
open mlsys
编程接口
编程接口:python等脚本语言作为上层接口,c/c++等底层语言来保证性能。
机器学习工作流
- 数据处理
- 模型定义:定义神经网络结构
- 定义损失函数和优化器
- 训练及保存模型
- 测试和验证
神经网络层
全连接(Full Connected,FC):当前层每个节点都和上一层节点一一连接,本质上是特征空间的线性变换。
卷积(Convolution):
先定义一个卷积核,通常是N*M的张量,NM通常是奇数,以便让卷积核有一个中心点,
将卷积核对准特征图的某个位置计算卷积。
卷积操作是将卷积核中的值与输入图像或特征图中的对应位置的像素值相乘并将所有成绩相加得到一个单一的值,这个值就是卷积核在当前位置的输出值
将卷积核在输入图像或特征图上沿x和y轴滑动,直到覆盖完整个输入图像或特征图。每次滑动都会计算出一个卷积核的输出值,最终得到一个新的输出图像或特征图。
在卷积神经网络中,通常会将多个卷积核组合在一起使用,以提取不同的特征。这些卷积核可以并行进行卷积操作,产生多个特征图,然后将这些特征图合并在一起,以进一步提高模型的表达能力。

池化(Pooling):
常见的降维操作,有最大池化和平均池化。池化操作和卷积的执行类似,通过池化核、步长、填充决定输出;最大池化是在池化核区域范围内取最大值,平均池化则是在池化核范围内做平均。与卷积不同的是池化核没有训练参数;池化层的填充方式也有所不同,平均池化填充的是0,最大池化填充的是−inf。 图3.3.5是对4×4的输入进行2×2区域池化,步长为2,不填充;图左边是最大池化的结果,右边是平均池化的结果。

图3.3.5 池化操作
定义深度神经网络
对于用户来说,需要定义的是每个神经网络层的参数和计算方式,以及每层之间的连接方式。
机器学习系统将神经网络层抽象出一个基类,所有的神经网络层都继承基类来实现,用户也可以定义自己的神经网络层。
以MindSpore为例,要定义神经网络层,继承Cell后,需要重写__init__ __call__两个方法,__init__定义本层的属性,__call__定义计算方法。
1 | # 接口定义: |
要定义神经网络模型也是继承Cell后重写__init__ __call__两个方法,__init__定义所有的神经网络层,__call__定义计算层与层之间的计算方法。
1 | # 使用Cell子类构建的神经网络层接口定义: |
C/C++编程接口
如何在PYTHON中调用c/c++函数
现代机器学习框架(包括TensorFlow,PyTorch和MindSpore)主要依赖Pybind11来将底层的大量C和C++函数自动生成对应的Python函数,这一过程一般被称为Python绑定( Binding)。
添加c++编写的自定义算子
以MindSpore为例,实现一个GPU算子需要如下步骤:
- Primitive注册:算子原语是构建网络模型的基础单元,用户可以直接或者间接调用算子原语搭建一个神经网络模型。
- GPU Kernel实现:GPU Kernel用于调用GPU实现加速计算。
- GPU Kernel注册:算子注册用于将GPU Kernel及必要信息注册给框架,由框架完成对GPU Kernel的调用。
以mindscope为例:
1.注册算子原语 算子原语通常包括算子名、算子输入、算子属性(初始化时需要填的参数,如卷积的stride、padding)、输入数据合法性校验、输出数据类型推导和维度推导。假设需要编写加法算子,主要内容如下:
- 算子名:TensorAdd
- 算子属性:构造函数__init__中初始化属性,因加法没有属性,因此__init__不需要额外输入。
- 算子输入输出及合法性校验:infer_shape方法中约束两个输入维度必须相同,输出的维度和输入维度相同。infer_dtype方法中约束两个输入数据必须是float32类型,输出的数据类型和输入数据类型相同。
- 算子输出
MindSpore中实现注册TensorAdd代码如下:
1 | # mindspore/ops/operations/math_ops.py |
在mindspore/ops/operations/math_ops.py文件内注册加法算子原语后,需要在mindspore/ops/operations/__init__中导出,方便python导入模块时候调用。
1 | # mindspore/ops/operations/__init__.py |
2.GPU算子开发继承GPUKernel,实现加法使用类模板定义TensorAddGpuKernel,需要实现以下方法:
- Init(): 用于完成GPU Kernel的初始化,通常包括记录算子输入/输出维度,完成Launch前的准备工作;因此在此记录Tensor元素个数。
- GetInputSizeList():向框架反馈输入Tensor需要占用的显存字节数;返回了输入Tensor需要占用的字节数,TensorAdd有两个Input,每个Input占用字节数为element_num∗sizeof(T)。
- GetOutputSizeList():向框架反馈输出Tensor需要占用的显存字节数;返回了输出Tensor需要占用的字节数,TensorAdd有一个output,占用element_num∗sizeof(T)字节。
- GetWorkspaceSizeList():向框架反馈Workspace字节数,Workspace是用于计算过程中存放临时数据的空间;由于TensorAdd不需要Workspace,因此GetWorkspaceSizeList()返回空的std::vector
。 - Launch(): 通常调用CUDA kernel(CUDA kernel是基于Nvidia GPU的并行计算架构开发的核函数),或者cuDNN接口等方式,完成算子在GPU上加速;Launch()接收input、output在显存的地址,接着调用TensorAdd完成加速。
1 | // mindspore/ccsrc/backend/kernel_compiler/gpu/math/tensor_add_v2_gpu_kernel.h |
TensorAdd中调用了CUDA kernelTensorAddKernel来实现element_num个元素的并行相加:
1 | // mindspore/ccsrc/backend/kernel_compiler/gpu/math/tensor_add_v2_gpu_kernel.h |
3.GPU算子注册算子信息包含1.Primive;2.Input dtype, output dtype;3.GPU Kernel class; 4.CUDA内置数据类型。框架会根据Primive和Input dtype, output dtype,调用以CUDA内置数据类型实例化GPU Kernel class模板类。如下代码中分别注册了支持float和int的TensorAdd算子。
1 | // mindspore/ccsrc/backend/kernel_compiler/gpu/math/tensor_add_v2_gpu_kernel.cc |
完成上述三步工作后,需要把MindSpore重新编译,在源码的根目录执行bash build.sh -e gpu,最后使用算子进行验证。
计算图
计算图的基本构成
张量(Tensor)和基本运算单元算子。在计算图中通常使用节点来表示算子,节点间的有向边(Directed Edge)来表示张量状态,同时也描述了计算间的依赖关系。
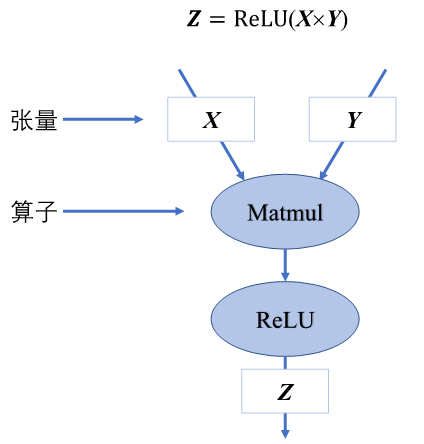
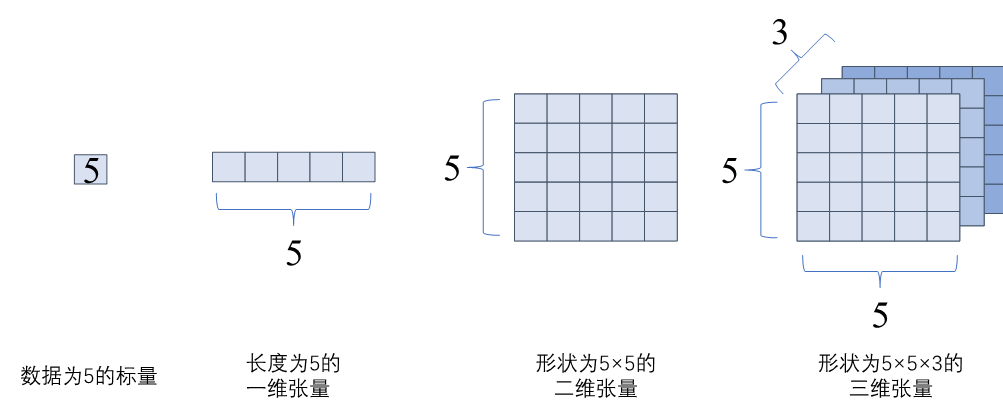
张量即多维数据的统称,使用秩来表示张量的轴数或维度。标量为零秩张量,包含单个数值,没有轴;向量为一秩张量,拥有一个轴;拥有RGB三个通道的彩色图像即为三秩张量,包含三个轴。
| 张量属性 | 功能 |
|---|---|
| 形状(shape) | 存储张量的每个 维度的长度,如[3,3,3] |
| 秩或维数(dim) | 表 示张量的轴数或者维数 ,标量为0,向量为1。 |
| 数据类型(dtype) | 表示存储的数据类型 ,如bool、uint8、int1 6、float32、float64等 |
| 存储位置(device) | 创建张 量时可以指定存储的设 备位置,如CPU、GPU等 |
| 名字(name) | 张量的标识符 |
算子类型:
- 张量操作算子:张量的结构操作和数学运算;张量的形状、维度调整以及张量合并等;矩阵乘法、计算范数、行列式和特征值计算等。
- 神经网络算子:包括特征提取、激活函数、损失函数、优化算法等
- 数据流算子:包括数据的预处理与数据载入等相关算子
- 控制流算子:控制计算图中的数据流向,有条件运算符和循环运算符。
计算依赖
算子之间存在依赖关系,计算图应当是有向无环图。如果形成循环依赖则不正确。机器学习框架中,表示循环关系通常以展开机制实现,即循环N次则将对应的计算子图复制N次,这些复制的所有张量和运算符会被赋予新的标识符。
控制流
目前主流机器学习语言使用两种方式来提供控制流
-
- 前端语言控制流:使用前端语言例如python进行控制决策,这种方式编程简单快捷,但是由于机器学习框架的数据计算运行在后端硬件,造成控制流和数据流之间的分离,计算图不能完整的运行在后算计算硬件上。这种方法称为图外方法
- 机器学习框架控制原语:在内部设计低级别细粒度的控制原语运算符,能够直接执行在计算硬件上,整体在后端运算,这种实现方式被称为图内方法。
前者能快速将算法转换为模型代码,后者高性能
计算图的生成
- 静态图:根据前端语言描述网络结构及参数遍历等信息构建一份固定的计算图
- 动态图:每一次执行神经网络模型都根据前端语言动态生成临时计算图。
静态生成
静态计算图可以通过优化策略转换为等价的更加高效的结构。
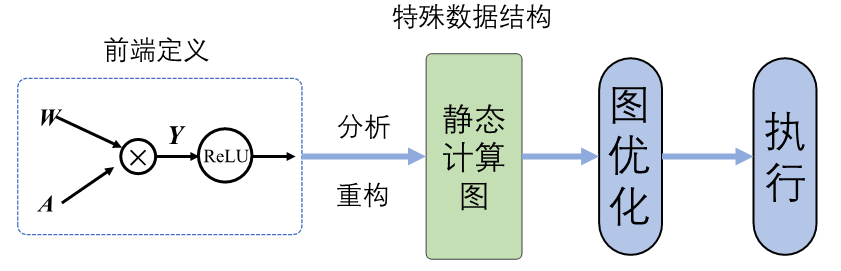
静态计算图的两大优势
- 计算性能:可以进行图优化,kernel fusion
- 直接部署:机器学习框架可以将静态计算图转换为支持不同计算硬件直接调用的代码。
缺点:
- 难以调试,出错时难以直接找到错误信息
动态生成
相较于静态图整个程序都在后端代码中执行,动态图是前端语言调用后端框架的算子,每个算子执行完后再将结果返回前端语言执行后面的操作。
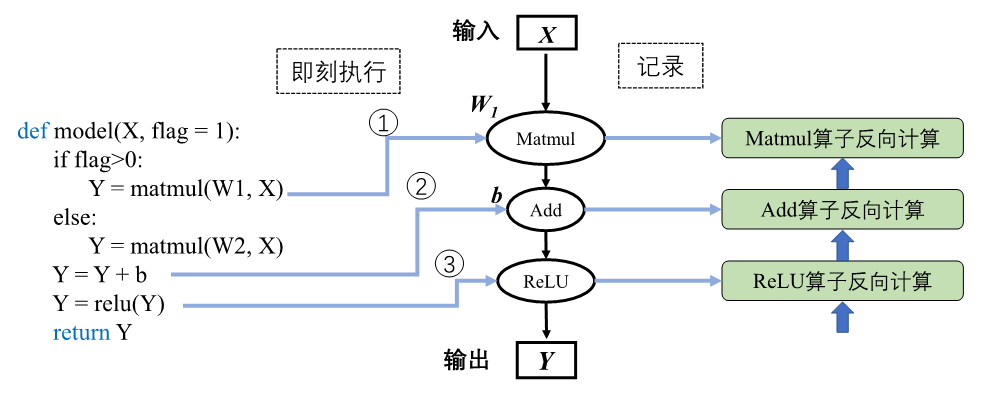
优点:
- 便于调试,对初学者友好,提高了算法开发和迭代的效率
缺点:
- 难以进行模型优化以提高计算效率
| 特性 | 静态图 | 动态图 |
|---|---|---|
| 即时获取中间结果 | 否 | 是 |
| 代码调试难易 | 难 | 易 |
| 控制流实现方式 | 特定的语法 | 前端语言语法 |
| 性能 | 优化策略多,性能更佳 | 图优化受限,性能较差 |
| 内存占用 | 内存占用少 | 内存占用相对较多 |
| 内存占用 | 可直接部署 | 不可直接部署 |
目前TensorFlow、MindSpore、PyTorch、PaddlePaddle等主流机器学习框架都具备动态图转静态图的功能。
AI编译和前端技术
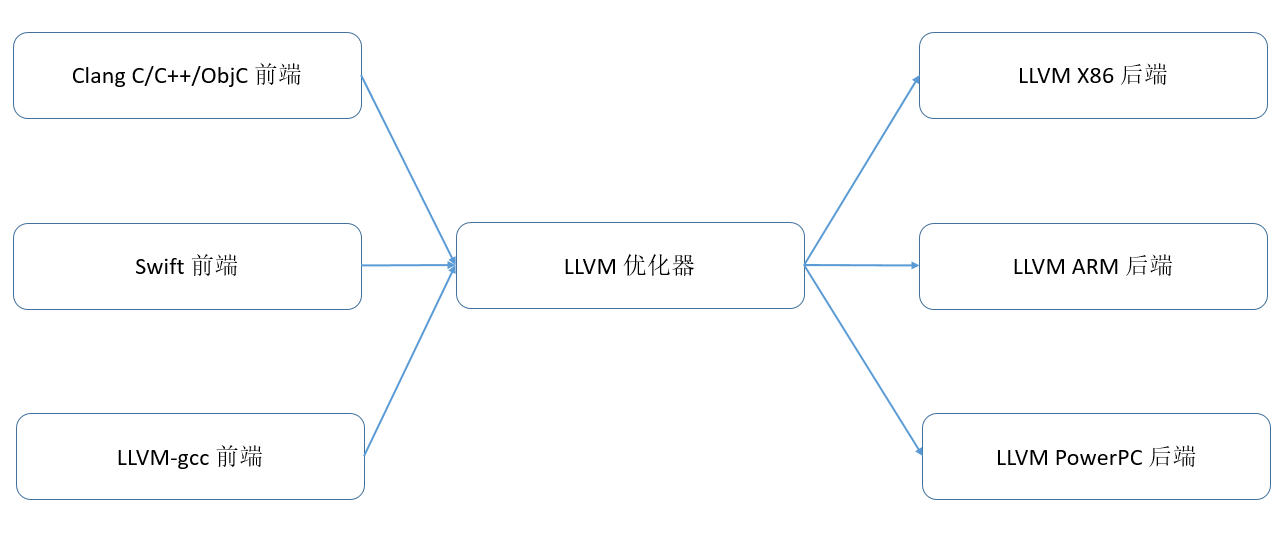
LLVM包含前端,IR,和后端三个部分。前端将高级语言转换成IR,后端将IR转化成目标硬件上的机器指令。
IR作为桥梁在前后端之间进行基于IR的各种优化。
IR可以是单层的,也可以是多层的, LLVM IR是典型的单层IR,其前后端优化都基于相同的LLVM IR进行。
AI编译器一般采用多层级IR设计。 图6.1.2展示了TensorFlow利用MLIR实现多层IR设计的例子(被称为TensorFlow-MLIR)。其包含了三个层次的IR,即TensorFlow Graph IR, XLA(Accelerated Linear Algebra,加速线性代数)、HLO(High Level Operations,高级运算)以及特定硬件的LLVM IR 或者TPU IR。
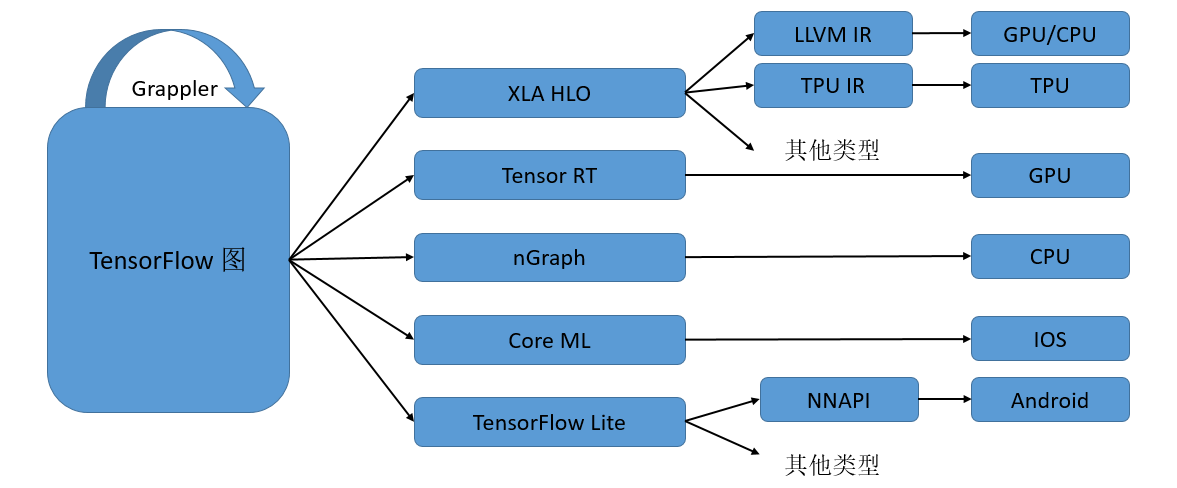
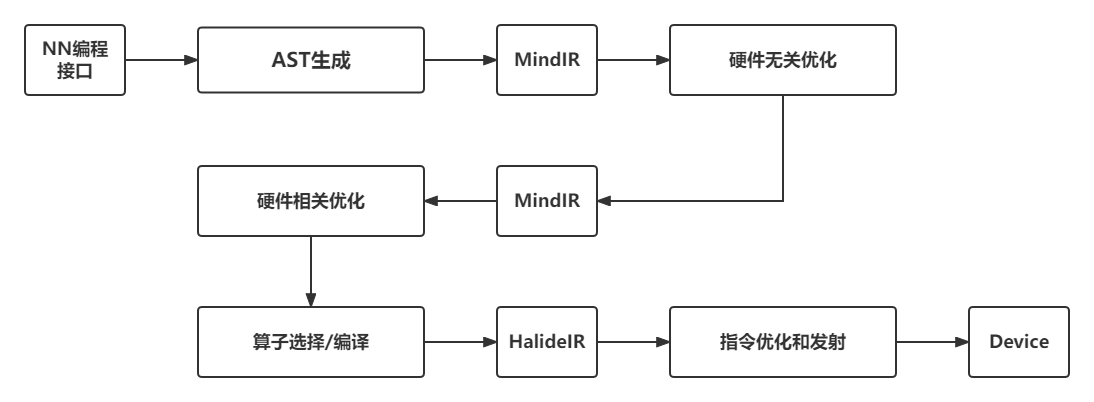
多层级IR的优势是IR表达上更加地灵活,可以在不同层级的IR上进行合适的PASS优化,更加便捷和高效。 但是多层级IR也存在一些劣势。首先,多层级IR需要进行不同IR之间的转换,而IR转换要做到完全兼容是非常困难的,工程工作量很大,还可能带来信息的损失。上一层IR优化掉某些信息之后,下一层需要考虑其影响,因此IR转换对优化执行的顺序有着更强的约束。其次,多层级IR有些优化既可以在上一层IR进行,也可以在下一层IR进行,让框架开发者很难选择。最后,不同层级IR定义的算子粒度大小不同,可能会给精度带来一定的影响。为了解决这一问题,机器学习框架如MindSpore采用统一的IR设计(MindIR)。 图6.1.3展示了MindSpore的AI编译器内部的运行流程。其中,编译器前端主要指图编译和硬件无关的优化,编译器后端主要指硬件相关优化、算子选择等。
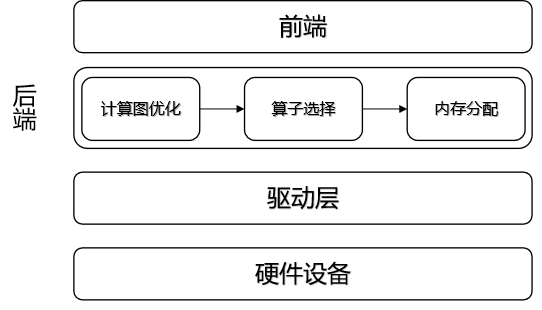
编译器后端和运行时
后端主要负责计算图优化、算子选择和内存分配的任务。
计算图优化方面
- 一个算子就能实现几个计算节点的功能,此时可以将这些IR节点合并成一个计算节点,该过程成为算子融合
- 对于复杂计算,后端没有直接对应的算子,可以将几个基本运算的算子组合达到相同的计算效果。
算子选择方面,本质上是一个模式匹配问题,用户代码产生的IR往往可以映射成多种不同的硬件算子。这些算子的效率有很大的差别,如何根据IR选择硬件算子是问题所在。
现有编译器一般对每一个IR节点提供多个候选算子,要选择最优的算子作为最终执行在设备上的算子。
计算图优化
通用优化
通用优化与硬件无关,优化的核心是子图的等价变化,即将目标子图等价替换成对硬件更友好的子图结构。
比如:算子融合,将计算密集型和访存密集型的算子融合,减少内存访问延时和带宽压力
- 计算密集型:卷积,全连接
- 访存密集型:大部分是Element-Wise算子,例如 ReLU、Element-Wise Sum
例如:“Conv + Conv + Sum + ReLU”的融合,从 图7.2.1中可以看到融合后的算子减少了两个内存的读和写的操作,优化了Conv的输出和Sum的输出的读和写的操作。
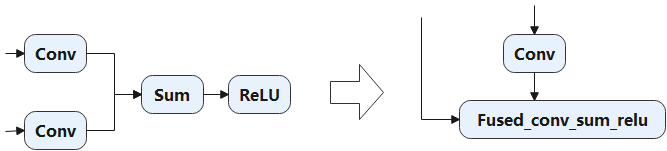
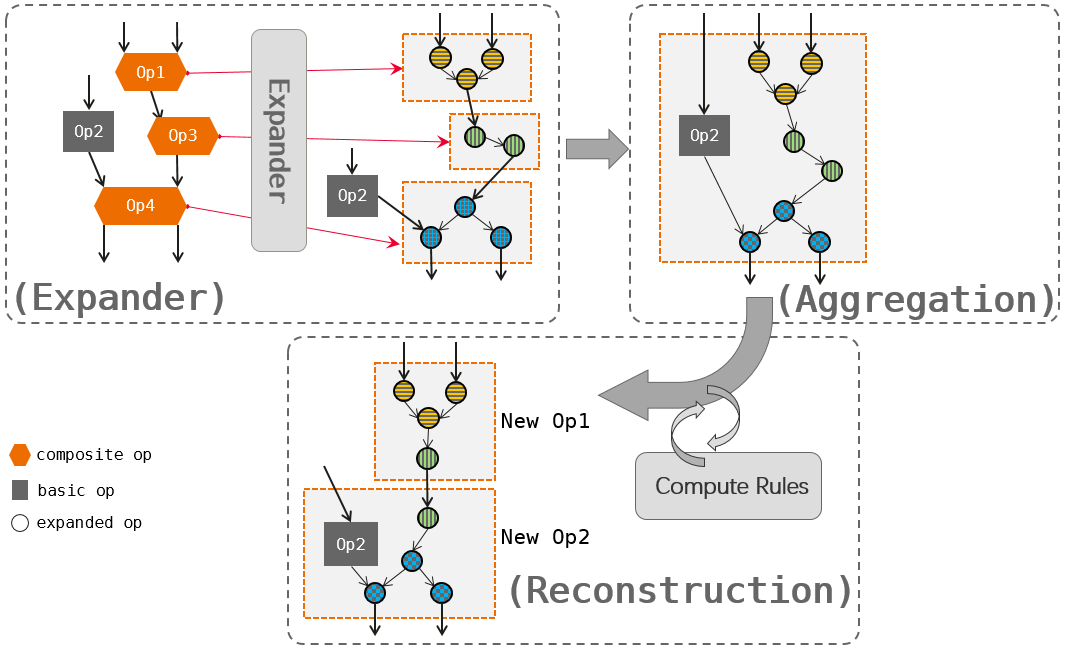
除了对于特定类型算子的融合优化,还有自动算子生成技术,通过算子拆解、算子聚合、算子重建三阶段融合算子,减少低效的内存访问。
特定硬件优化
针对某些硬件的限制,比如硬件指令的限制,硬件要求数据格式的限制进行优化。
算子选择
根据哪些方面选择算子?
- 数据排布格式:如NCHW和NHWC
- 计算精度:fp32 fp16 int32
数据排布格式
NCHW类型和NHWC类型。其中N代表了数据输入的批大小,C代表了图像的通道,H和W分别代表图像输入的高和宽
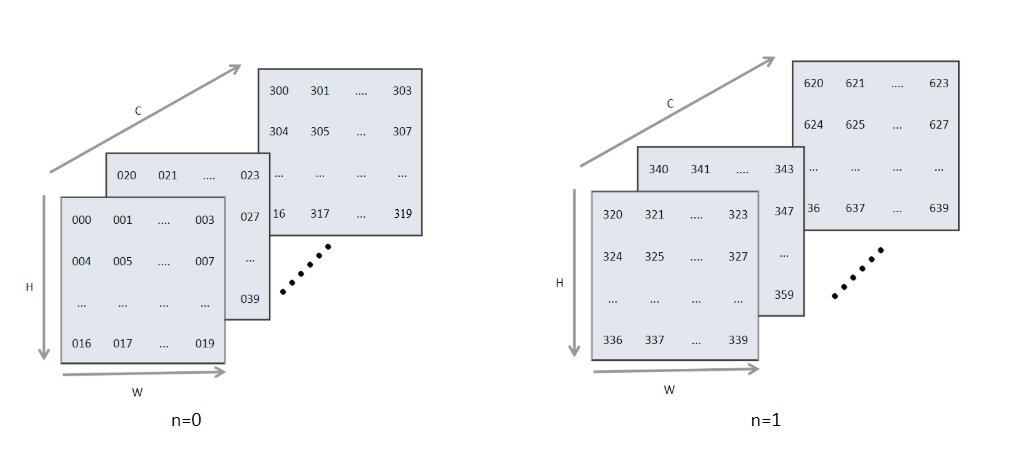
但是计算机的存储并不能够直接将这样的矩阵放到内存中,需要将其展平成1维后存储,这样就涉及逻辑上的索引如何映射成为内存中的索引,即如何根据逻辑数据索引来映射到内存中的1维数据索引。
对于NCHW的数据是先取W轴方向数据,再取H轴方向数据,再取C轴方向,最后取N轴方向。其中物理存储与逻辑存储的之间的映射关系为
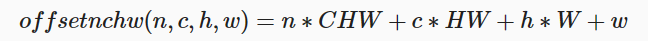
NHWC批次优先适合CPU NCHW通道优先适合GPU(参考行主序列主序)
除此之外还有比如oneDNN上的nChw16c 和nChw8c 格式,以及Ascend芯片的5HD等格式。
数据精度

其中bfloat16并不属于一个通用的数据类型,是Google提出的一种特殊的类型,现在一般只在一些TPU上训练使用,其指数位数与float32位数保持一致,可以较快的与float32进行数据转换。由于bfloat16并不是一种通用类型,IEEE中也并没有提出该类型的标准。
内存分配
随着深度学习的发展,深度神经网络的模型越来越复杂,AI芯片上的内存很可能无法容纳一个大型网络模型。因此,对内存进行复用是一个重要的优化手段。此外,通过连续内存分配和 In-Place内存分配还可以提高某些算子的执行效率。
内存分配的流程
- 首先根据数据类型和张量形状算出所需内存
- 对内存进行对齐
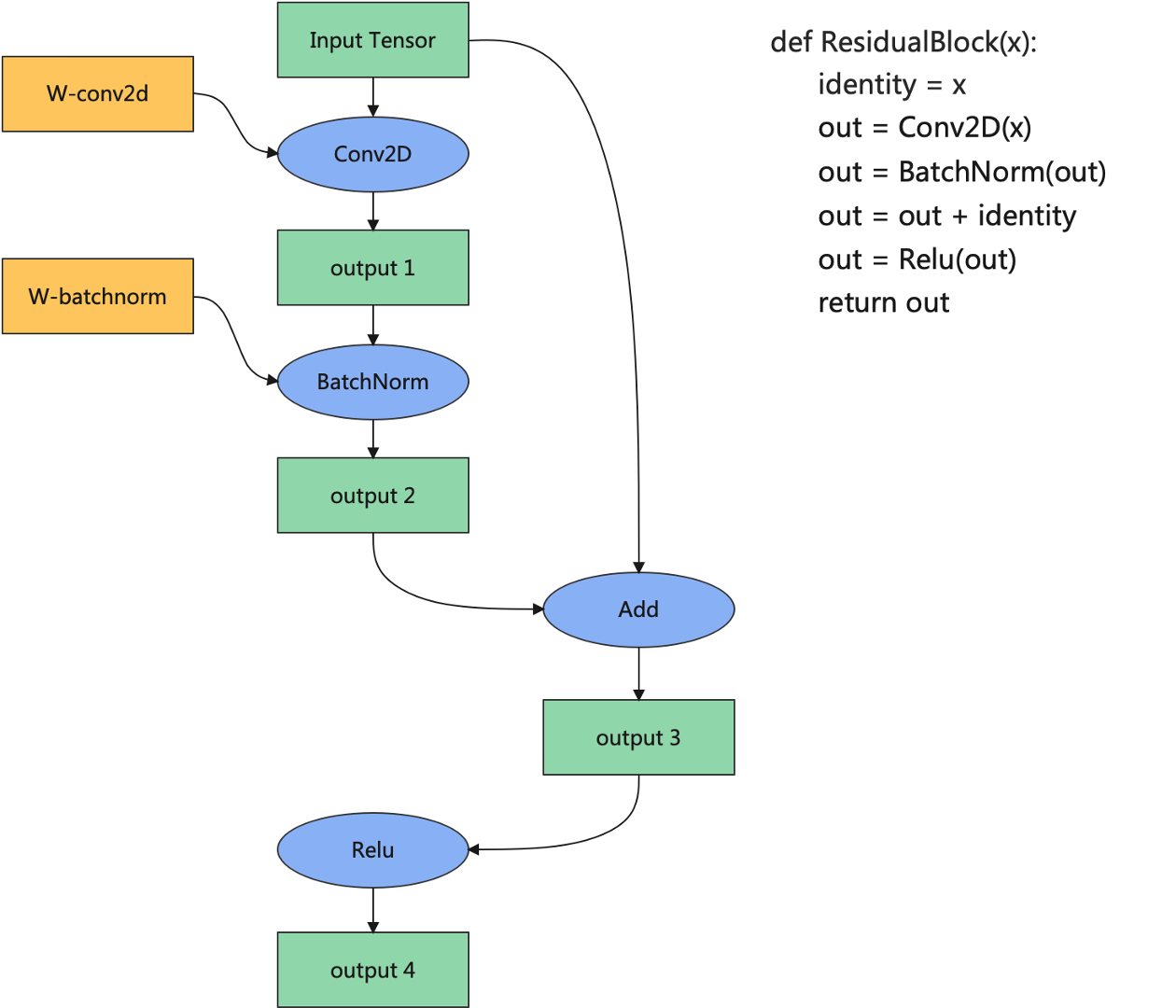
如图所示一般有三种类型的内存,整张图的输入张量、算子权重、算子的输出。
为了避免频繁申请释放内存的开销,使用内存池来管理内存。
mindspore的申请方法:双游标法
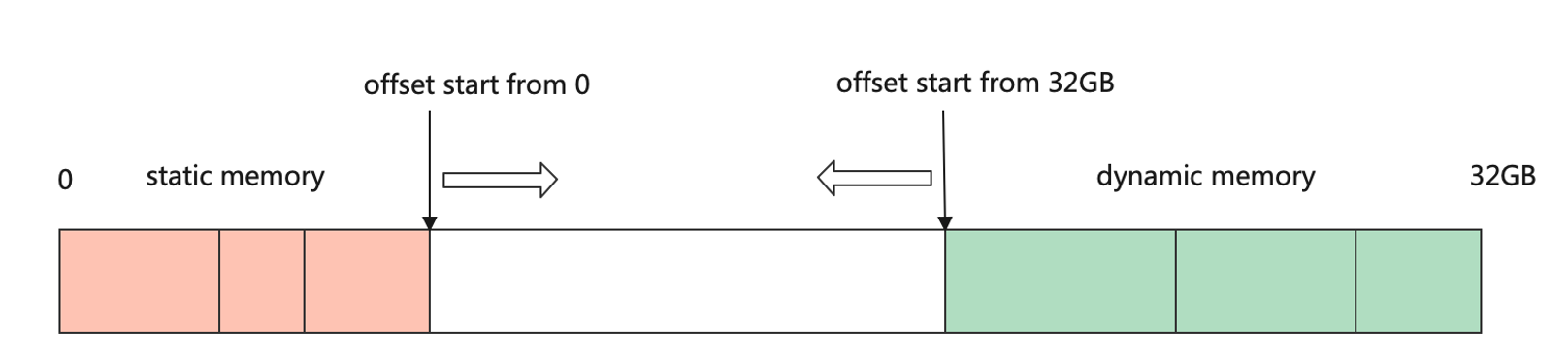
从首地址开始为算子权重分配内存,声明周期长,从末尾开始为算子输出分配内存,声明周期短,若后续无需使用,即可通过移动指针放弃该部分内存。
内存复用
内存复用即是若之前数据不再被需要,重用这部分内存。
内存复用策略的求解是一个NP完全的问题。许多深度学习框架通常采用贪心的策略去分配内存。
常用内存分配优化手段
- 内存融合:其实也是算子融合的一种,比如AllReduce算子,在分布式集群下通信往往是性能瓶颈,可以将多个通信算子融合成一个,减少通信次数。
- In-Place算子:in-place计算减少内存申请。
计算调度与执行
根据是否将算子编译成计算图,计算分为单算子调度和计算图调度。
单算子调度由python运行时直接调度,便于调试。但是难以进行性能的优化,一般使用计算图调度。
根据是否一次性将子图下发到硬件分为交互式执行和下沉式执行。
交互式执行host和device之间有交互,下沉式执行避免了这种交互从而获得更好的性能,但是在动态shape算子、复杂的控制流等场景下会面临较大的技术挑战。
算子编译器
将动态语言描述的张量技算输出为特定硬件上的可执行文件
- 子策略组合优化:比如通过平铺(Tile),循环移序(Reorder)和切分(Split)的调度策略优化矩阵乘
- 调度空间算法优化:比如使用多面体模型编译(Polyhedral Compilation)来优化编译
- 芯片指令集适配:
硬件加速器
和传统CPU和GPU芯片相比,深度学习硬件加速器有更高的性能和更低的能耗。
两个设计重要指标
- 能效
- 通用性
华为昇腾AI芯片达芬奇架构

编程接口的层次
- 算子库层级:如cuBLAS基本矩阵与向量运算库,cuDNN深度学习加速库,均通过Host端调用算子库提供的核函数使能张量计算核心;
- 编程原语层级:如基于CUDA的WMMA API编程接口。同算子库相比,需要用户显式调用计算各流程,如矩阵存取至寄存器、张量计算核心执行矩阵乘累加运算、张量计算核心累加矩阵数据初始化操作等;
- 指令层级:如PTX ISA MMA指令集,提供更细粒度的mma指令,便于用户组成更多种形状的接口,通过CUDA Device端内联编程使能张量计算核心。
cuda的一种gemm实现
8.4. 加速器实践 — 机器学习系统:设计和实现 1.0.0 documentation (openmlsys.github.io)
数据处理框架
数据处理的核心组件
- **数据加载组件(Load)**:负责从存储设备中加载读取数据集,需要同时考虑存储设备的多样性(如本地磁盘/内存,远端磁盘和内存等)和数据集格式的多样性(如csv格式,txt格式等)。根据机器学习任务的特点,AI框架也提出了统一的数据存储格式(如谷歌TFRecord, 华为MindRecord等)以提供更高性能的数据读取。
- **数据混洗组件(Shuffle)**:负责将输入数据的顺序按照用户指定方式随机打乱,以提升模型的鲁棒性。
- **数据变换组件(Map)**:负责完成数据的变换处理,内置面向各种数据类型的常见预处理算子,如图像中的尺寸缩放和翻转,音频中的随机加噪和变调、文本处理中的停词去除和随机遮盖(Mask)等。
- **数据组装组件(Batch)**:负责组装构造一个批次(mini-batch)的数据发送给训练/推理。
- **数据发送组件(Send)**:负责将处理后的数据发送到GPU/华为昇腾Ascend等加速器中以进行后续的模型计算和更新。高性能的数据模块往往选择将数据向设备的搬运与加速器中的计算异步执行,以提升整个训练的吞吐率。
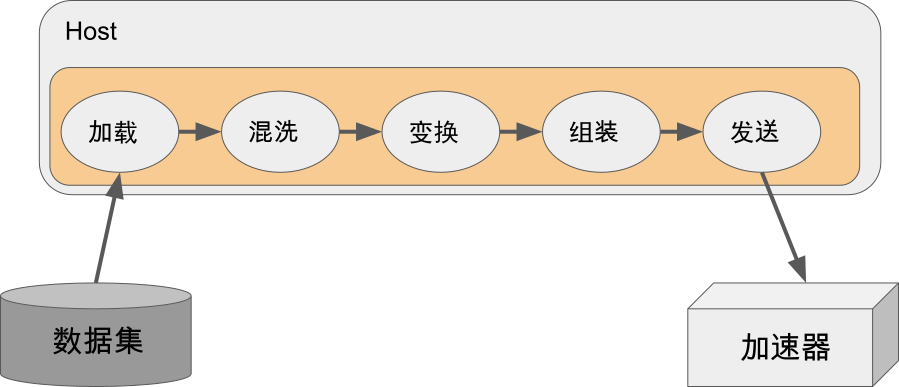
这些组件应当具有:
- 易用性
- 高效性
- 保序性:机器学习模型训练对数据输入顺序敏感。为了帮助用户更好的调试和确保不同次实验的可复现性,我们需要在系统中设计相应机制使得数据最终送入模型的顺序由数据混洗组件的数据输出顺序唯一确定,不会由于并行数据变换而带来最终数据模块的数据输出顺序不确定。
高效性设计
深度学习模型执行流程分为数据加载、数据处理、芯片计算三个过程。为了追求最高的训练吞吐率,一般将这三个步骤异步并行执行。
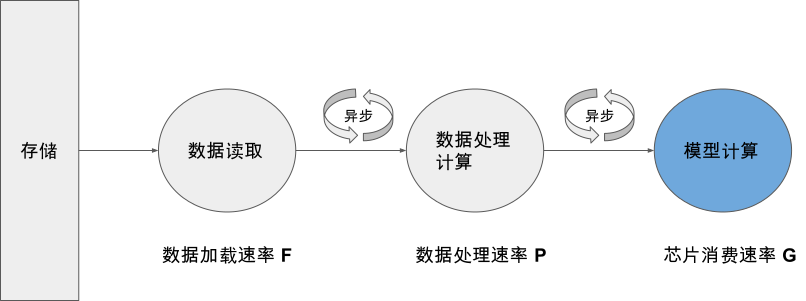
通常情况下我们希望G < min(F, P),此时加速芯片不会因为等待数据而阻塞。然而现实情况下,我们常常要么因为数据加载速率F过低(称为I/O Bound),要么因为数据预处理速率P过低(称为CPU Bound)导致G>min(F, P)而使得芯片无法被充分利用。
TODO
模型部署
模型部署的过程:将训练好的模型和参数持久化成文件,但是不同训练框架导出的模型文件中存储的数据结构不同,这就为模型的推理系统带来了不便。推理系统为了支持不同的训练框架的模型,需要将模型文件中的数据转换成统一的数据结构。此外,在训练模型转换成推理模型的过程中,需要进行一些如算子融合、常量折叠等模型的优化以提升推理的性能。
模型压缩:为了满足不同硬件设备的限制,在边缘设备或者低功耗的微控制器上只能部署简单的机器学习模型。为了满足这些硬件的限制,在有些场景下要对训练好的模型进行压缩,降低其复杂度或数据的精度,减少模型参数。
常见方法:
- 算子融合
通过表达式简化、属性融合等方式将多个算子合并为一个算子的技术,融合可以降低模型的计算复杂度及模型的体积。
- 常量折叠
将符合条件的算子在离线阶段提前完成前向计算,从而降低模型的计算复杂度和模型的体积。常量折叠的条件是算子的所有输入在离线阶段均为常量。
- 模型压缩
通过量化、剪枝等手段减小模型体积以及计算复杂度的技术,可以分为需要重训的压缩技术和不需要重训的压缩技术两类。
- 数据排布
根据后端算子库支持程度和硬件限制,搜索网络中每层的最优数据排布格式,并进行数据重排或者插入数据重排算子,从而降低部署时的推理时延
- 模型混淆
对训练好的模型进行混淆操作,主要包括新增网络节点和分支、替换算子名的操作,攻击者即使窃取到混淆后的模型也不能理解原模型的结构。此外,混淆后的模型可以直接在部署环境中以混淆态执行,保证了模型在运行过程中的安全性。
训练模型到推理模型的转换及优化
模型转换
ONNX(Open Neural Network Exchange)开放神经网络交换协议支持将不同的训练框架定义的数据结构转换成统一的数据结构上。
完成模型转换后,会进行一些不依赖输入的工作,如常量折叠、算子融合、算子替换、算子重排等一些优化手段。
算子融合
推理阶段的算子融合:在推理阶段某些算子的中的符号是常量,可以进行融合,但是在训练过程中是参数,如果融合会导致模型参数的缺少。因此有些算子融合只能在推理阶段进行。
算子替换
算子替换,即将模型中某些算子替换计算逻辑一致但对于在线部署更友好的算子。算子替换的原理是通过合并同类项、提取公因式等数学方法,将算子的计算公式加以简化,并将简化后的计算公式映射到某类算子上。算子替换可以达到降低计算量、降低模型大小的效果。
同样,算子替换优化策略只能在部署阶段进行,因为一方面在部署阶段Batchnorm计算公式中被认为是常量的符号,在训练时是参数并非常量。另一方面该优化策略会降低模型的参数量,改变模型的结构,降低模型的表达能力,影响训练收敛时模型的准确率。
算子重排
算子重排是指将模型中算子的拓扑序按照某些规则进行重新排布,在不降低模型的推理精度的前提下,降低模型推理的计算量。常用的算子重排技术有针对于Slice算子、StrideSlice算子、Crop算子等裁切类算子的前移、Reshape算子和Transpose算子的重排、BinaryOp算子的重排等。
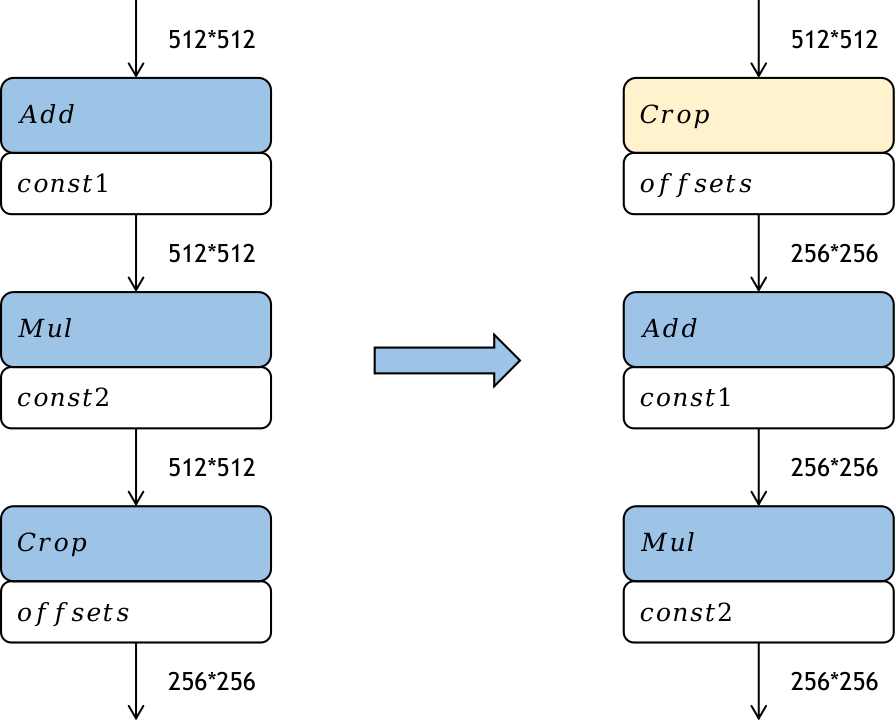
图10.2.4 Crop算子重排
如 图10.2.4 ,Crop算子是从输入的特征图中裁取一部分作为输出,经过Crop算子后,特征图的大小就降低了。如果将这个裁切的过程前移,提前对特征图进行裁切,那么后续算子的计算量也会相应地减少,从而提高模型部署时的推理性能。Crop算子前移带来的性能提升跟Crop算子的参数有关。但是Crop算子一般只能沿着的element wise类算子前移。
模型压缩
量化
将连续取值的浮点型权重(通常为float32或者大量可能的离散值)近似为有限多个离散值(通常为int8)的过程.
工业界最常用的量化位数是8比特
根据量化数据表示的原始数据范围是否均匀,还可以将量化方法分为线性量化和非线性量化。实际的深度神经网络的权重和激活值通常是不均匀的,因此理论上使用非线性量化导致的精度损失更小,但在实际推理中非线性量化的计算复杂度较高,通常使用线性量化。下面着重介绍线性量化的原理。
假设r表示量化前的浮点数,量化后的整数q可以表示为:
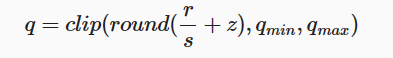 (10.3.1)
(10.3.1)
round和clip分别表示取整和截断操作,qmin和qmax是量化后的最小值和最大值。s是数据量化的间隔,z是表示数据偏移的偏置,z为0的量化被称为对称(Symmetric)量化,不为0的量化称为非对称(Asymmetric)量化。对称量化可以避免量化算子在推理中计算z相关的部分,降低推理时的计算复杂度;非对称量化可以根据实际数据的分布确定最小值和最小值,可以更加充分的利用量化数据信息,使得量化导致的损失更低。
根据量化参数s和z的共享范围,量化方法可以分为逐层量化和逐通道量化。逐层量化以一层网络为量化单位,每层网络的一组量化参数;逐通道量化以一层网络的每个量化通道为单位,每个通道单独使用一组量化参数。逐通道量化由于量化粒度更细,能获得更高的量化精度,但计算也更复杂。
根据量化过程中是否需要训练,可以将模型量化分为量化感知训练(Quantization Aware Training, QAT)和训练后量化(Post Training Quantization, PTQ)两种,其中感知量化训练是指在模型训练过程中加入伪量化算子,通过训练时统计输入输出的数据范围可以提升量化后模型的精度,适用于对模型精度要求较高的场景;训练后量化指对训练后的模型直接量化,只需要少量校准数据,适用于追求高易用性和缺乏训练资源的场景。
量化落地的三大挑战
精度挑战:
-
- 量化方法:线性量化对数据分布的描述不准确
- 低比特:比特数越低,精度损失越大
- 任务:任务越复杂,精度损失越大
- 大小:模型越小,精度损失越大
硬件支持程度:
- 不同硬件支持低比特指令不同
- 不同硬件提供不同的低比特指令计算方式不同
- 不同硬件体系结构kernel优化方式不同
量化是否真的有效:
- 混合精度需要量化与反量化,cast转换会影响性能
- 模型参数效,压缩比高,不代表执行内存占用少
量化方法

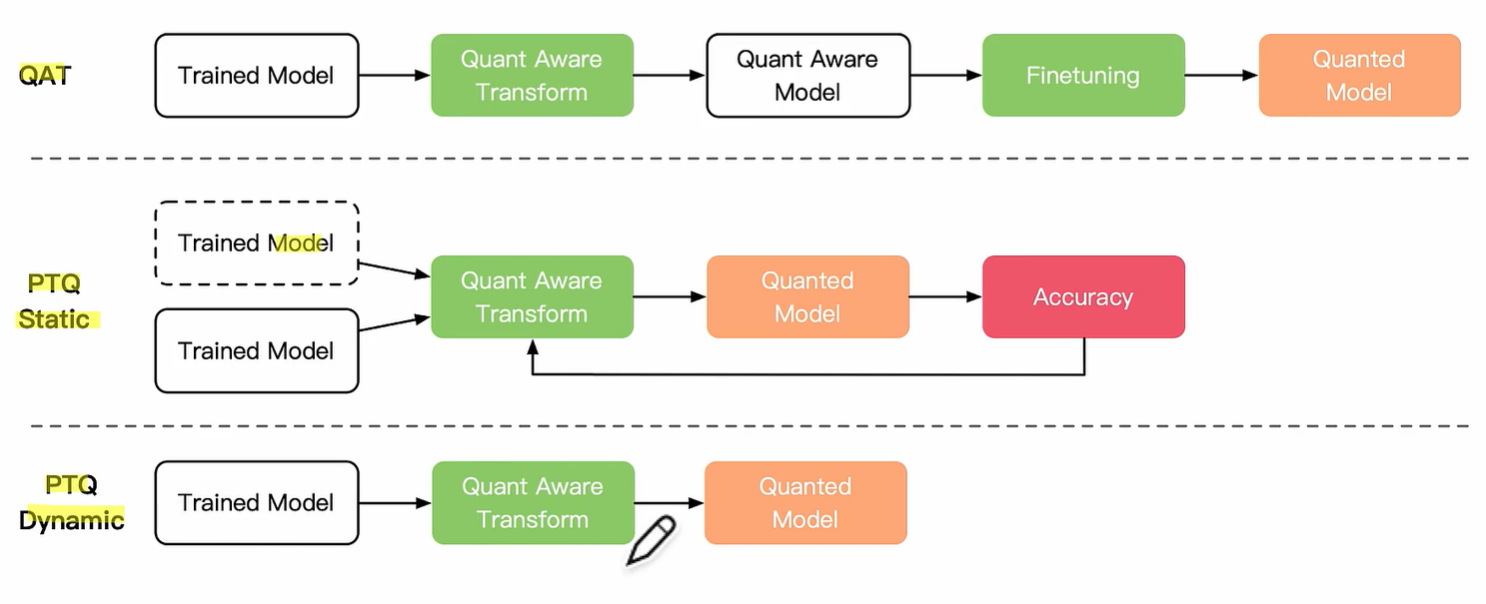
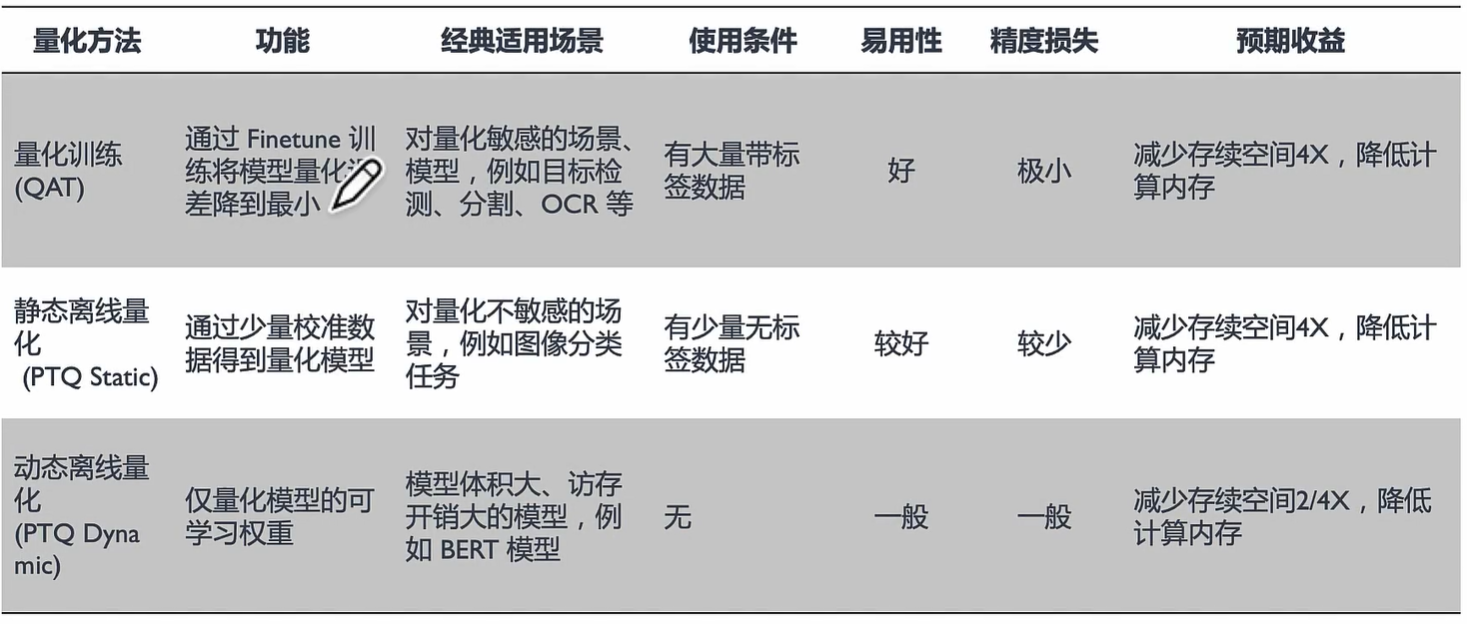
量化建立数据映射关系
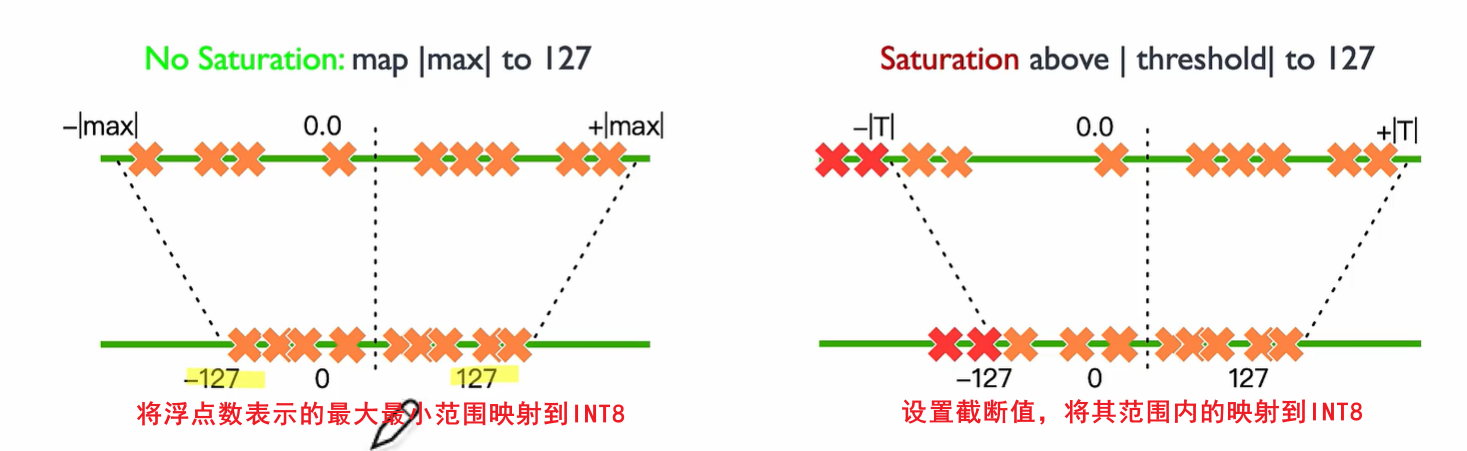
对称量化和非对称量化
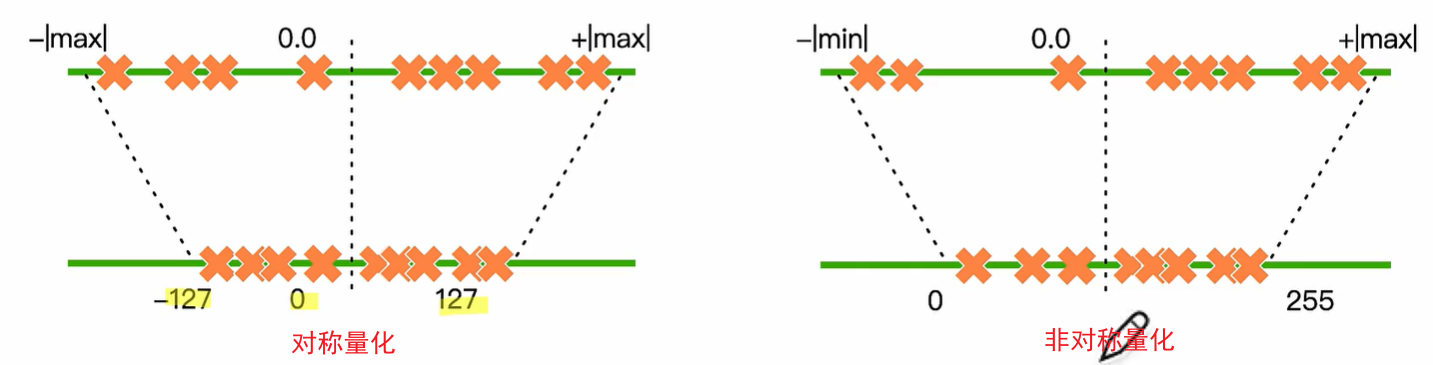
量化原理


 wechat
wechat alipay
alipay




