Rocm
ROCm——open software platform for accelerated computing
- 拥有完善的库、工具和管理API
- 拥有开源的OpenMP和HIP编译器
- 规模从工作站到云到百万兆级计算
- 完善的生态系统
HIP:c++运行时api,支持AMD和nvidaGPU
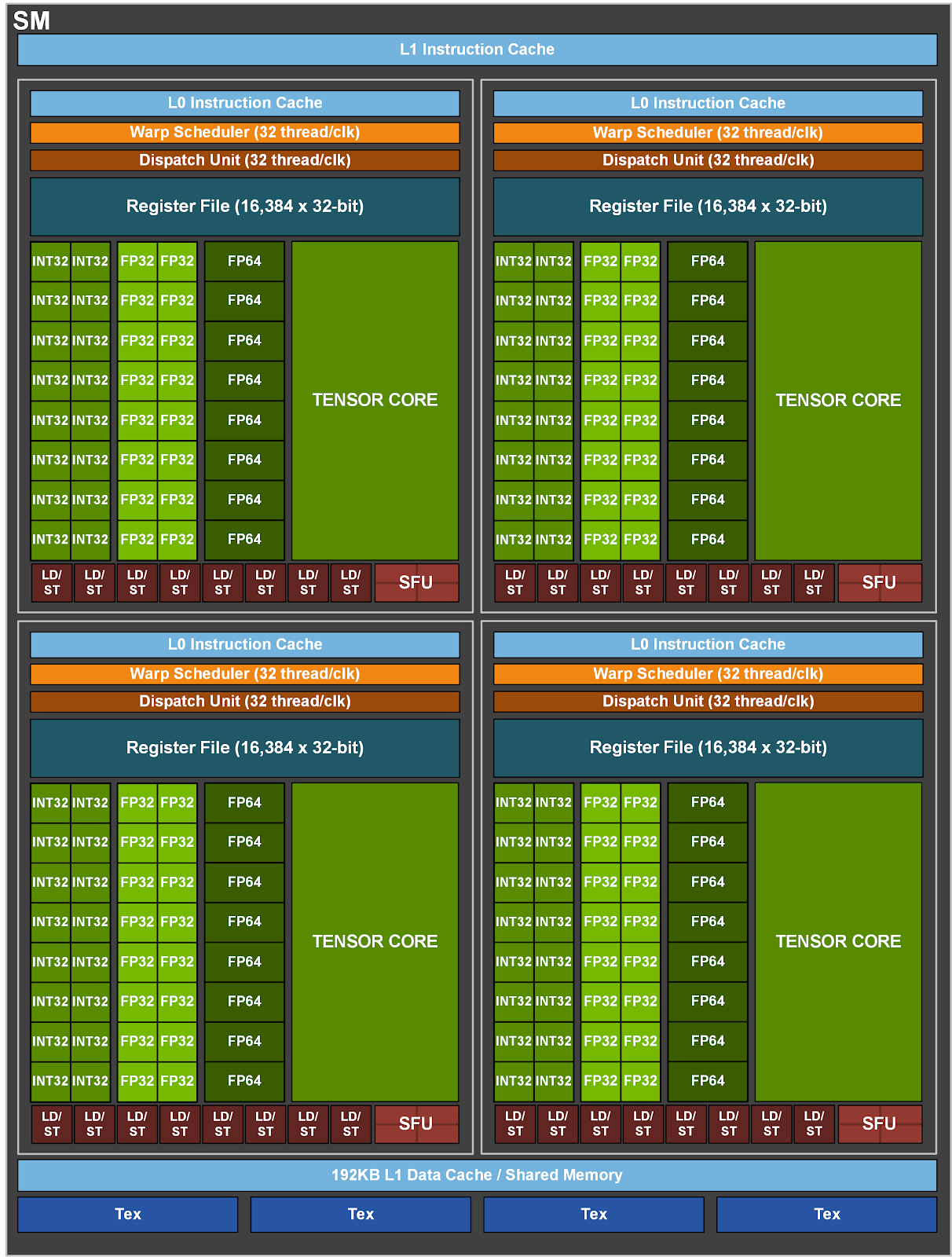
AMD硬件架构
GCN 硬件概述
AMD GPU由一个或多个着色器引擎(SE)以及一个命令处理器组成,着色器引擎内又有负载管理器和计算单元(CU)。
命令处理器从命令队列中读取命令,提交给工作负载管理器,然后工作负载管理器将任务分配给计算单元。

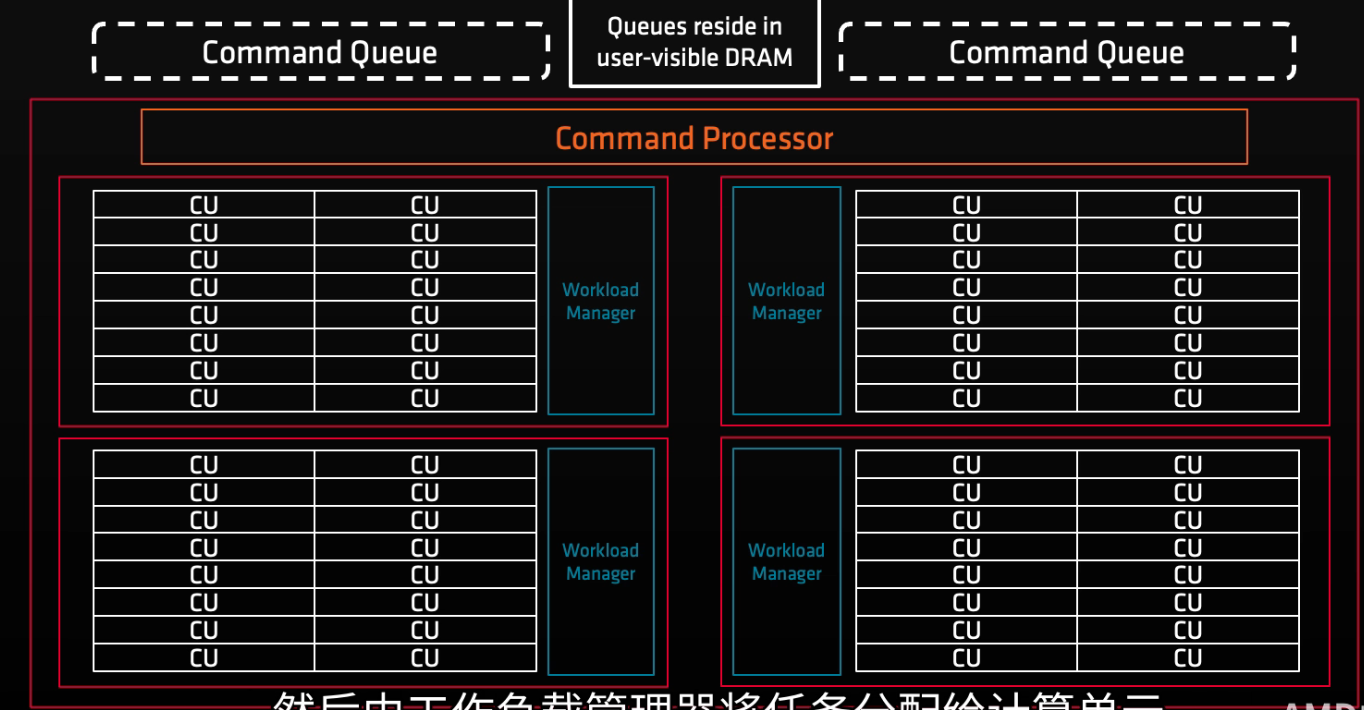
以下部分AMD设备的SE、CUs/SE数量

workgroup–block
workitem–thread
wavefont–warp
amd硬件允许每个workgroup最多有16个wavefont
将硬件和抽象对应起来,AMD GPU的调度方式如下:
命令处理器从命令队列中获取kernel,创建workgroup,然后将其分发到SE,SE上的工作负载管理器为workgroup创建wavefont,并将其发送到CU。与cuda相同,一个workgroup对应一个SE,workgroup的所有wavefont都在一个SE上。
GPU memory and IO

如何工作?
- GPU向命令队列提交DMA传输块,这个过程无需操作系统级的内核调用,只需要用户级别的内存写入
- 命令处理器(CP)解析请求
- CP将其提交给DMA引擎(这部分操作与计算单元计算及其他传输过程同时进行)
- DMA引擎负责系统内存到HBM或者是设备之间的双向传输(传输在进程的虚拟内存空间中进行)
GCN 计算单元(CU)内部结构
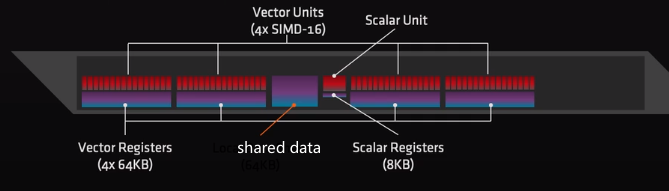
在每个CU内部有一个标量单元和8KB的标量通用寄存器(sGPR)
- 被波前所有线程共享
- 用于流控制以及指针计算等
- 有自己的通用寄存器池(GPR pool)和标量数据缓存
每个计算单元有四个矢量单元(16通道SIMD),一个CU的吞吐量:64个单精度操作/每个时钟周期。有4*64KB的项链寄存器(vGPR)。
每个矢量单元有:
- 一个16通道的IEEE754(浮点数)向量ALU
- 一个64KB的向量寄存器——四个矢量单元总共256个寄存器,每个寄存器有64个4字节宽的条目(如果如果需要8字节的浮点数计算,使用寄存器对即可)
每个矢量单元有一个用于10个波前的指令缓冲器,每个计算单元可同时启用40个波前
最后,每个计算单元都有相应的局部数据共享(LDS)
- 有32个bank,附带冲突解决方案
- 可以用于同一个工作组中所有线程的数据共享
下面是一张nvdia到AMD的术语对照表

AMD GPU编程概念和HIP
什么是HIP
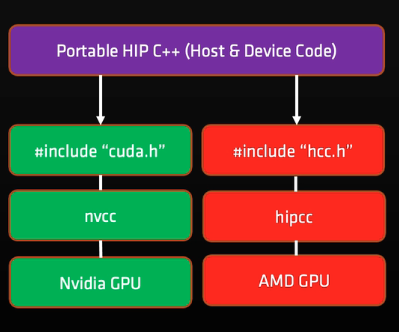
HIP是(Heterogeneous-compute interface for protability)的首字母缩写,是C++运行时API和内核语言,开发者可以创建可移植应用,这些应用可以运行在AMD和CUDA设备
- 完全开源
- 为应用程序提供一套API,利用AMD和CUDA设备进行GPU加速
- 语法类似CUDA,大多数CUDA的API可以直接转换:cuda->hip
- 支持cuda运行时功能的最强子集,大多数情况下可以支持CUDA API所提供的功能
HOST和DEVICE

什么是host device
kernel,memory,host代码的结构
grid:just like cuda
block thread:

2D blcok thread

kernel

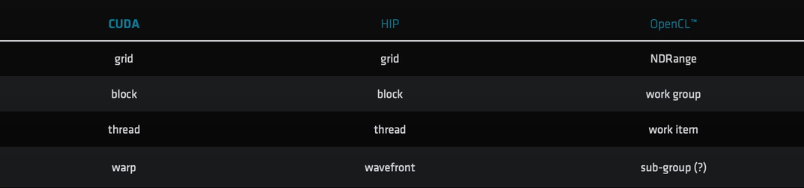
如何启动
SIMD
内核到硬件的自然映射:
- 块被动态地调度到CUs上
- 一个块中的所有线程都在同一个CU上执行
- 块中的线程共享LDS内存和L1缓存
- 块中的线程以64宽的块(称为“wavefont”)执行。
- wavefont在SIMD单元上执行
- 如果一个wavefont停滞(例如数据依赖),CUs可以快速切换到另一个wavefont
一个好的做法是使块大小为64的倍数,并且有多个wavefont(例如256个线程)
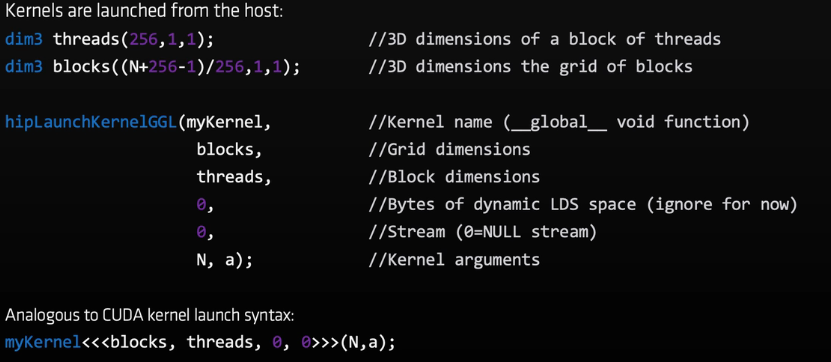
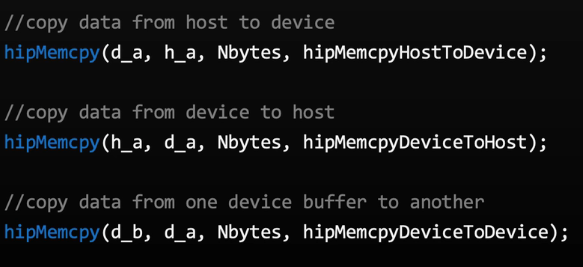
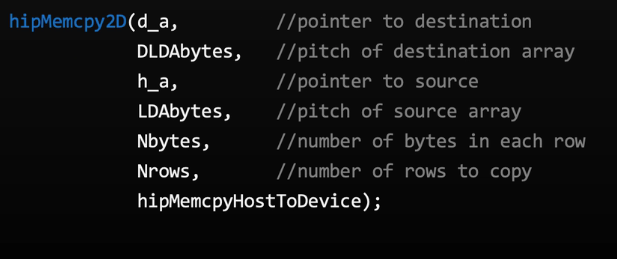
device memory

错误检查(非常有用)
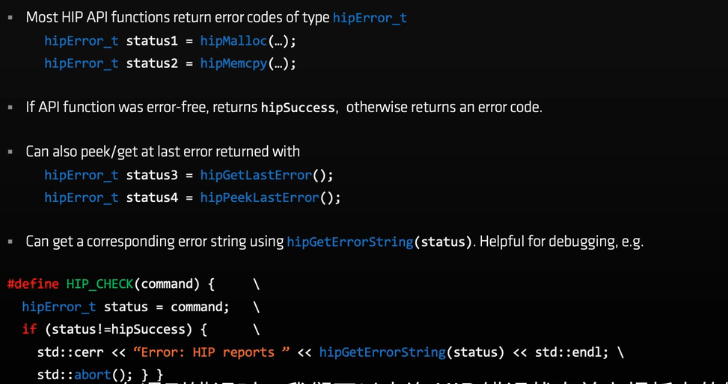
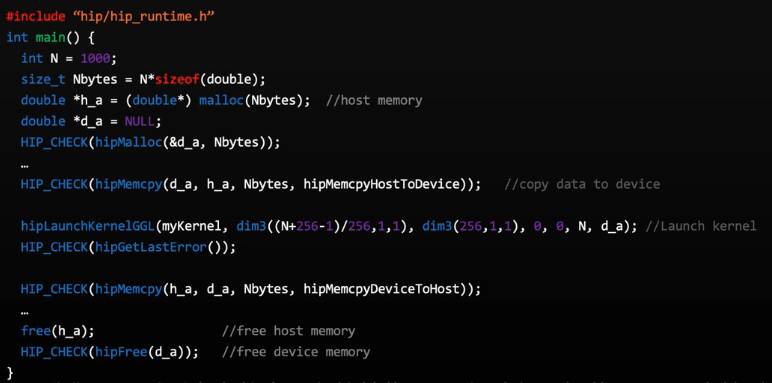
完整实例
设备管理,同步和MPI
多GPU?多个host线程?多个MPIranks?
获取设备数量,指定设备,查询设备信息
host可以通过交换当前选中的设备来管理多个设备。
MPIranks可以设置不同的设备或者设置多个ranks,通过over-subscribe向单个设备发出命令。
查询设备属性。hip_runtime_api.h
阻塞调用及非阻塞调用
hipLaunchKernelGGL是一种对主机的非阻塞调用,异步
hipMemcpy是阻塞操作,hipMemcpyAsync非阻塞
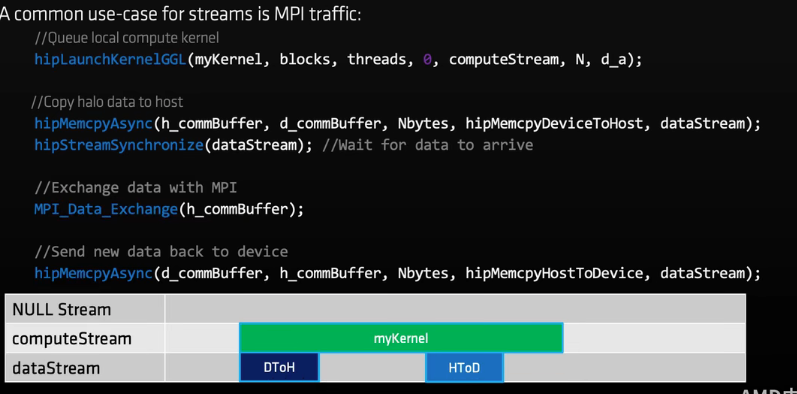
STREAM
流相当于任务队列,一系列类似内核函数、memcpy或者事件的集合,流中的任务会按顺序执行。
不同流中的任务可以叠加使用和划分设备资源
创建和销毁:
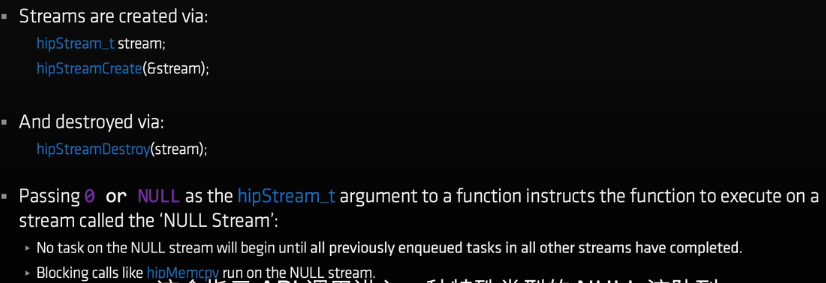
如果传入0或者NULL作为hipStream_t参数表示这个函数在NULL STREAM上执行
- 直到其他流中先进入队列的任务完成后NULL流上的任务才会开始
- 像
hipMemcpy这样的隐式阻塞始终运行在NULL流上
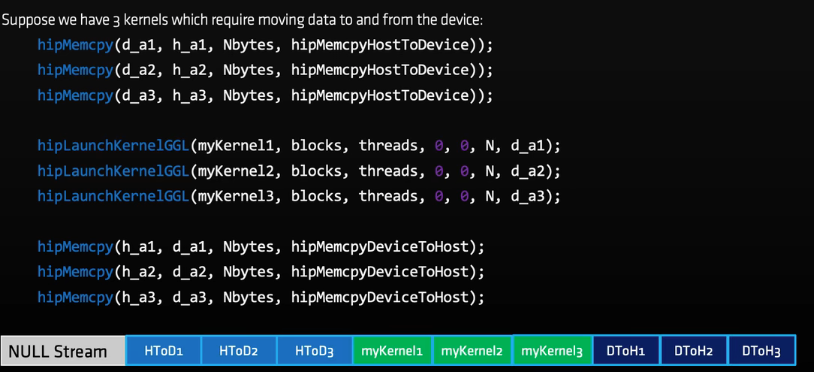
为什么要使用流:内核间并行(当然是可并行时,如果一个kernel占用全部的资源,使用流仍然无法并行)

特别要说明的,以下三种操作有独立的引擎,可以重叠执行
- host->device
- device->host
- kernel
这三种操作重叠执行的前提:
- 重叠操作应该在单独的、非NULL流中
- host memory应该是固定的(pinned)
pinned memory
默认情况下主机内存是分页的,GPU可以直接访问host数据如果已经固定(不会报缺页异常)

如果hostmemory 固定,memcpy的带宽也会增大。因此,如果频繁的在h d之间传输数据,推荐在固定区域分配主机内存。
经典应用:
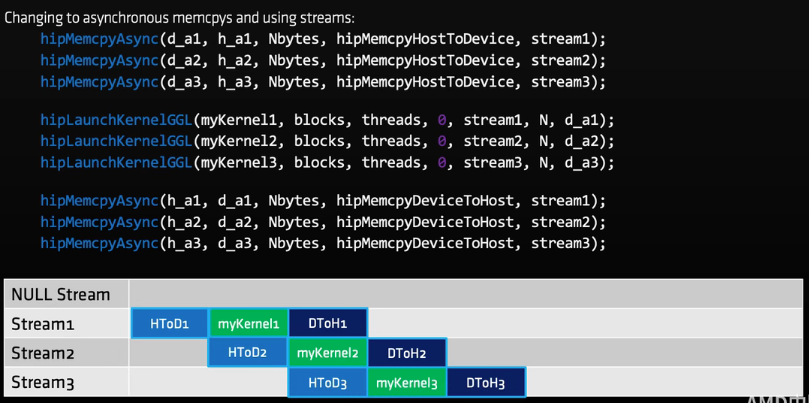
同步
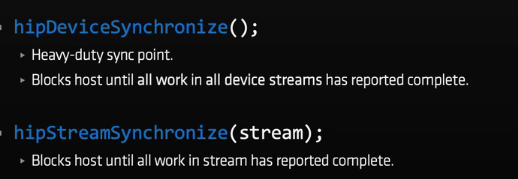
主机与设备之间的两种同步
流之间的同步:事件event
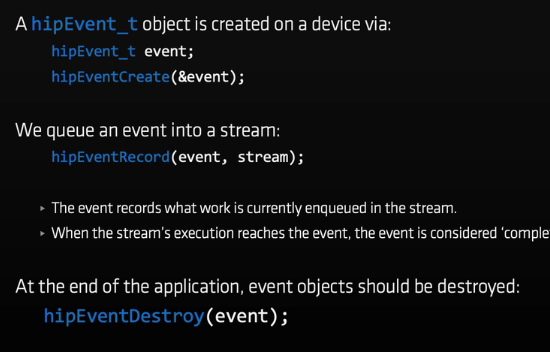
event
创建、绑定、销毁
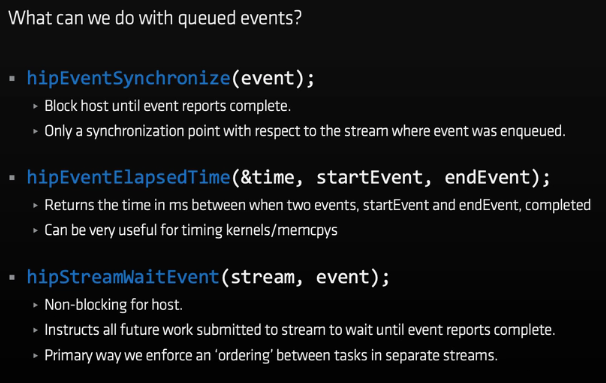
主机与事件的同步、记录两个事件之间的时间、在某个事件完成前阻塞某个流
使用流的一个例子
共享内存和线程同步
函数限定符
hipcc对源码进行两次编译,一次编译host代码,一次编译device代码

避免线程分散(thread divergence)
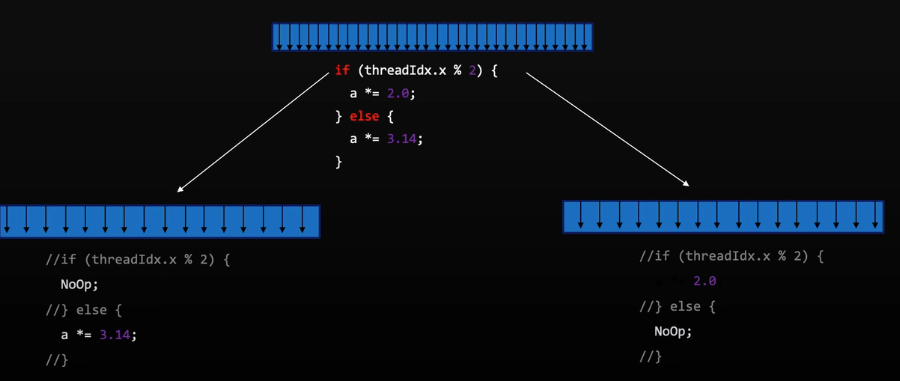
同一个wavefont内出现线程分散对性能有很重要的影响
设备代码上的内存声明
- malloc/free在device代码上不被支持
- 变量或数组可以在栈上声明
- 在设备代码声明的栈变量被分配到寄存器上,并且是每个线程的私有变量
- 线程可以通过设备指针访问公有内存,但是不共享内存,唯一的例外是将内存声明为
__shared__
在栈上声明为__shared__的变量在LDS和共享内存的每个块上分配一次,他们被同一个块中的线程共享。访问共享内存要访问设备内存和全局内存更快,比寄存器慢。
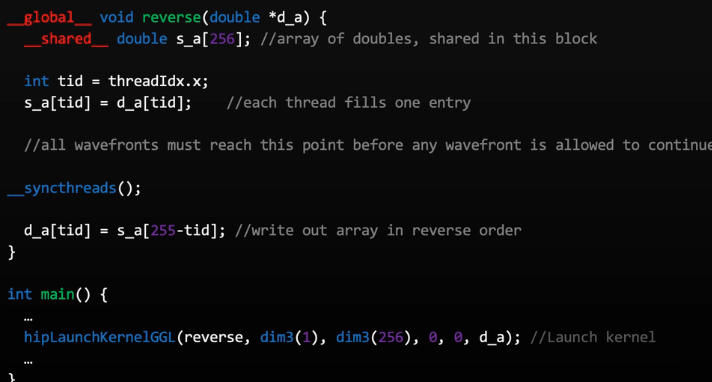
__syncthreadswavefont之间同步,阻塞wavefont直到所有的wavefont都到达这里。
最佳实践:用于避免死锁
注意:
- 如果一个wavefont中的一个线程遇到
__syncthreads,视作整个wavefont遇到__syncthreads - wavefont可能回遇到不同的
__syncthreads指令,如果其中一个wavefont退出了(exit或者执行完成内核),其他在等待__syncthreads的wavefont可以继续执行。
动态共享内存
编译器、库、工具
编译器:hipcc aomp(openmp)
hipcc调用hcc,hcc是clang的派生,因此可以在hipcc中使用熟悉的clang选项和标志



 wechat
wechat alipay
alipay