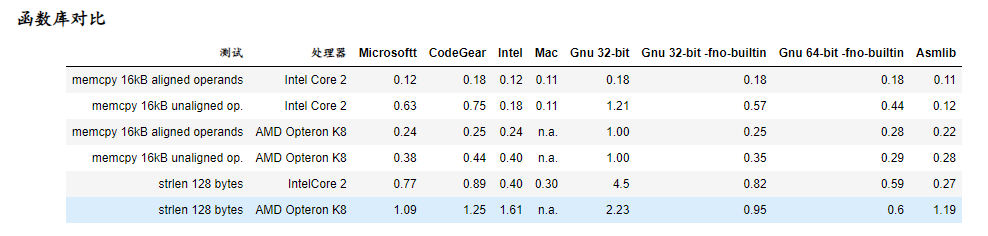
选择函数库
 cpp的安全性问题
cpp的安全性问题
cpp的安全性就体现在指针上,为了避免出错,要坚持几个编程原则
①为了避免出现无效指针(nullpointer)
- 使用引用代替指针
- 将指针初始化为零
- 一旦指针指向的对象变为无效,把指针设置为零
- 避免指针运算和指针类型转换
②另外,为了防止数组溢出,可以使用充分测试的容器类来代替数组,例如STL库,有关如何避免动态内存分配的问题后面会说明
三.寻找程序热点
1.使用profiler找到热点
以下为几种常用的性能分析(profiling)方法
- 插桩(Instrumentation):编译器在每次函数调用时插入额外的代码来计算函数调用次数和执行花费的时间
- debugging:在每个函数或者代码处插入断点
- 基于时间的采样:分析器告诉操作系统产生中断,例如,每毫秒一次。分析器计算程序每个部分中断发生的次数。这不需要修改正在测试的程序,但不太可靠
- 基于事件的采样:分析器告诉CPU在某些事件时产生中断,例如,每当一千次高速缓存未命中时。这样就可以发现程序的哪一部分具有最多的高速缓存未命中,分支错误预测,浮点异常等。基于事件的采样需要CPU特定的分析器。对于Intel CPU,需要使用Intel VTune,AMD CPU则使用AMD CodeAnalyst。
最常用的方式就是将插桩代码直接放入代码中,而不是使用现成的分析器(这里后面会详细阐述,记得回头看一眼)
2.动态链接和位置无关代码(position-independent code )
有几个因素会使得动态链接库比静态链接库慢,会在下面详细解释。
position-independent code 常用在unix系统中的so文件,mac系统默认情况下经常使用位置无关代码,position-independent code 效率低下,尤其在32位模式下,原因下面会详细解释。
3.文件访问
在IO密集型程序中,访问磁盘常常是占用时间极多的,在访问文件时有以下几个小建议:
顺序前向访问文件比随机访问快。读取或者写入大的数据块比多次读写小数据要快。可以将文件镜像到内存的缓冲区中,并一次性读写。
访问最近访问的文件要比第一次访问文件要快的多。因为该文件被复制到磁盘缓存。
对于包含数值数据的大文件,以二进制形式存储,比数据以ASCII形式存储更加紧凑和高效。
如果在等待磁盘操作完成时处理器可以执行其他工作,则将文件访问放入单独的线程中可能是有利的。
4.内存访问
访存通常是一个重要的优化项目,着手点在于cache。通常情况下,cpu有一级缓存二级缓存还可能有三级缓存。下列情况下,很可能内存访问是程序中最大的时间消耗:程序中所有数据的组合大于二级缓存且数据分散在内存中或者以非顺序方式访问。
如果数据被存入cache,读写只需要2-3个时钟周期,但如果没有cache,则需要几百个时钟周期。
5.上下文切换
上下文切换在多线程程序中主要指多个线程之间的切换,频繁上下文切换会降低性能
6.依赖关系链
依赖关系链是一系列的计算,每个计算取决于前一个的结果,依赖关系链会组织CPU同时进行多次计算并阻止乱序执行(乱序执行是指如果制定了先A再B的计算,微处理器可以在计算A完成之前开始B的计算,显然这只有在计算B之前不需要A的值才可能),关于如何有效中断依赖关系链,后面会详细说明。
7.执行单元吞吐量
执行单元吞吐量(throughout)和latency(延迟?应该为等待单个计算完成的时间)有本质的差别。例如,在现代CPU上执行浮点加法可能需要3到5个时钟周期。但是有可能在每个时钟周期开始一个新的浮点加法。 这意味着
- 如果每次加法都取决于前面加法的结果,那么每三个时钟周期只有一次加法。
- 但是如果所有的加法都是独立的,那么你可以在每个时钟周期进行一次加法。
因此当计算密集型程序满足前面提到的各种情形不是耗时的主要原因并且没有长依赖关系链,此时性能受单元吞吐量限制,而不是lantency或者IO
现代微处理器的执行核心切分为几个执行单元。通常,
- 有两个或更多个整数单元,
- 一个或两个浮点加法单元
- 以及一个或两个浮点乘法单元。
这意味着可以在同一时间进行整数加法,浮点加法和浮点乘法运算。
所以如果一段代码进行浮点运算,最好混合浮点加法或者整数运算,在浮点运算之间,可以进行整数运算而不降低性能,这是因为整数运算使用不同的执行单元。
四.选择最优算法
当优化一个计算密集型程序时,首先要找到最好的算法,在编写代码前,要考虑其他人是否已经做过这项工作(造好的轮子),Anger给出的例子
- Boost的集合包,包含用于许多通用的,经过良好测试的库 www.boost.org。
- “英特尔数学核心函数库”(”Intel Math Kernel Library”)包含许多常见数学计算函数,包括线性代数和统计学
- “英特尔性能基元”(”Intel Performance Primitives”)函数库包含许多用于音频和视频处理,信号处理,数据压缩和加密的函数 www.intel.com。
如果使用英特尔函数库,要确保它在非英特尔处理器上正常工作。
 wechat
wechat alipay
alipay



