PAC22-初赛
0.赛题分析
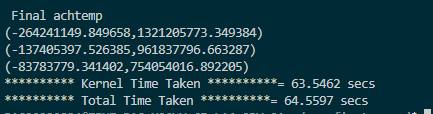
初始化和验证正确性用了一秒,核心函数用了63.5秒
通过分析,该程序为访存密集型,在GPU上可能访存成为瓶颈。
可能存在的优化方法:
编译器优化:感觉无计可施,只替换为dpcpp不变代码的话会变慢
拆分复数类,自己实现,将AOS转换为SOA
修改循环或者进行矩阵转置
GPU版本
多GPU并行
更换buffer为USM
使用MPI多进程来提高GPU利用率
负载均衡
CPUGPU协同计算
降低时间复杂度
1.重写复数库
思路:将AOS换位SOA
将复数数据其完全拆分成double数组操作,除了将将AOS换位SOA,还简化了部分中间计算。
问题:拆分复数后显著变慢。
tips:某个方向的优化遇到瓶颈最好不要死钻牛角尖,心态会很受影响,最好换个方向进行优化
原因:因为没有先改变循环的顺序,导致有些数组还是列访问,当将复数数组拆分成两个数组后,cache miss会加倍,cache冲突率也会加倍,所以时间会变慢,在修改循环顺序后保证了所有的数组都是行访问,性能就不会下降了。但是由于在拆分前已经向量化了(vtune显示向量化100%),所以拆分后没有显著的性能提升。等放到GPU上试试有没有性能提升吧
tips:做这种AOS转SOA时,要先保证访存不会出问题
最终这一步并没有明显的性能优化,所以最后提交版本并没有做复数类的拆分。
2.CPU优化
修改循环顺序、减少重复运算
修改循环顺序

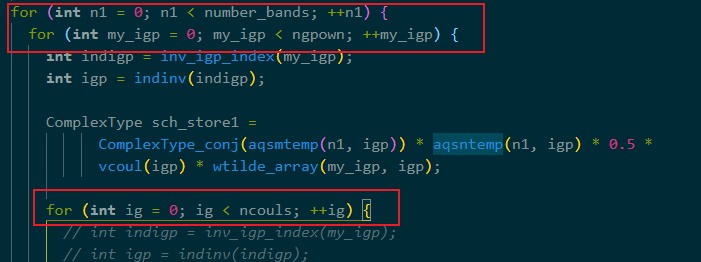
主要作用是保证了数组的行访问而不是列访问,提高访存连续性。
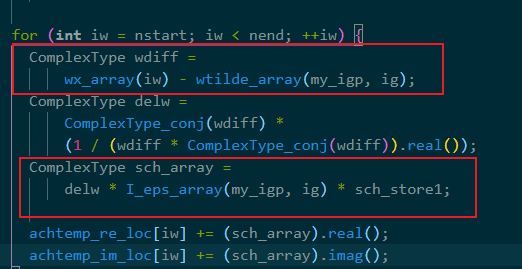
tips:遇到大循环先检查一边所有的数组访问,看看有没有列访问,然后想办法改变循环顺序使其变为行访问。
减少重复运算:
将重复的公共运算提出循环,避免时间的浪费。
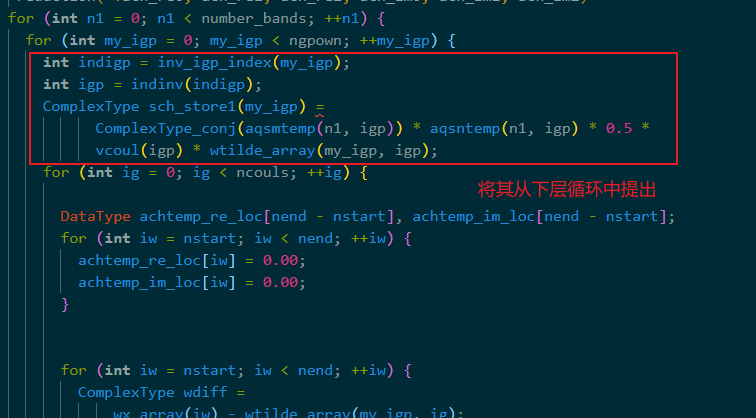
本轮优化后时间减少到6-8秒
3.GPU版本
尝试将代码移植到SYCL版本,查阅官方文档后发现有两条路,SYCL版本(DPCPP)和OpenMP offload,我们对两个版本都进行了尝试,感觉坑还是挺多的,主要是语法杂糅太容易出错了,建议仔细看下《data-parallel-c++》这本书,github上有人翻译成了中文版。
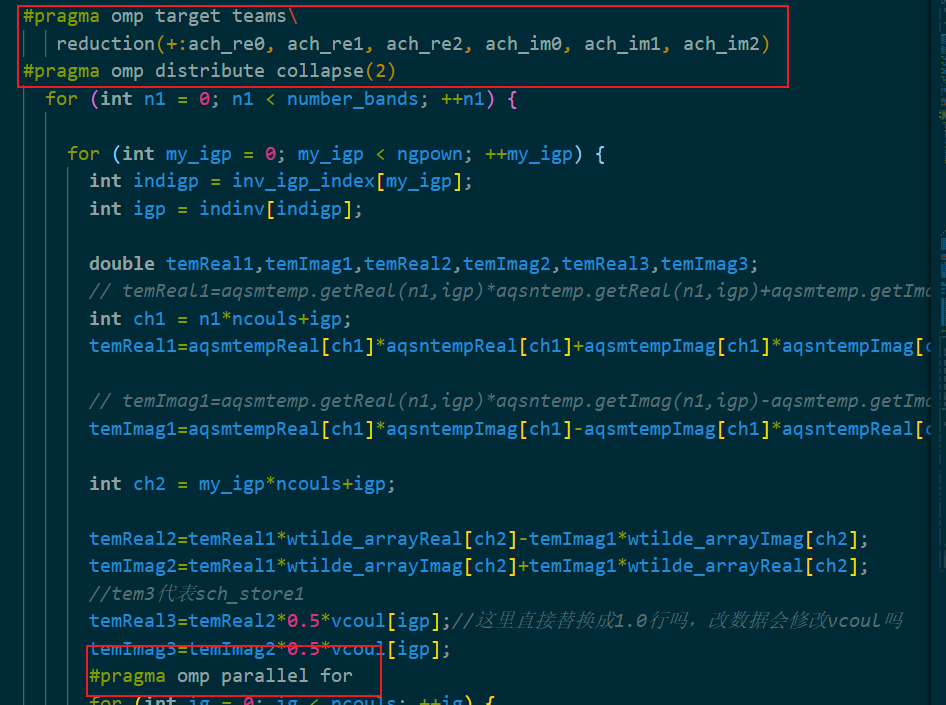
OpenMP offload版本还是比较简单的,尤其对于这种本就是openmp程序的,只需要分好teams,做一下循环展开collapse就好(不然无法offload,具体原因没找到),最终结果发现只比CPU版本快了一点点,我们的版本肯定不是最快的,但是在尝试过后我们发现openmp可操作空间相较于SYCL不是很大,于是就放弃了后续的版本开发。openmp offload主要是方便移植,想要学习除了官方文档和oneapi的devcloud外,还可以参考《oneapi-gpu-optimization-guide》这本书的openmp部分。
对于SYCL版本,我们选择nd-range来划分任务,针对本赛题的四层循环,我们最初将外面三层循环对应到nd-range的三维,后来发现三维相乘爆int了,即使使用long也会报错,后来选择将ncouls除以k,在parallel_for内部再嵌套一层循环,然后就能够跑通了。随后尝试增大k,发现速度有所提升,思考后我认为原因主要是虽然我这样写并行粒度大,但是每个EU的占用率不高,所以干脆将nd-range划分为二维,在parallel_for内部保留ncouls的一层循环。速度又有所提升。最终GPU初版优化到2.5秒左右。
4.GPU层面优化
因为平台上有两个GPU,在编写出GPU初版后,我尝试调用两个GPU共同计算,但至今没有搞懂oneapi的dpcpp和底层硬件是怎么对应的,当使用默认设备初始化queue时,只有一个设备的占用率有变化,最多到12.5%,当尝试遍历获取所有设备再指定queue的设备后,两个GPU的占用率都有变化,且最多能够到37.5%(令人费解)。anyway,我们尝试显示指定queue的device后性能又有所提升。
我们最初的版本使用的是buffer来传输数据。在尝试换成USM后性能再次提升。
本轮优化后时间来到1.5秒左右。
5.降低时间复杂度,中间结果预计算
在比赛即将截止时我们又发现了新的算法优化。我们发现只有下图中红框内的计算需要循环number_bands次,其他的计算不需要经历number_bands循环,为冗余计算。
为想办法消掉number_bands这层循环,将下图红框操作提出大循环单独计算,将number_bands层循环移到最内层,避免冗余计算
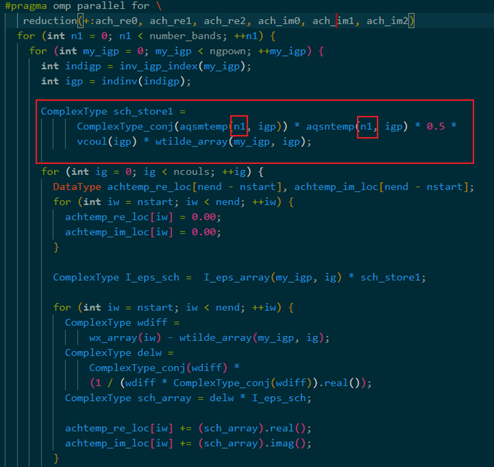
改为:
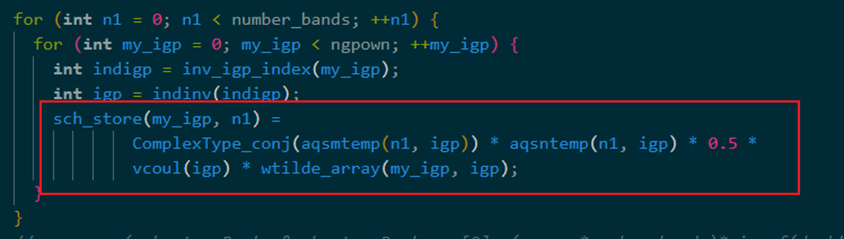
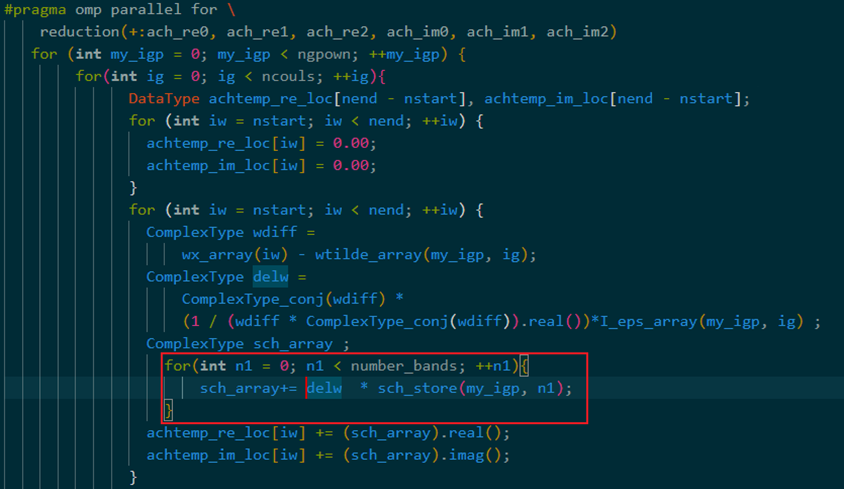
此时最内层的计算只和ngpown和number_bands这两层循环有关。将其提出大循环,减少不必要的冗余计算。 最后时间复杂度从O(ngpownncoulsnumber_bandsnend)变为O(ngpownncouls*nend)
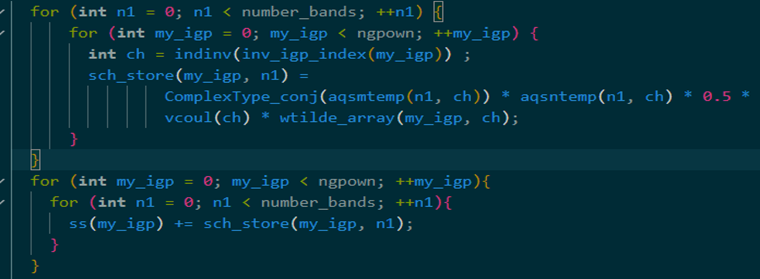
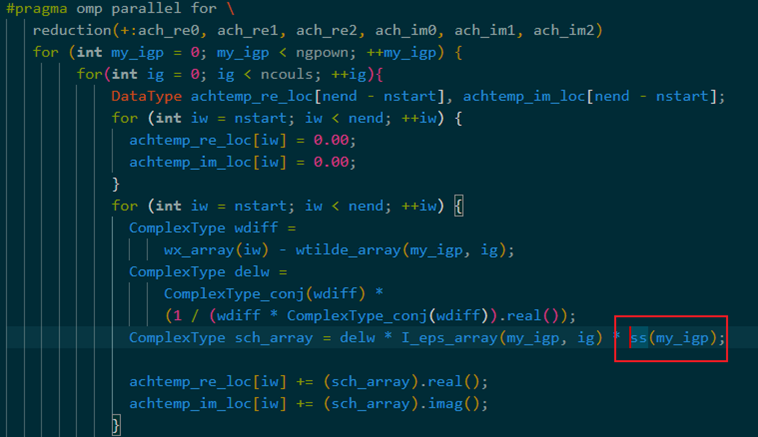
cpu只需要0.12秒左右,但是结果过不了cpu版本的check,没办法只能上CPUGPU协同版本,当优化到现在这个算法的计算已经不是瓶颈了,变成了访存密集型,放到GPU上反而会慢一些,最终提交时间0.25秒。(希望能过check)
6.编译器优化
这部分优化是提交之后学长告诉我们的,所以只是自己试了试,提交的是0.25的版本。因为dpcpp为了保证兼容性,采用即时编译(JIT),可以通过提前编译(AOT)来避免JIT,需要在编译时指定在哪种设备上执行,编译参数如下:
1 | dpcpp -O3 -qopenmp -fsycl-targets=spir64_gen -Xsycl-target-backend=spir64_gen "-device 0x020a" maicpp -o main.exe |
优化效果十分显著,添加参数后时间可以来到0.12秒左右,在我们之前的版本上效果更加显著,因为之前的版本是纯GPU计算,时间可以从0.8秒降低到0.4秒左右!
7.总结
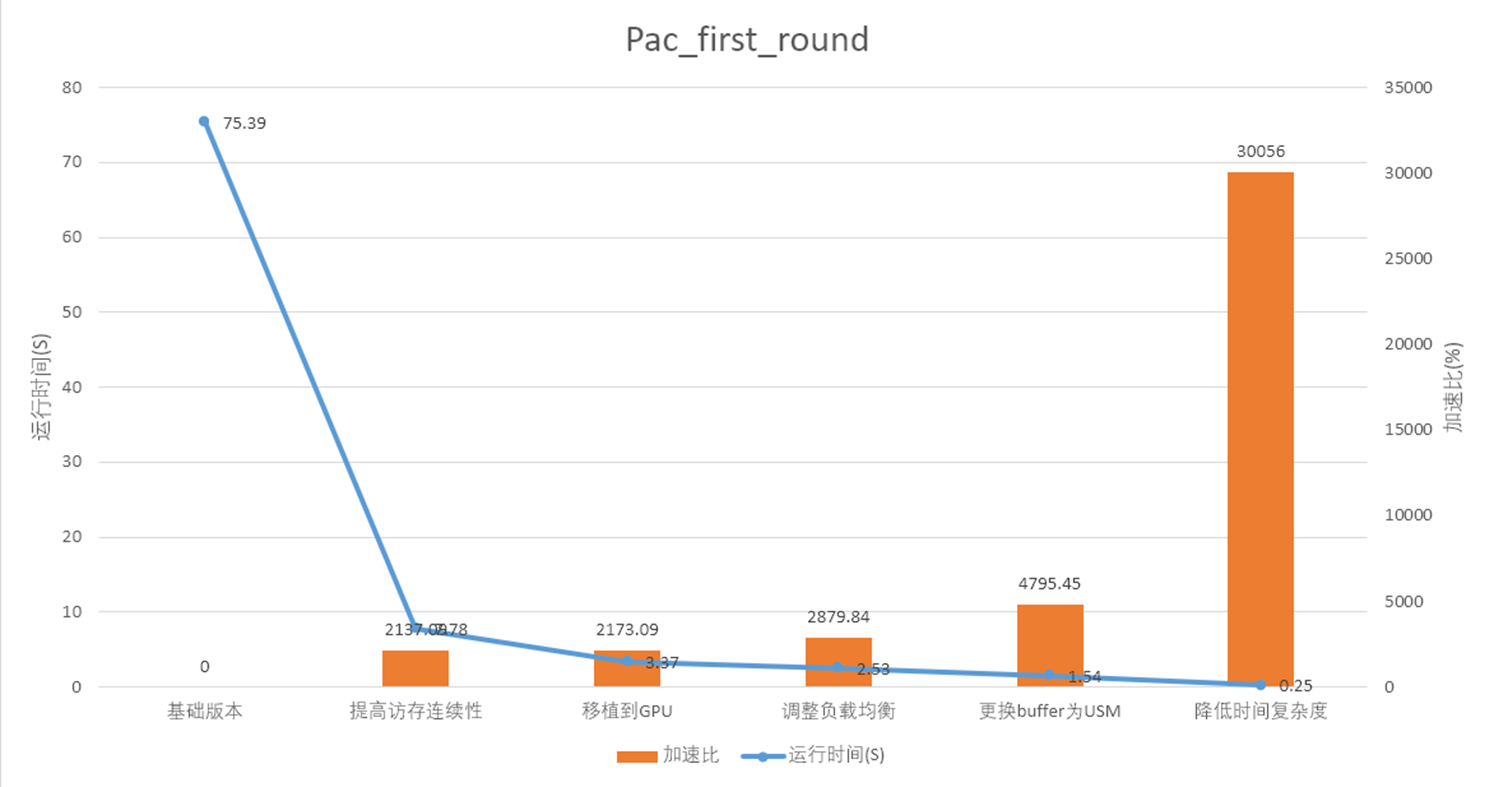
加速比如图所示。
说句题外话
未解之谜:至今不知道英特尔的GPU底层是怎么映射的,我们最开始使用的是遍历得到的device,两个GPUcompute率都可以飙到37.5%,最快能到0.7秒,但是及其不稳定,波动到3秒都有可能。后来使用默认构造函数构造queue,时间稳定在0.85秒左右。但是当我这样写时:
1 | queue q[7]; |
使用q1时两个GPUcompute都飙到37.5%,太奇怪了,不知道底层怎么编写的。
 wechat
wechat alipay
alipay