
optimizing_cpp(8)
八、多线程
有三种方法可以并行地执行任务:
- 使用多个 CPU 或 多 核 CPU,如本章所述。
- 使用现代 CPU 的乱序执行能力,如第9章所述。
- 使用现代 CPU 的向量操作,如第10章所述。
在决定并行处理是否有利时,区分粗粒度并行和细粒度并行非常重要。粗粒度并行是指一序列的操作可以独立于其他任务的情况(多个线程执行不同的任务)。细粒度并行是指任务被划分为许多小的子任务(多个线程共同执行一个任务),但是在与其他子任务进行必要的协调之前,不可能在特定的子任务上工作很长时间。
由于不同内核之间的通信和同步比较慢,因此粗粒度并行比使用细粒度并行效率更高。如果粒度太细,那么将任务拆分为多个线程是没有优势的。无序执行和向量操作是利用细粒度并行的更有用的方法。
在使用多线程时,需要关注缓存冲突和缓存一致性问题。
缓存冲突:多个 CPU 内核或逻辑处理器通常共享相同的缓存,至少在最后一级缓存中是这样,在某些情况下甚至共享相同的一级缓存。共享相同缓存的优点是线程之间的通信变得更快,并且线程可以共享相同的代码和只读数据。缺点是,如果线程使用不同的内存区域,缓存就会被填满,如果线程写入相同的内存区域,就会发生缓存竞争。
缓存一致性问题:如果多个线程同时写入一个缓存行,由于要保证缓存的一致性,这两个线程会多次从内存中读写数据到缓存,效率会极低甚至不如单线程。
看个栗子:
接下来,我们来看一下多核下的性能问题,参看如下的代码。两个线程在操作一个数组的两个不同的元素(无需加锁),线程循环1000万次,做加法操作。在下面的代码中,我高亮了一行,就是
p2指针,要么是p[1],或是p[30],理论上来说,无论访问哪两个数组元素,都应该是一样的执行时间。void fn (int* data) {
for(int i = 0; i < 1010241024; ++i)
*data += rand();
}
int p[32];
int *p1 = &p[0];
int *p2 = &p[1]; // int *p2 = &p[30];
thread t1(fn, p1);
thread t2(fn, p2);
然而,并不是,在我的机器上执行下来的结果是:
- 对于
p[0]和p[1]:560ms- 对于
p[0]和p[30]:104ms这是因为
p[0]和p[1]在同一条 Cache Line 上,而p[0]和p[30]则不可能在同一条Cache Line 上 ,CPU的缓存最小的更新单位是Cache Line,所以,这导致虽然两个线程在写不同的数据,但是因为这两个数据在同一条Cache Line上,就会导致缓存需要不断进在两个CPU的L1/L2中进行同步,从而导致了5倍的时间差异。接下来,我们再来看一下另外一段代码:我们想统计一下一个数组中的奇数个数,但是这个数组太大了,我们希望可以用多线程来完成这个统计。下面的代码中,我们为每一个线程传入一个 id ,然后通过这个 id 来完成对应数组段的统计任务。这样可以加快整个处理速度。
int total_size = 16 * 1024 * 1024; //数组长度
int* test_data = new test_data[total_size]; //数组
int nthread = 6; //线程数(因为我的机器是6核的)
int result[nthread]; //收集结果的数组
void thread_func (int id) {
result[id] = 0;
int chunk_size = total_size / nthread + 1;
int start = id * chunk_size;
int end = min(start + chunk_size, total_size);
for ( int i = start; i < end; ++i ) {
if (test_data[i] % 2 != 0 ) ++result[id];
}
}
然而,在执行过程中,你会发现,6个线程居然跑不过1个线程。因为根据上面的例子你知道
result[]这个数组中的数据在一个Cache Line中,所以,所有的线程都会对这个 Cache Line 进行写操作,导致所有的线程都在不断地重新同步result[]所在的 Cache Line,所以,导致 6 个线程还跑不过一个线程的结果。这叫 False Sharing。优化也很简单,使用一个线程内的变量。
void thread_func (int id) {
result[id] = 0;
int chunk_size = total_size / nthread + 1;
int start = id * chunk_size;
int end = min(start + chunk_size, total_size);
int c = 0; //使用临时变量,没有cache line的同步了
for ( int i = start; i < end; ++i ) {
if (test_data[i] % 2 != 0 ) ++c;
}
result[id] = c;
}
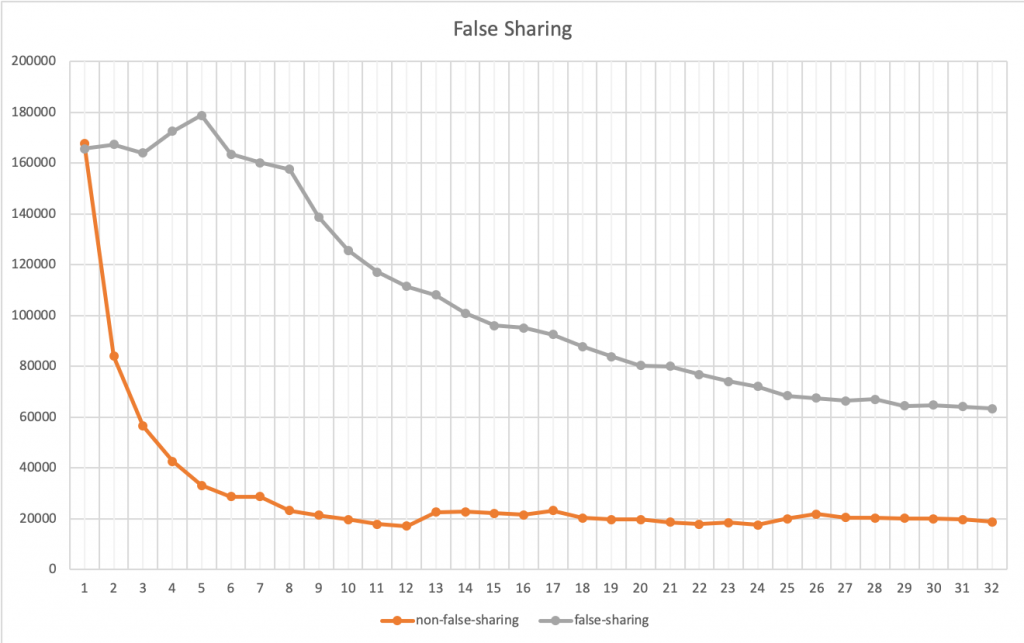
我们把两个程序分别在 1 到 32 个线程上跑一下,得出的结果画一张图如下所示(横轴是线程数,纵轴是完成统的时间,单位是微秒):
上图中,我们可以看到,灰色的曲线就是第一种方法,橙色的就是第二种(用局部变量的)方法。当只有一个线程的时候,两个方法相当,基本没有什么差别,但是在线程数增加的时候的时候,你会发现,第二种方法的性能提高的非常快。直到到达6个线程的时候,开始变得稳定(前面说过,我的CPU是6核的)。而第一种方法无论加多少线程也没有办法超过第二种方法。因为第一种方法不是CPU Cache 友好的。也就是说,第二种方法,只要我的CPU核数足够多,就可以做到线性的性能扩展,让每一个CPU核都跑起来,而第一种则不能。
来自酷壳网上的栗子)
只读的数据可以在多个线程之间共享,而可以修改的数据应该被每个线程单独存储。使数据特定于线程的最简单方法是在线程函数中声明它,使其为线程本地的,以便将其存储在堆栈中(在每个线程执行函数内部声明的临时变量)。
 wechat
wechat alipay
alipay



