DeePMD
DeepMD
参加ASC2022比赛对deepmd所做的学习,实在太菜了,贴上来做个纪念吧
赛题
对于该任务,参与者需要在给定的数据集上使用DeePMD-kit包对DeePMD模型进行训练,然后对训练过程进行改进和分析。更具体地说,该任务可以分为3个步骤
1 、工作下载DeePMD-kit的源代码,完成编译和安装。然后在给定的系统上训练三种模型,使它们的基线(baseline)被分别优化。
2、深入研究DeePMD-kit 训练部分代码的实现,并对其进行改进,以加快gpu上的训练过程。
3 、对改进进行分析,提交修改后的代码,并提供详细的报告,包括对DeePMD-kit的了解,具体的优化方法和改进。
分数是由相对性能提高决定的
1.编译和下载DeePMD-kit
参考一下网址:
deepmd-kit/install-from-source.md at devel · deepmodeling/deepmd-kit (github.com)
2.训练
例如:

我们的目的为优化训练的时间计算相对性能
3.数据格式
The example water dataset in DeePMD-kit format can be found in $deepmd_source_dir/examples/water/data/data_0, which contains several necessary inputs for training models. The model takes coordinates of each atoms (set.000/coord.npy, in numpy format, shape : [num_of_samples, num_of_atoms_per_sample * 3]), atomic type (type_map.raw mapping the index to specific element, type.raw mapping atomic indexes in each sample to corresponding element) and box size of each sample (set.000/box.npy, in numpy format, shape : [num_of_samples, 3 * 3]) as inputs, and predicts the corresponding energy of samples (set.000/energy.npy, in numpy format, shape : [num_of_samples, ]) and atomic forces (set.000/force.npy, in numpy format, shape : [num_of_samples, num_of_atoms_per_sample * 3]).
输入数据:
原子的坐标:coord.npy文件
原子类型:raw文件(包括type_map.raw type.raw)
每个样例的box size:box.raw
输出:
样品对应的能量:energy.npy
原子受力:force.npy
4.评估
注意:所有团队需要使用DeePMD-kit的ASC22分支
使用三种:Water, Copper and Al-Cu-Mg ternary alloy进行评估
包括 data_sets input.json,data_sets表示输入数据集,input.json控制DeePMD-kit的训练过程
input.json的格式参考文档[ASC22 Preliminary Round Notification (1).pdf](file:///C:/Users/might/Downloads/edge下载/ASC22 Preliminary Round Notification (1).pdf),要注意的是只允许更改三个参数:
1 | "model/descriptor/precision” #descriptor的精度 |
5.测试
使用一下命令即可测试正确性

要注意任何优化方法必须保证优化过的项目执行的测试结果和asc-2022分支的测试结果一致
6.提交
提交格式:
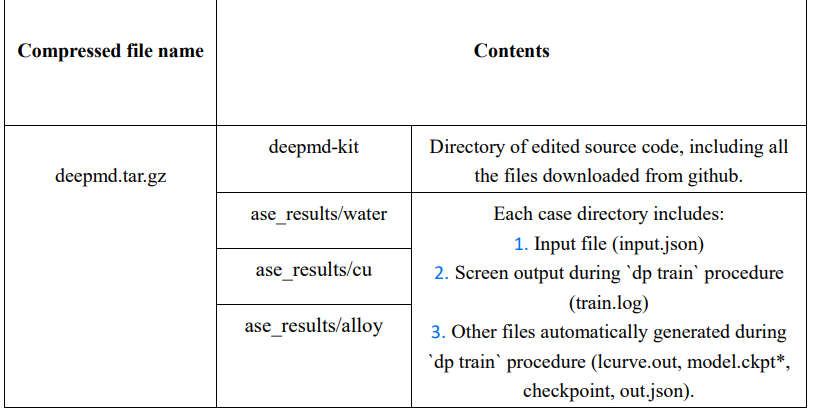
示例:

实际安装
先从github下源码
1.python接口
先创建python3的虚拟环境(~/ASC/venv),然后在虚拟环境内安装tensorflow,然后回到deepmd的源码目录下,pip install .
为了并行加速,按照教程安装Horoved和mpi4py
Horoved
1.先安装NCCL(NVIDIA Collective Communication Library)
这里涉及到非全局安装的问题,在自己的~目录下修改
.bashrc文件来保存$PATH$LD_LIBRARY_PATH

因为无法root安装,采用源码编译的方式,见官方文档NVIDIA/nccl: Optimized primitives for collective multi-GPU communication (github.com)并参考Linux下NCCL源码编译安装 - chenzhen0530 - 博客园 (cnblogs.com)
在编译的时候要制定安装的cuda的目录,cuda也是我从源码安装的目录为/home/u2600489/cuda,所以编译的时候命令为
1 | make -j64 src.build CUDA_HOME=/home/u2600489/cuda |
编译后的文件在/home/u2600489/nccl/build中,这里要注意NCCL_HOME应该是/home/u2600489/nccl/build而不是/home/u2600489/nccl
2.安装nv_peer_memory(v100会用到)
安装地址
3.安装openmpi
本机自带,但是不能用服务器上那个!版本太低,要自行安装新版本的
4.安装horovod
1 | HOROVOD_NCCL_HOME=/home/u2600489/nccl/build HOROVOD_NCCL_LIB=/home/u2600489/nccl/build/lib HOROVOD_NCCL_INCLUDE=/home/u2600489/nccl/build/include HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_WITH_MPI=1 HOROVOD_GPU_OPERATIONS=NCCL HOROVOD_WITH_TENSORFLOW=1 pip install --no-cache-dir horovod pip install --no-cache-dir horovod |
注意nccl地址不要填错,我的是/home/u2600489/nccl/build
mpi4py
pip安装即可,我们miniconda下已经安装
数学原理
本文档只是整理训练过程的步骤,具体数学推导过程可以参照原论文和b站的一个视频https://www.bilibili.com/video/BV14L411E7nf?share_source=copy_web
概述

要保证可拓展性和物理性质(三个不变性)
设计模型:
求势能
这里Ei为每个原子的势能,用每个原子的势能之和来表示系统的势能,下面的式子,Ri表示在原子子周围固定范围内的原子们(只看固定范围内的),将其先过一个装饰器D,再过一个拟合神经网络得到势能(先过装饰器的原因是为了保证对称性,再过神经网络得到单点势能)

(1)计算Ri
下图Ri矩阵大小为邻居原子数*4(第一个s(rj)是相对距离,通过下面的式子求出,后面三个就是对中心原子的相对坐标)

(2)过embedding层(嵌入层:将离散变量转变为连续向量)
这里把标量(上一步求出来的相对距离)作为输入,把连续向量作为输出,大小为邻居原子数*embedding输出长度
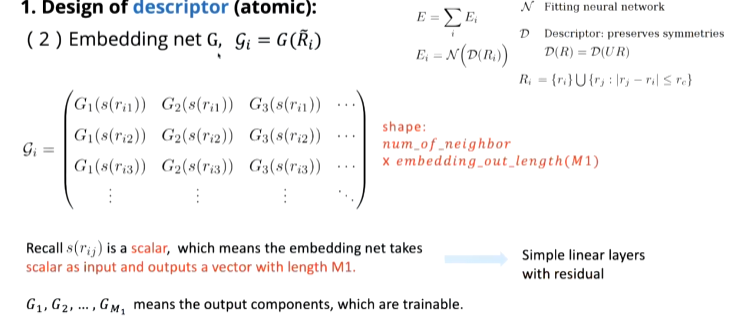
(3)矩阵乘法(为了保证对称性)

将四个矩阵相乘得到Di
(4)过神经网络

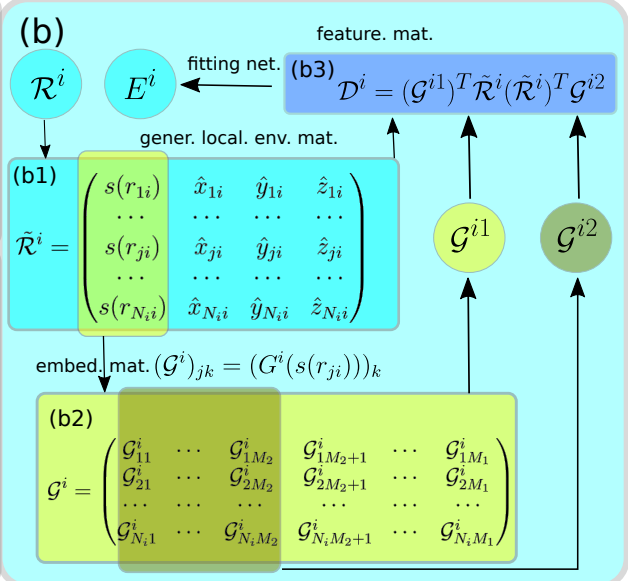
完整的过程可以由下图表示:
求受力
受力是根据物理上的一个定义(关于能量关于坐标的一个负梯度即下面的公式)得到的
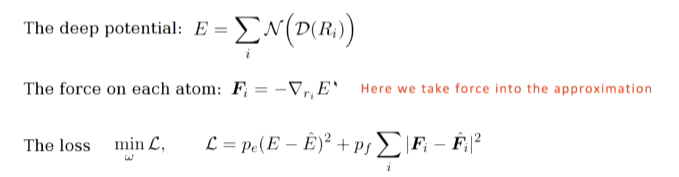
这里进行两次反向求导,第一次反向求导得到受力,第二次反向求导得到loss进行反向更新
源码分析
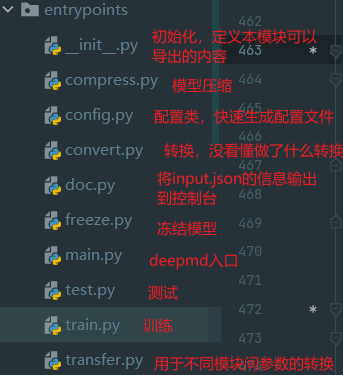
1.代码结构
deepmd目录下是python的一些模块
source目录是源代码和相关的库
source目录下比较重要的有lib和op
source/lib/src为custom op具体实现(其实混合精度应该并不涉及这部分)
source/op为custom op的具体调用

蓝色是用c++实现的op,橙色的是tensorflow的标准op
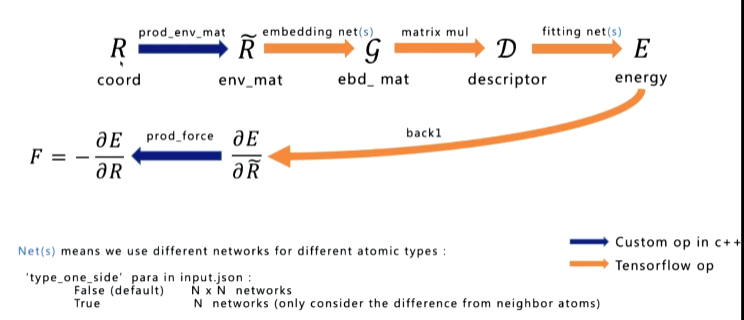
第一步用gpu分块比较好,所以自己实现,最后一部分是为了求受力
这里面需要注意的是拟合网络是net(s),每一种不cd 同元素的原子我们用不同的网络,网络数由input.json中type_one_side参数决定,默认false则根据原子pari的种类数来决定,比如水有OH,OO,HH,HO四种,就用四种网络,若true只会考虑邻居原子的类型,如水就是两种网络
完整图如下
这里多出来的求导部分主要是为了受力的反向传播,所以又求了一次导
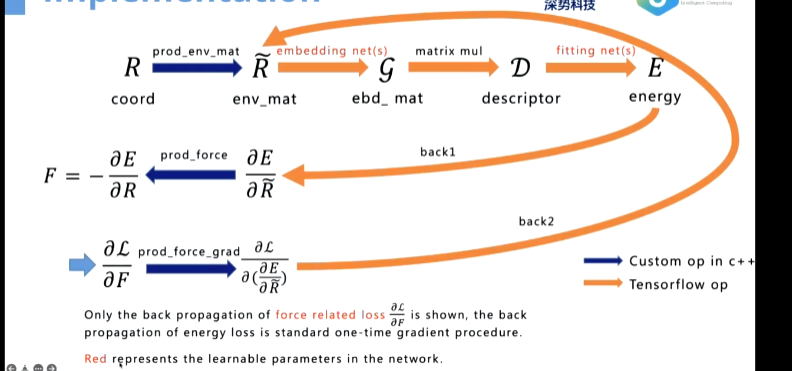
其他注意事项
两个重要参数
代码运行过程如下,可以从man.py开始
每一次修改代码都要pip重新安装
nvprof 查找热点工具

2.相关文件
lcurve.out
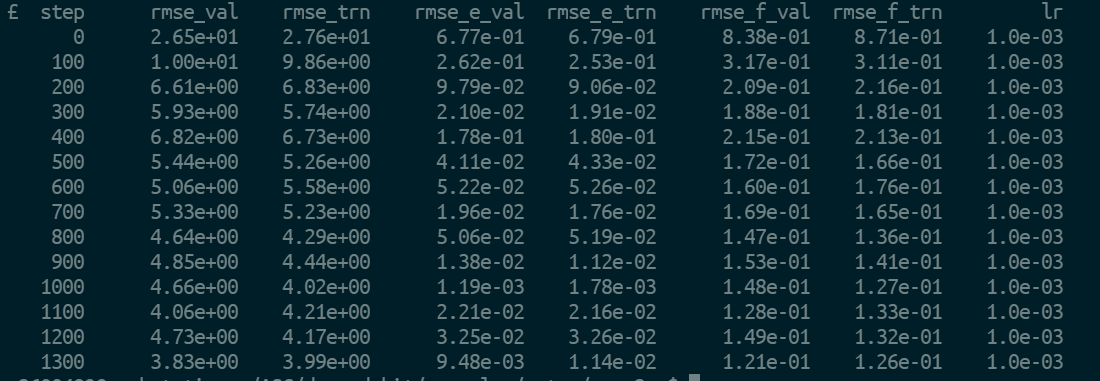
训练步长 验证loss 训练loss 能量的均方根(RMS) 验证误差 能量的RMS训练误差 力的RMS验证误差 力的RMS训练误差 学习率
input.json
只需要关注三个参数
1 | "model/descriptor/precision” #选择装饰器用什么精度 |
precision:
type: str, optional, default: float64
argument path: model/descriptor[se_e2_a]/precision
The precision of the embedding net parameters, supported options are “default”, “float16”, “float32”, “float64”.
type_one_side:
type: bool, optional, default: False
argument path: model/descriptor[se_e2_a]/type_one_side
Try to build N_types embedding nets. Otherwise, building N_types^2 embedding nets
model.ckpt* checkpoint
tensorflow的检查点文件,用于保存训练的模型
out.json
将input.json省略的默认参数补全
train.log
滚屏信息文件,要手动在执行dp的时候重定向到train.log
3.源码分析

(1)entrypoints
(2)train.py
进入train.py查看训练过程
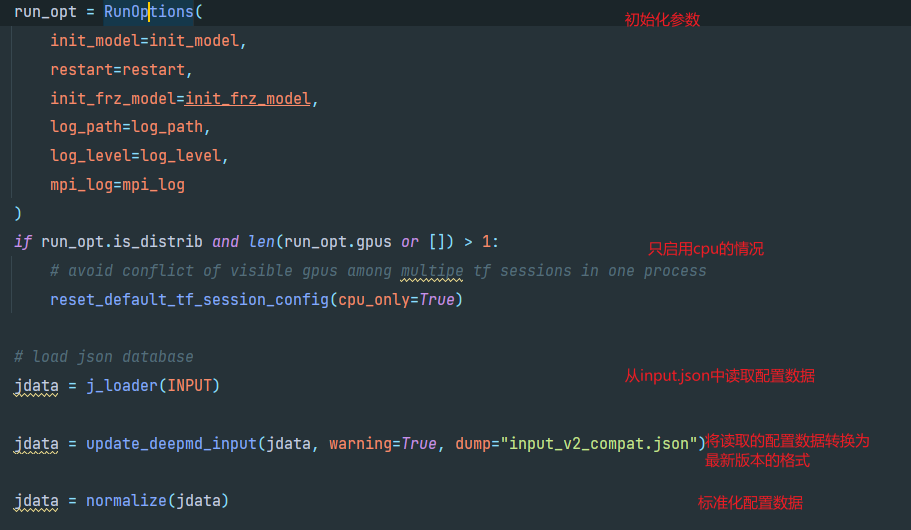
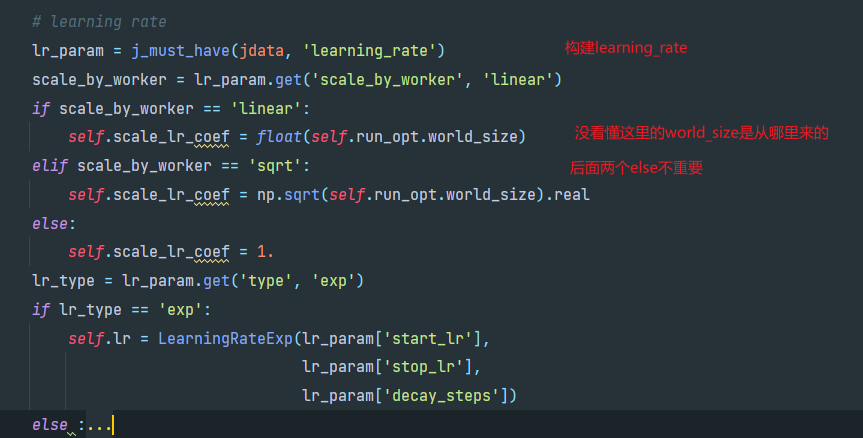
其中一开始跳转到run_options.py的RunOptions类,_init_方法中首先调用_try_init_distrib方法,使用horovod做分布式训练,若HVD.size()>1,则调用_init_distributed()初始化分布式训练
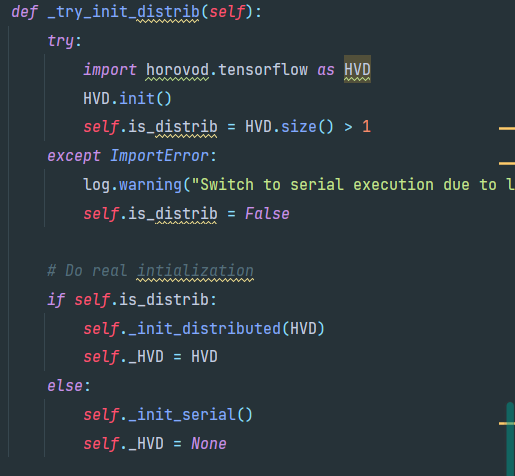
回到train方法来,在对jdata进行一系列处理后进入_do_work,开始训练
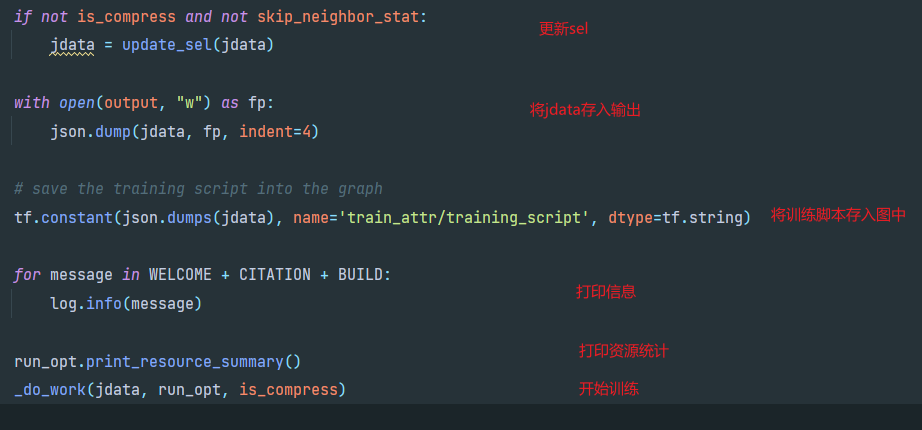
(3)_do_work
这个函数是执行的线性训练
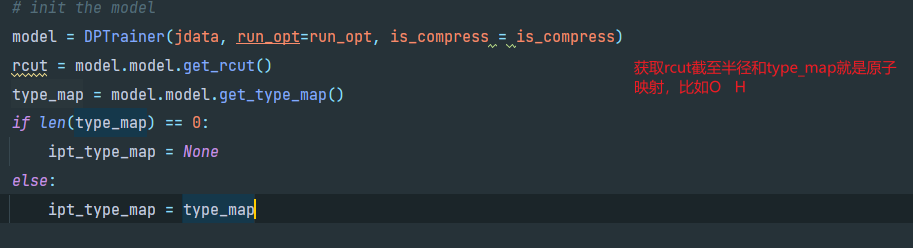
首先构造DPTrainer类,DPTrainer的定义在trainer.py中,从jdata(input.json)和run_opt(控制台参数)中获取DPTrainer的属性
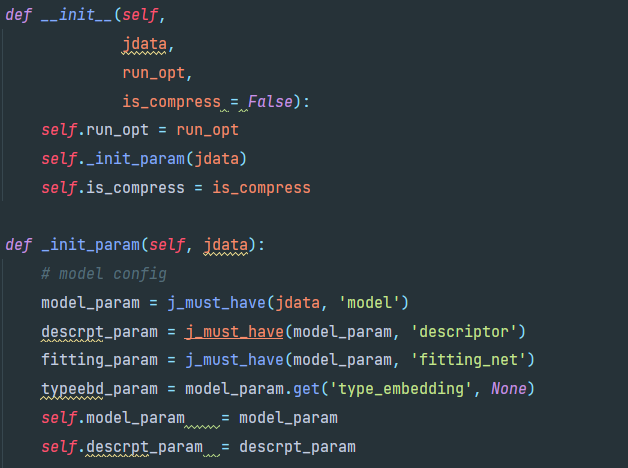
构造descrpt
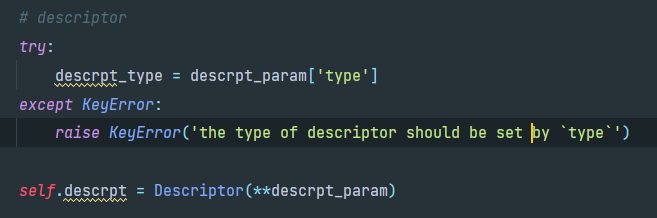
然后构造fitting net
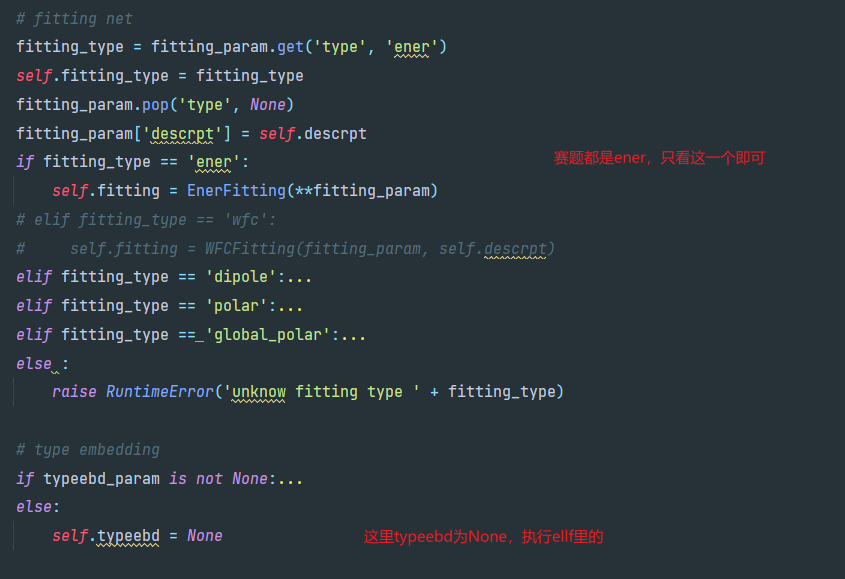
初始化模型
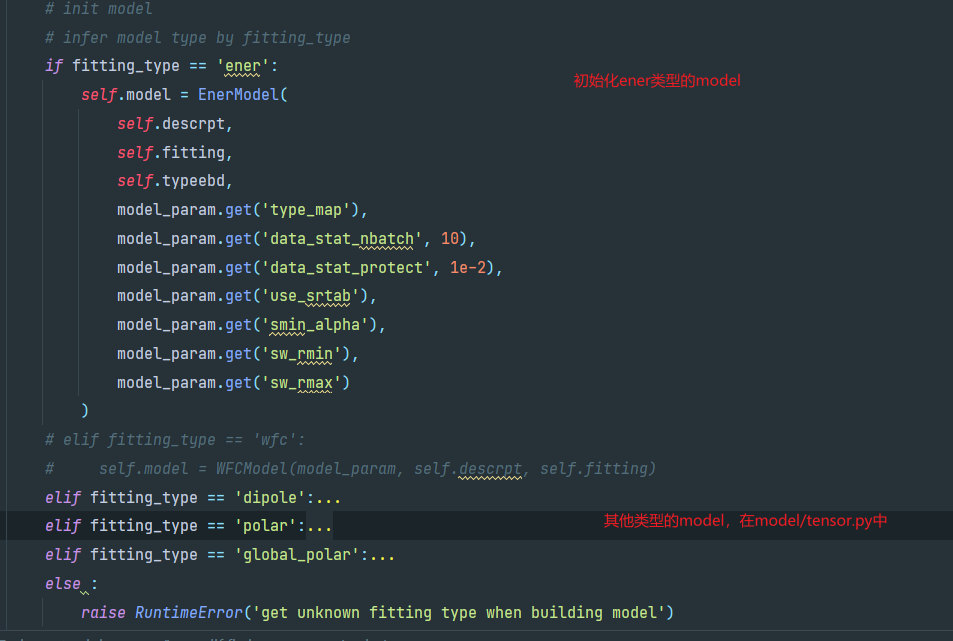
初始化学习率
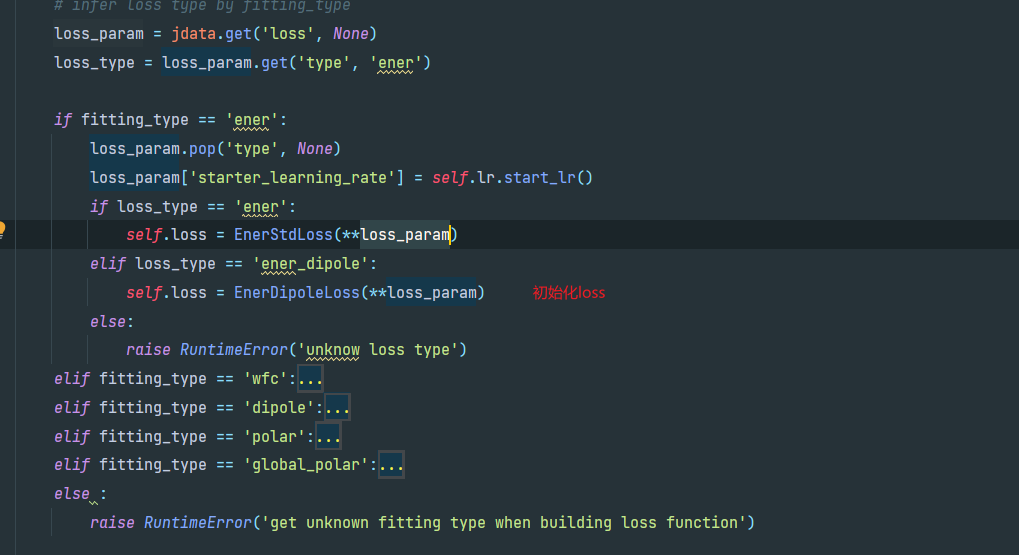
初始化loss
DPTrainer构造结束后,回到train.py的_do_work方法
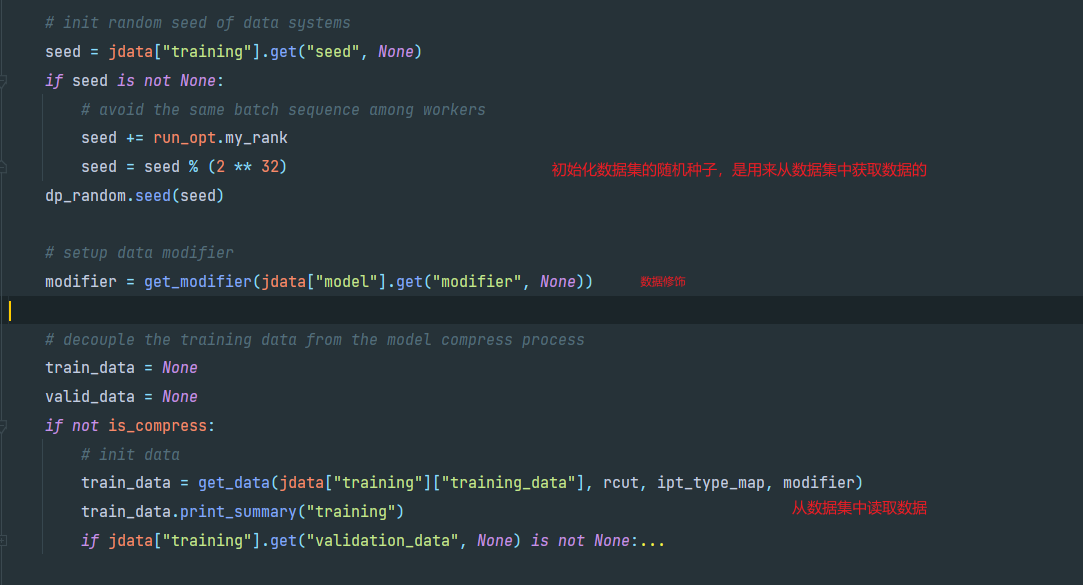

接下来进入trainer.py的build方法
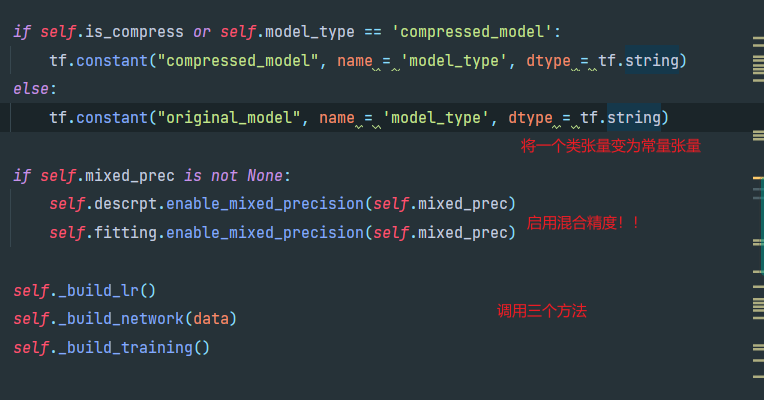
在_build_network这个方法里build了model
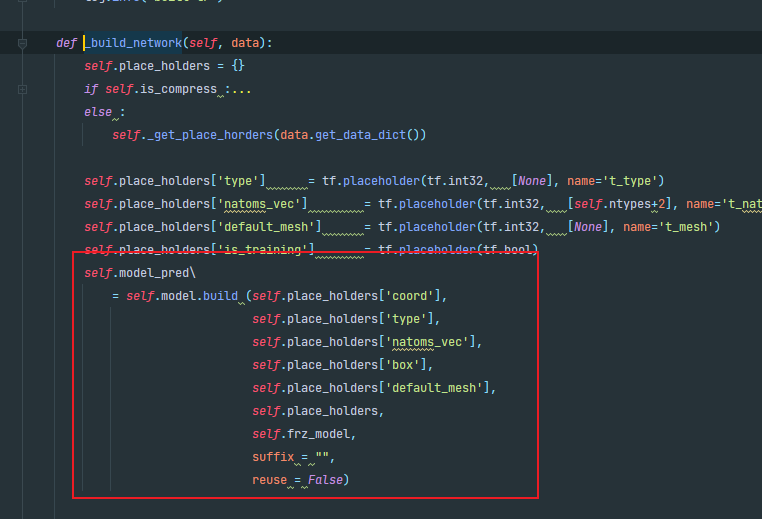
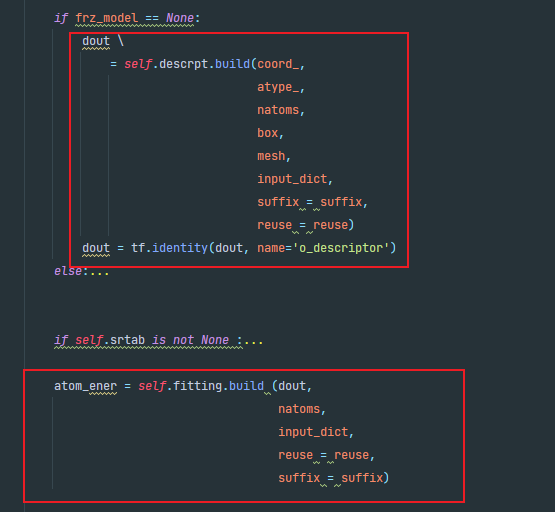
进入model.build,在这里descript和fittiingnet进行了build
需要关注_build_training这个方法
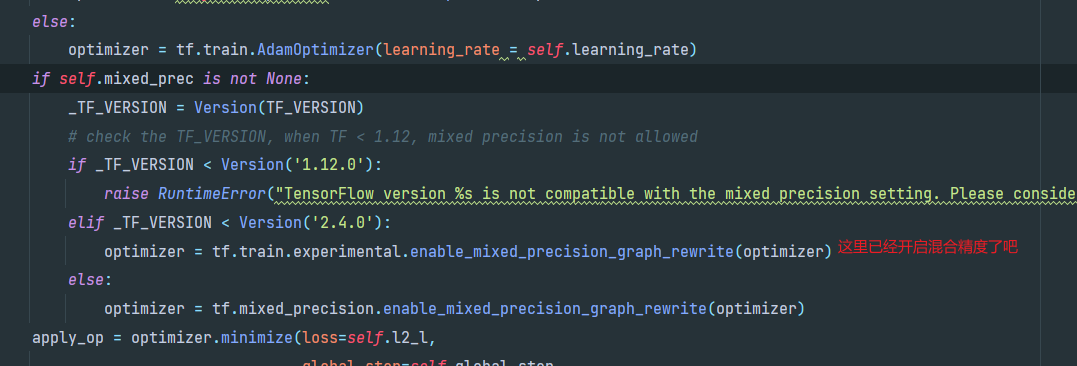
最后在train.py中调用train方法,进入trainer.py中
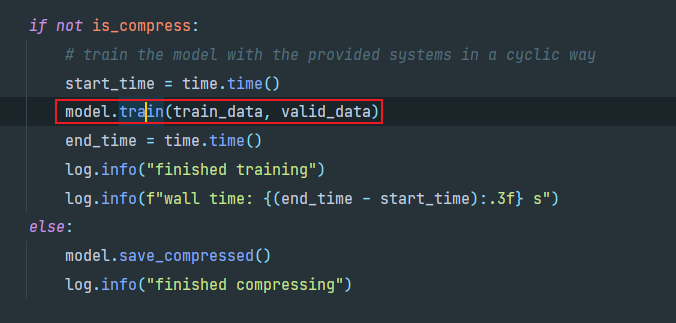
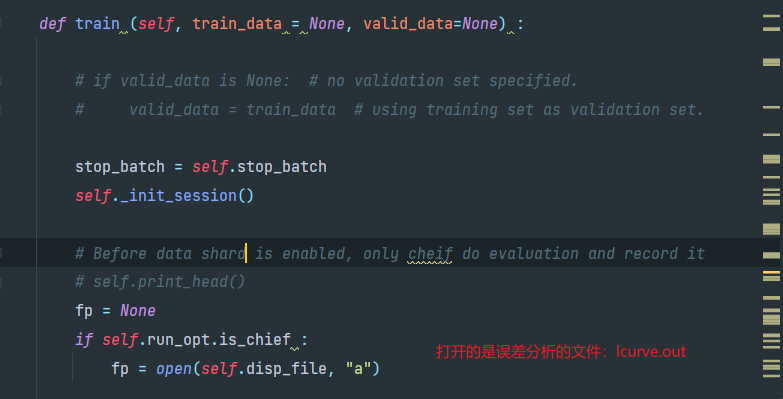
train方法首先_init_session(),
_init_session里面新建了Session,并执行了init_op(tf.global_variables_initializer())
然后run_sess两次,第一次获得全局步长,第二次确定学习率


第三次run_sess就是训练了
后面又有一次run_sess是更新cur_batch

(4)custom_op
并行训练
并行训练不需要在input.json中指定参数,根据训练过程的数量(根据MPI上下文)和可用GPU卡的数量,DeePMD-kit将决定是以并行(分布式)模式还是串行模式启动训练
1 | CUDA_VISIBLE_DEVICES=0,1,2,3 ~/openmpi/bin/mpirun -np 4 dp train input.json >train.log 2>&1 & |
用平台上自带的openmpi不行,应该是版本太老的原因,用我自己安装的openmpi(版本4.1.2)可行(太坑了,试了差不多两晚上)
在用nvprof测试速度
优化
kernel fusion
AI方面的训练加速
混合精度:自己指定哪一部分使用什么精度

DeePMD文件夹下是第一次用gpu训练,没有规定环境变量,没有开启custom op的gpu运算
deepmddata是第二次训练,开启了custom op的gpu运算
| gpu | gpu(custom op on gpu) | deepmddata2 | dev | |
|---|---|---|---|---|
| copper | 200.711 | 155.320 | 180.573 | 162.378 |
| maglcu | 358.963 | 267.503 | ||
| water | 455.878 | 237.085 | 247.641 | 217.556 |
0:gpu float64
1:custom op with gpu float64
2:mix precision 单gpu
3:dev 单gpu custom op on gpu
4:单gpu oriign
tensorflow_venv:在asc2022的基础上魔改:出bug了,尝试回退一下,只进行少量修改
tensorflow_venv_v2:直接上官方dev版本
deepmd:dev
deepmd2:ori
模型压缩:compress(与本次赛题无关)
原有的compress是训练完以后进行模型压缩,以便能在推理时减少时间而不影响精度
compressed training是为了优化训练速度,面向两种情况:训练后期的模型微调和从头开始训练
模型微调需要先标准训练冻结一个标准模型,然后模型压缩,再利用压缩好的模型开始训练
从头开始训练就是先标准训练一部分然后停止,然后开始压缩训练
混合精度优化尝试
(1)descriptor
来到descriptor目录下,descriptor.py为抽象类,我们主要关注se_a.py这个实现
descriptor下的启用混合精度都是必须开启embedding net才行,那样就修改了input.json,此路不通(按照规则应该不能使用type embedding才对)
转而查看se_a.py下的所有涉及到precision的部分,尝试能否在这里不使用全局变量而单独修改精度
se_a.py
fit/ener.py
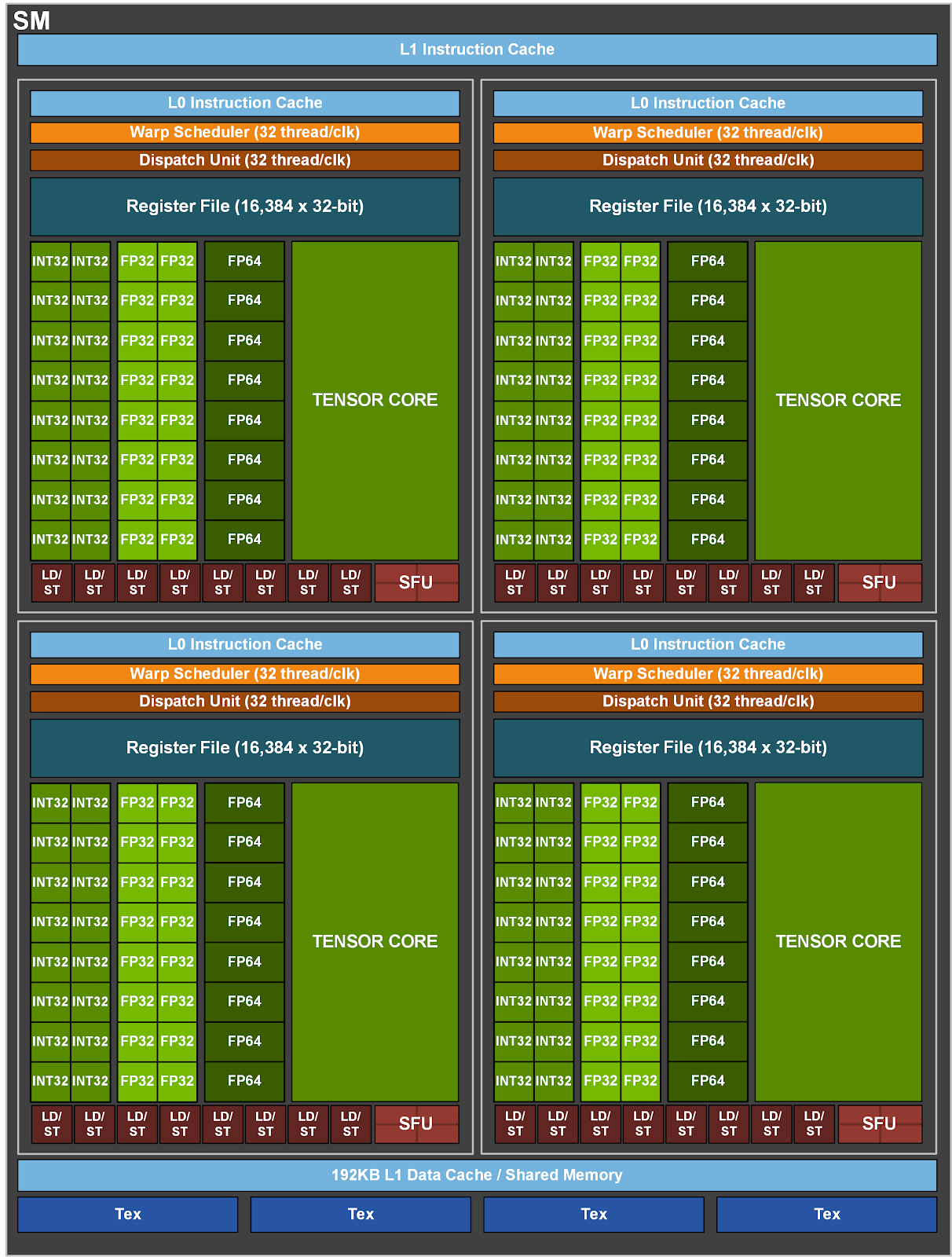
源码其实已经启用了混合精度进行优化,在下面的mixed_precision.enable_mixed_precision_graph_rewrite方法会将某些操作由单精度转为半精度,并使用tensor core进行计算
进一步优化:自己指定每一步的精度进行修改(能优化的比tensorflow自动混合精度更好吗)

1 | DP_ENABLE_MIXED_PREC=fp16 CUDA_VISIBLE_DEVICES=0,1,2,3 ~/openmpi/bin/mpirun -np 4 dp train input.json >train.log 2>&1 & |
kernel fusion
先尝试开启XLA
1 | # 配置开启即时编译 |
试试这个
1 | XLA_FLAGS=--xla_gpu_cuda_data_dir=/home/u2600489/cuda CUDA_VISIBLE_DEVICES=0,1,2,3 ~/openmpi/bin/mpirun -np 4 dp train input.json >train.log 2>&1 & |
xla不可用,就是负向优化
 wechat
wechat alipay
alipay