Kokkos编程指南
KOKKOS编程指南
1.简介
相比于其他并行编程模型的特点:可移植性
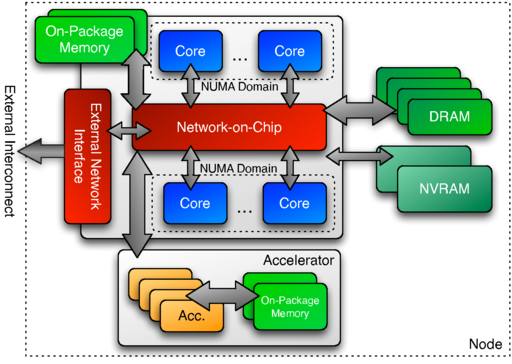
2.machine model
为了实现跨架构的可移植性,并保证性能,kokkos有两个重要组件
- 内存空间:可以在其中分配数据结构
- 执行空间:使用一个或多个内存空间的暑假执行并行操作
kokkos抽象机器模型
执行空间
执行空间用来描述一组并行执行资源,不同的执行空间可以队形不同的计算资源,例如多核CPU、GPU、加速器。Kokkos 模型抽象了为不同执行空间编译代码和将内核调度到实例的方法。这使得应用程序程序员无需使用特定于硬件的语言编写算法。
内存空间
计算节点中多种类型的内存由kokkos通过内存空间抽象。
内存空间的实例为程序员提供了一种请求数据存储分配的具体方法,可以用多个内存空间对应不同种类的内存。
原子访问:对于race conditions,可以使用锁, critical regions, 原子操作来避免。
kokkos中的内存一致性问题:kokkos中 内存一致性极弱,程序员应当显示编程保证内存操作的顺序正确,kokkos提供了fence来达到这一点。
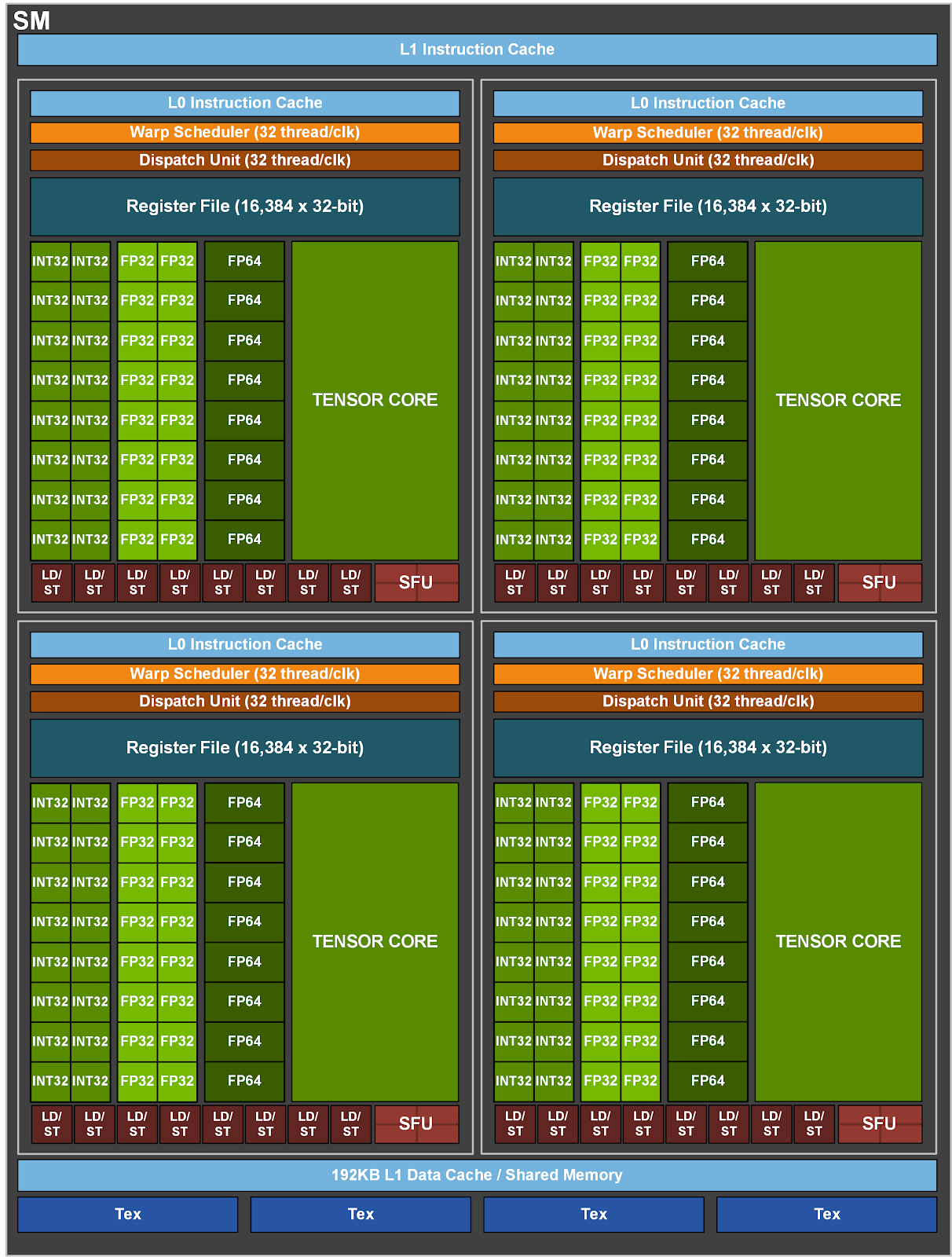
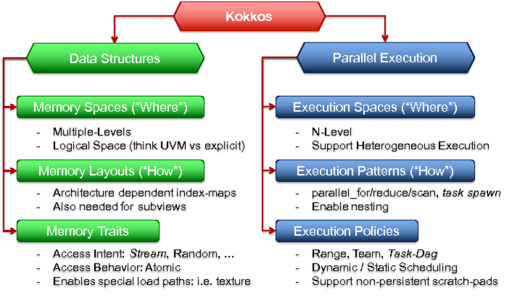
3.编程模型
kokkos编程模型6个核心抽象:执行空间,执行模式,执行策略,内存空间,内存布局,内存特征
3.1 执行空间
包括CPU内核GPU内核,甚至存内计算以及一个异构CPU上的不同内核类型
3.2 执行模式
parallel_for():以不确定的顺序执行一个函数指定的次数,parallel_reduce():将执行与归约操作相结合,parallel_for()parallel_scan():将操作与每个操作的输出值的前缀或后缀扫描相结合,以及parallel_for()task:执行依赖于其他函数的单个函数。
3.3 执行策略
3.3.1 range policies
range对该范围的每个元素执行一次操作,没有执行顺序或并发的规定
3.3.2 team policies
用于实现分层并行性(多层并行),为此,kokkos将线程分组到teams,称为thread team线程组。
team中的线程可以通过barrier进行同步,并共享一个可用于临时存储的暂存器内存。
暂存盘scratch pad memory与cuda中共享内存对应。league/team来源于openmp。
3.4 内存空间
指定数据的物理位置以及某些访问特性。不同的逻辑内存空间允许cuda编程中的UVM内存等概念
3.5 内存布局
布局表示从逻辑索引到数据分配地址偏移量的映射,通过该神布局可以优化给定算法中数据访问模式。如果实现提供多态布局(即数据结构可以在编译或运行时使用不同的布局实例化),则可以执行依赖于体系结构的优化。
3.6 内存特征
内存特征指定如何在算法中访问数据结构。特征表示使用场景,例如原子访问、随机访问和流加载或存储。通过将这些属性放在数据结构上,编程模型的实现可以插入最佳加载和存储操作。如果编译器实现了编程模型,它可以推理访问模式并使用它来通知代码转换。
4.编译
略过
5.初始化
1 |
|
6.view
6.1 创建和使用view
每个view在编译时决定将数据存储在哪个内存空间中。
view中有betadata和data两个概念,metadata存储数据地址和其他的属性,data存数据,metadata在hostmemoryspace中,所以我们在host可以知道view的属性,data在view的内存空间中,如下图所示。
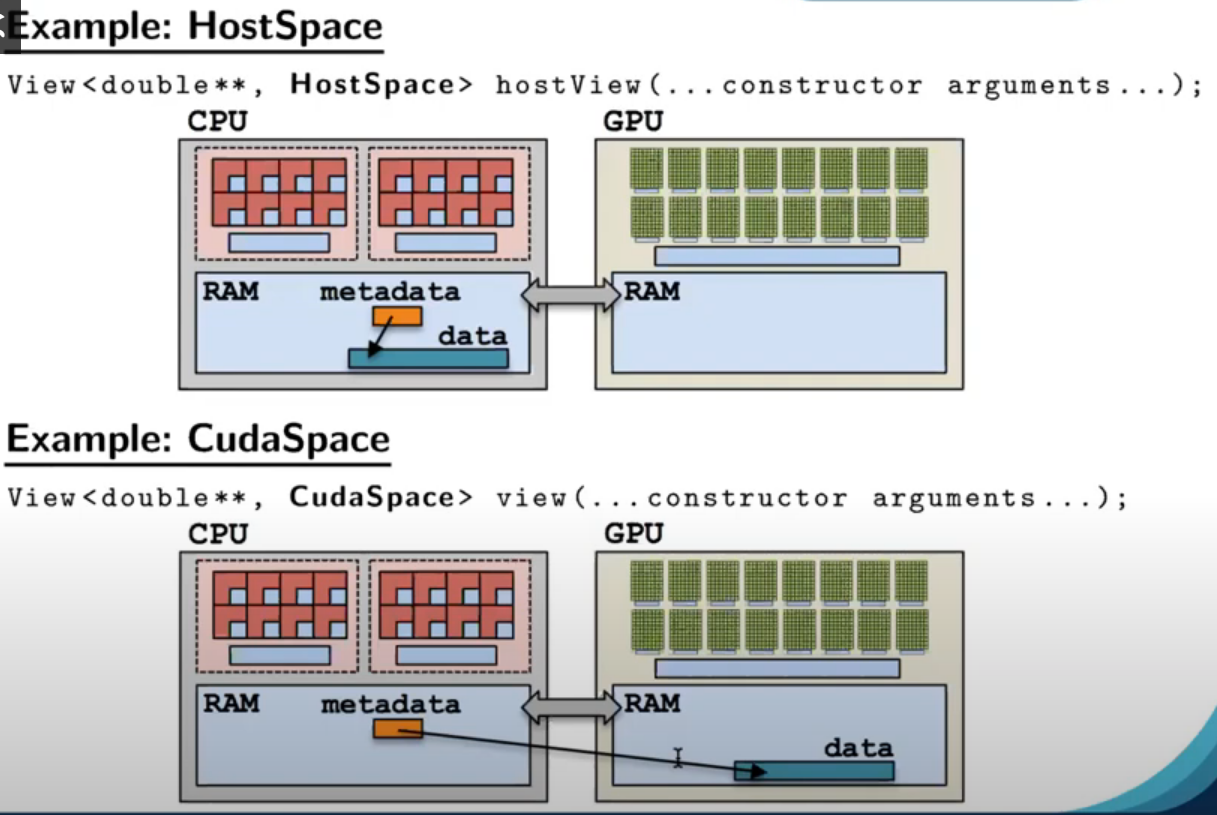
上图view的内存空间是cudaspace,创建后metadata和data如图所示,当view在parallel中被访问时,变为下图
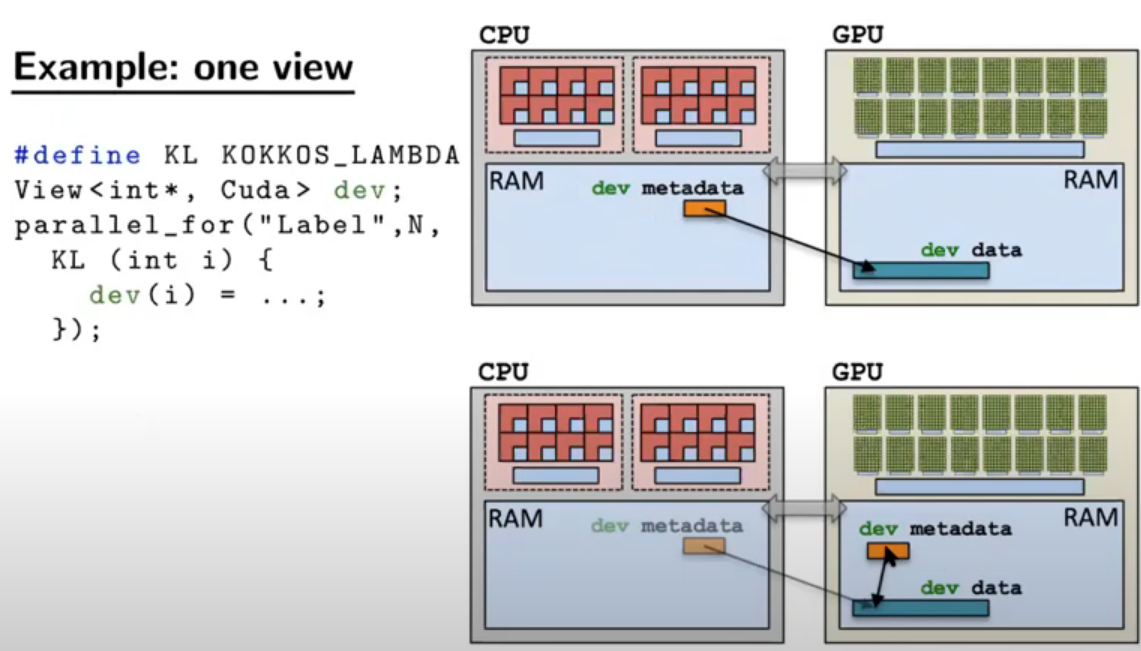
metadata复制到cudamemory中,所以GPU可以访问view的属性
再举一个例子,如下图所示,在parallel中访问host的属性可以成功,但是访问host的数据将会失败
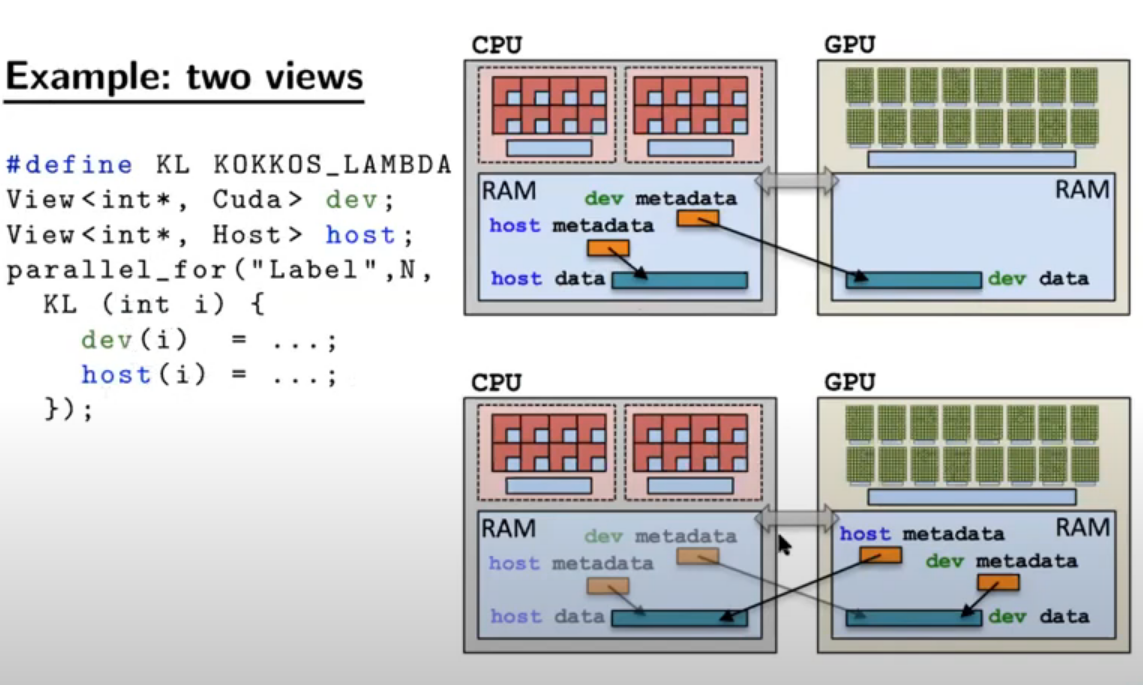
6.1.1 建造view
view使用数组的维数代表view数据的维数,各个维度的大小可以在运行时确定,也可以在编译期确定
1 | //运行时确定 |
view最多可以有8个维度,运行时维度(如果有)应当在编译时维度的前面
6.1.2 访问条目
可以使用括号来访问view的条目
1 | const size_t N = ...; |
通常,只能在允许访问该view的执行空间中访问该view的条目
6.1.3 自动释放
view通过引用计数机制自动管理view的释放
6.1.4 调整大小
可以使用非成员函数resize来调整kokkos view的大小
1 | // Allocate a view with 100x50x4 elements |
6.2 布局
6.2.1 strides and dimensions
布局是指从多维索引(i,j,k)到物理内存偏移量的映射。布局有行主序(layoutLeft)列主序(layoutRight),它们可以共同由strided描述,对于跨步布局,每个维度都有一个步幅。该维度的步长决定了两个数组条目在内存中相距多远,其在该维度中的索引仅相差一个,而其其他索引都相同。例如,对于步幅为 (s_1, s_2, s_3) 的 3-D 步幅视图,条目 (i, j, k) 和 (i, j+1, k) 在内存中是 s_2 个条目(不是字节)。 Kokkos 称之为 LayoutStride。
strieds可能与维度不同,因为kokkos可以保存缓存或者向量对齐。可以使用extent函数访问view的维度。可以通过stride函数访问步幅
1 | const size_t N0 = ...; |
6.2.2 默认布局取决于执行空间
kokkos根据其执行空间选择view的默认布局,例如:
1 | View<int**, Cuda>LayoutLeft; |
原理:CPU的GPU都使用一个线程计算一行,CPU中顺序访存,所以layout-right行主序
GPU中每个线程计算一行,但是一个warp中的32个线程计算的是同列的元素,由于合并访存的存在,最好这同列的元素是连续存储的。所以layout-left行主序
6.2.3 明确指定布局
如果想给BLAS LAPACK一个视图,可以将布局指定为视图的模板参数
1 | const size_t N0 = ...; |
6.3 管理数据放置
6.3.1 内存空间
view分配在内存空间中,默认会被分配在默认执行空间的默认内存空间。也可以将内存空间明确指定为模板参数,例如
1 | //分配在cudaspace |
kokkos的执行空间和内存空间没有双射关系,kokkos提供了一种方法来显示的将两个view提供给device
1 | Kokkos::View<int*, Kokkos::Device<Kokkos::Cuda,Kokkos::CudaUVMSpace> > a ("a", 100000); |
在这种情况下,ab在相同的内存空间下,但是a在GPU上初始化,b在host上初始化。
理解view的可访问性只取决于内存空间与执行空间无关是非常重要的,上面的a和b有相同的访问属性,不同的是它们怎样初始化以及怎样resize、深拷贝这种与执行空间相关的操作。
6.3.2 深拷贝和hostMirror
将数据从一个视图复制到另一个视图,特别是在不同内存空间的视图之间,称为深复制。 Kokkos 从不执行隐藏的深层复制。为此,用户必须调用该函数。例如:deep_copy
1 | Kokkos::View<int*> a ("a", 10); |
深拷贝只能在具有相同内存布局和填充的视图之间执行。例如以下两个操作是无效的:
1 | Kokkos::View<int*[3], Kokkos::CudaSpace> a ("a", 10); |
第一个不起作用,因为 CudaSpace 和 HostSpace 的默认布局不同。编译器会捕捉到这一点,因为不存在将视图从一个布局复制到另一个布局的 deep_copy 函数的重载。如果两个内存空间的填充设置不同,第二种情况将在运行时失败。这将导致不同的分配大小,从而阻止直接内存复制.
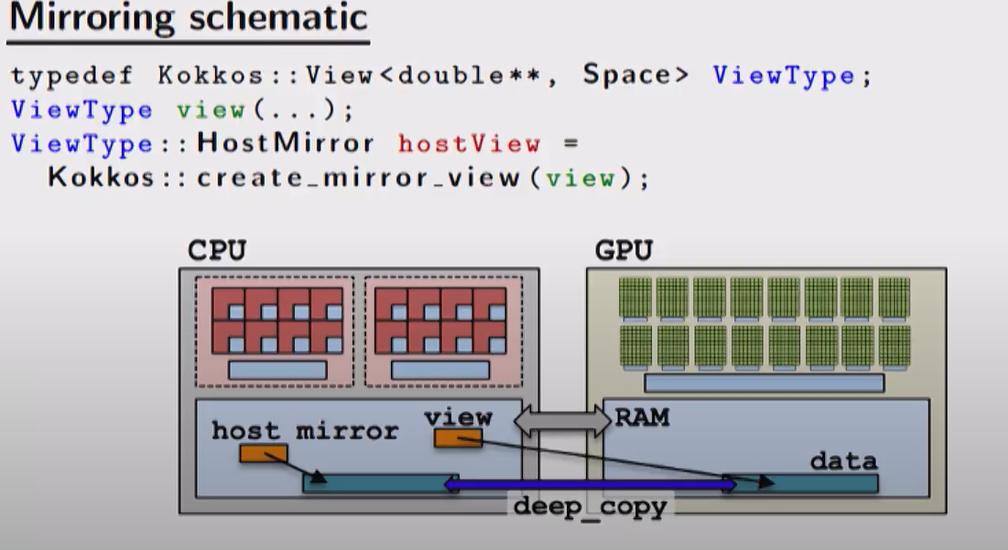
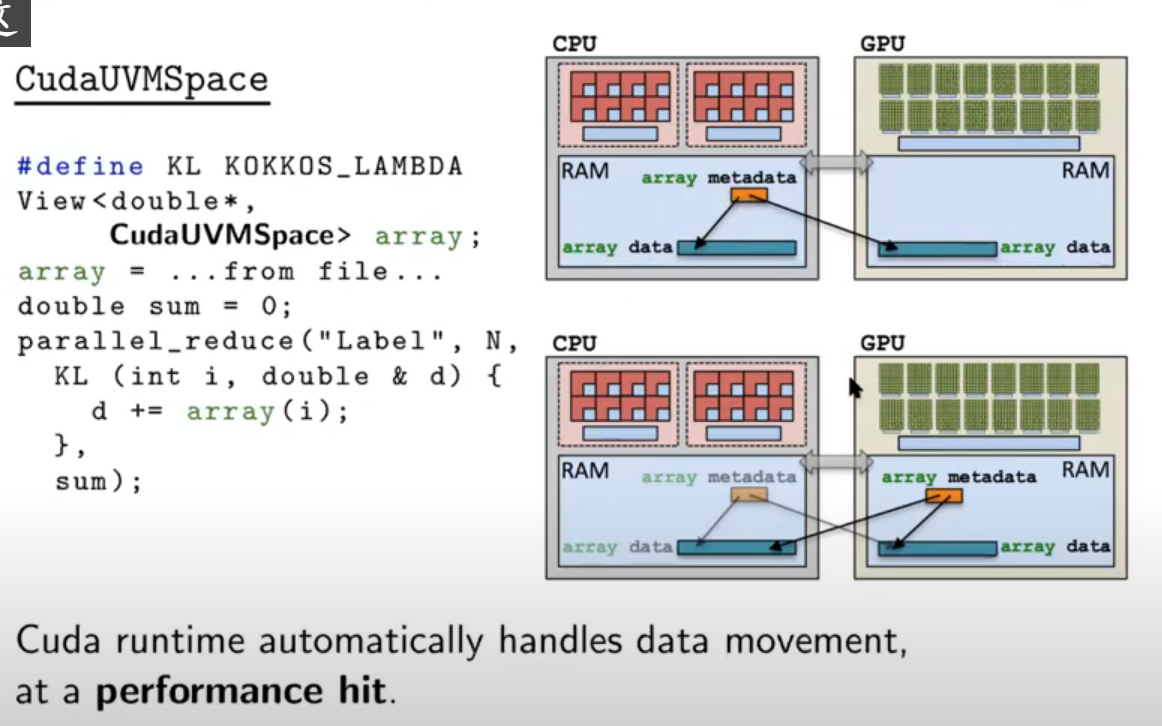
要解决深浅拷贝的问题,要么使用CudaUVMSpace,要么使用mirror
如何使用CudaUVMSpace:可能会有性能问题
如何使用mirror(显 式内存拷贝)
- 在某个内存空间创建view
- 创建这个view的镜像hostView在host memory space
- 在host上填充hostView
- 将hostView深拷贝到view中
Kokkos::deep_copy(view,hostView) - 启动kernel处理view
- 如果需要的话,将view深拷贝回hostView
需要注意的是当view在hostSpcace时,create_mirror_view只有在无法访问view的数据时才会分配数据,否则只会引用数据,而create_mirror总会分配数据。
mirror的layout与device上的数据相同,这意味着host上的mirror可能不会有很好的性能,但是做IO这种工作是没问题的。
记住:kokkos绝对 不会隐式的执行深拷贝
6.4 访问特性
访问特征是通过一个可选的模板参数来指定的,该参数在参数列表中排在最后。多个特征可以与二元“|”运算符组合
1 | Kokkos::View<double*, Kokkos::MemoryTraits<SomeTrait> > a; |
6.5 非托管视图
让 Kokkos 控制内存分配总是更好,但有时您别无选择。例如,您可能必须使用返回原始指针的应用程序或接口。 Kokkos 允许您将原始指针包装在非托管视图中。 “非托管”意味着 Kokkos 不对这些视图进行引用计数或自动释放。以下示例显示如何创建主机内存的非托管视图。您也可以为 CUDA 设备内存执行此操作,或者实际上为分配在任何内存空间中的内存执行此操作,方法是相应地指定视图的执行或内存空间。
1 | // Sometimes other code gives you a raw pointer, ... |
7.并行
kokkos三种并行操作
两种循环主题 :functors 和lambdas,必须使用KOKKOS_INLINE_FUNCTION标记functors,使用KOKKOS_LAMBDA标记lambda
7.1 指定并行循环体
7.1.1 functors
仿函数,必须是const,并且由KOKKOS_INLINE_FUNCTION修饰
7.1.2 lambda
建议使用按值捕获[=](){}
7.1.3 指定执行空间
如果一个functor有execution_spacepublic typedef ,parallel时这个functor只会在这个执行空间上执行,如果没有,将会在默认执行空间执行。lambda没有typedef,所以除非指定,否则只会运行在默认执行空间
7.2 parallel for
1 | template<class ExecPolicy, class FunctorType> |
ExecPolicy可以为简单的数字,这时的执行空间为默认的执行空间,也可以指定执行空间和其他执行策略。
kokkos必须保证代码中使用的执行空间在编译时启动(enabled)
7.3 parallel reduce
使用reduce时,functor必须定义using value_type=int;
1 | struct squaresum { |
lambda
1 | Kokkos::parallel_reduce(n, KOKKOS_LAMBDA(const int i, int& lsum) { lsum += i * i; }, sum); |
8.层次并行
8.1 现代高性能计算机并行层次
CPU集群
- CPU SOCKET共享对相同内存和网络资源访问
- socket内的内核有共享的末级缓存(last level cache LLC)
- 同一个核心上的超线程可访问共享的L1(L2)cache,并将指令提交给相同的执行单元
- 向量单元对多个数据项执行共享指令
GPU系统
- 同一节点上的多个GPU共享对同一主机内存和网络资源的访问
- core clusters(SM)具有共享缓存并可以访问单个GPU上的相同高带宽内存
- 在同一core cluster上的线程可以访问相同的L1缓存和暂存内存
- 在相同warp上的线程可以同步并且可以直接寄存器交换数据
SIMD
SIMD type:一个表现的像标量的短向量

存储类型和临时变量
- 大多数simd::simd types有相同的存储类型
- simd<T,cuda_warp
>将会使用warp级别并行
 wechat
wechat alipay
alipay