
Latency-Tolerant Software Distributed Shared Memory
START Basic
# Latency-Tolerant Software Distributed Shared Memory TL;DR:DSM系统分布式共享内存,使集群表现得单机NUMA一样,使用任务委托来利用局部性,使用任务切换来隐藏延迟 ## introduction 传统的DSM致力于拓展单机并行计算思想到集群,但是只有局部性好、共享数据有限、粗粒度同步的应用才会适合这种系统。相比于利用局部性,Grappa依赖于并行来保持处理器忙碌来隐藏通信延迟
grappa使用IB互联,主要包含三个组件
- 全局地址空间
- 轻量级的用户级任务
- 聚合通信层
design
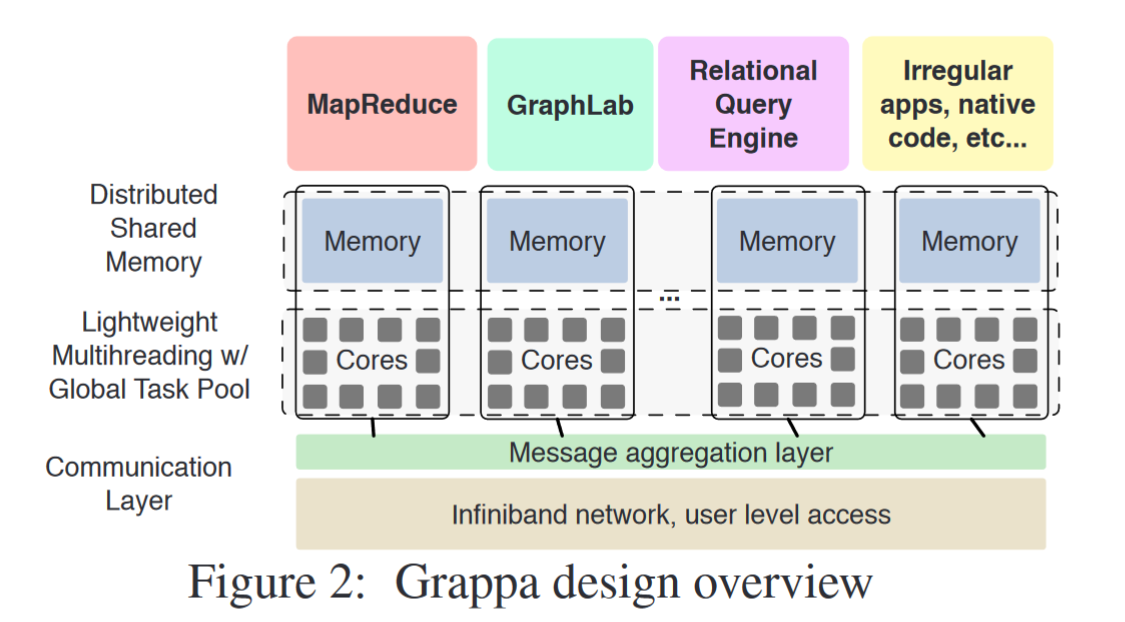
distributed shared memory:每个核心可以访问自己的内存,访问远程数据的操作通过delegate操作(函数)运行在拥有数据的核心上,包括简单的读写和同步操作(fetch-and-add)
tasking system:轻量级的多线程和全局的工作窃取。通过多线程调度实现并发,长延迟操作会自动暂停,当操作完成时再开始。
communication layer:将小的数据聚合成大的,基于active message,为了移植性,使用MPI作为底层通信库
Distributed Shared Memory
两种寻址:本地、全局
本地寻址:本地访问节点内存,本地指针无法访问其他核心上的内存
全局寻址:PGAS模型,允许本地内存暴露给全局。也支持对称分配,每个核心上创建代理保存副本
delegate操作:访问全局内存的操作通过委托实现,当数据访问模式具有低局部性时,由主核心修改数据比通信更快。
memory consistency:一致性通过同步的委托操作完成,多个委托任务串行的被主核心执行。
Tasking System
task:任务由闭包指定,在cpp中就是函数对象(函数指针,仿函数,lambda),可以被序列化并且跨系统传输
Workers:绑在某个核心上,任务调度给工人
schedule:当worker遇到长延迟操作,就切换任务来隐藏延迟。
每个核心由独立的调度器,每个调度器有一系列活跃worker的集合,叫做ready
worker queue,此外还有三个task的集合,第一个是未绑定的任务,第二个已绑定的任务,第三个根据任务ddl的优先队列,管理高优先级的系统任务,比如定期的通信请求
context switch:将上下文切换视为函数调用,仅保存和恢复 x86-64 ABI [12] 中指定的被调用者保存的状态,而不是抢占式上下文切换所需的完整寄存器集。这需要 62 字节的存储空间
上下文切换可能会造成cache miss,为了避免,显式的管理上下文数据到cache:建立ready worker的流水线,分成eady-unscheduled, ready-scheduled, and ready-resident三个阶段。当上下文预取打开时,调度程序只允许运行就绪驻留的工作线程;所有其他工作人员都被假定为超出缓存。
如何表达并行性:
- 支持生成单独的任务
- API类似TBB的parallel_for
- 允许在索引空间或共享内存区域并行,前者可以被任意核心窃取,后者只能在主核心上允许
communication
- 基于active message的用户级消息接口
- 支持请求聚合的网络传输层
AM:集群的硬件是同质的,每个进程都运行相同的二进制文件,每条消息包含模板生产的反序列化器指针,闭包的逐字节副本和可选的数据有效负载。
消息聚合:
容错
用一段文字论证了下,说容错成本太低,所以没有做容错
related
cray MTA:一个CPU有128个寄存器集,一个寄存器集运行一个线程, 通过线程切换来隐藏延迟,有点像GPU
Back: you have read it ! Tags: graph processing system END
 wechat
wechat alipay
alipay


