
GPU Graph Processing on CXL-Based Microsecond-Latency External Memory
START Basic
# GPU Graph Processing on CXL-Based Microsecond-Latency External MemoryTL;DR:评估使用CXL拓展GPU图形处理负载的性能,当CXL外存延迟小到某个特定值,GPU图处理性能就跟在DRAM上一样
- GPU图处理对外存延迟比较宽容,能够容忍几微秒的延迟
- 基于FPGA的flash设备证明毫秒级别的延迟性能跟DRAM类似,证明小地址对齐的重要性
- 基于FPGA的memory设备验证了只要延迟小于几个微秒,其性能就和DRAM一样
相比于CPU,GPU是延迟容忍的,因为有更多的并行计算资源,但是其受限于PCIe带宽,sota的方法EMOGI和BaM都实现了接近峰值的带宽
ANALYSIS
𝑡=𝐷/𝑇
D是需要读取的数据,T是读取速度,理想情况下D应当等于E边数,T应当接近带宽。
然而由于读放大(read amplification factor, or RAF)的存在D/E是大于1的,细粒度的读取有助于减少读取的数据,提高性能。
论文对T进行了详细的建模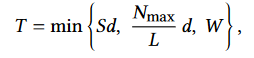
d是平均每次请求的传输数据大小,S是外部存储器的随机读取性能,L是平均延迟,Nmax是最大未完成数,W是带宽。这个公式意味着T的上限是带宽,要达到上限还要突破外部存储器性能,未完成数和延迟、每次请求数据量的限制。

总的来说,在特定设备上提高性能的方式
- 细粒度的读,减少读放大
- 增加每次请求传输数据量(合并)
EMOGI和 BaM都实现了接近带宽的的T,但是EMOSI的性能好,因为EMOSI的读取粒度是32B而BaM是4Kb
外部存储器的随机读写性能是够的,其限制因素变成L延迟,当较低的延迟时,T可以接近W。
evaluation
通过细粒度读的flash和BaM对比验证观察1,通过CXL和DRAM比验证较小的延迟下CXL可以实现和DRAM一样的性能。
指针追逐实验测量CXL的性能
discuss
CXL设备到GPU的PCIe链路将会仍然是瓶颈
本文只考虑的只读的情况,如果有写请求,缓存一致性会更复杂,
Back: you have read it ! Tags: cxl END
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 wechat
wechat alipay
alipay
Related Articles

Comment

