
NUMA-Aware Graph-Structured Analytics
NUMA-Aware Graph-Structured Analytics
ppopp15
TL;DR:numa-aware通过优化图数据放置和访问策略来减少随机和远程内存访问
本文基于两个见解:
- 随机或者交织分配图数据都会显著损害数据局部性和并行
- 顺序的节点间内存访问相比随机的节点内节点间访问都有更高的带宽
基于这两个见解,Polymer的设计为 - 有区分的放置拓扑数据、应用定义的数据和可变运行时状态来最小远程访问
- 通过在NUMA节点间进行轻量级的复制来将随机远程访问转化为顺序远程访问
除此之外,进一步构建了分层屏障来提高并行和局部性、针对倾斜图使用面向边的平衡分区、根据活动顶点比例的自适应数据结构。
background

下面的图描述了ligra push和pull访问的数据及访问模式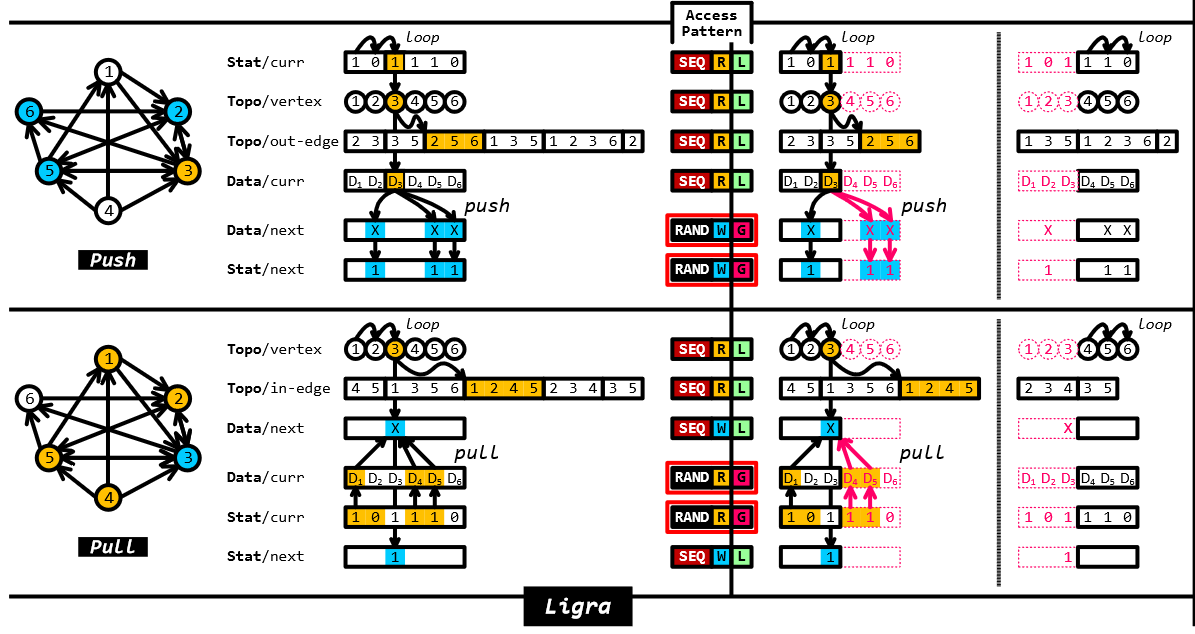
以边为中心的系统X-stream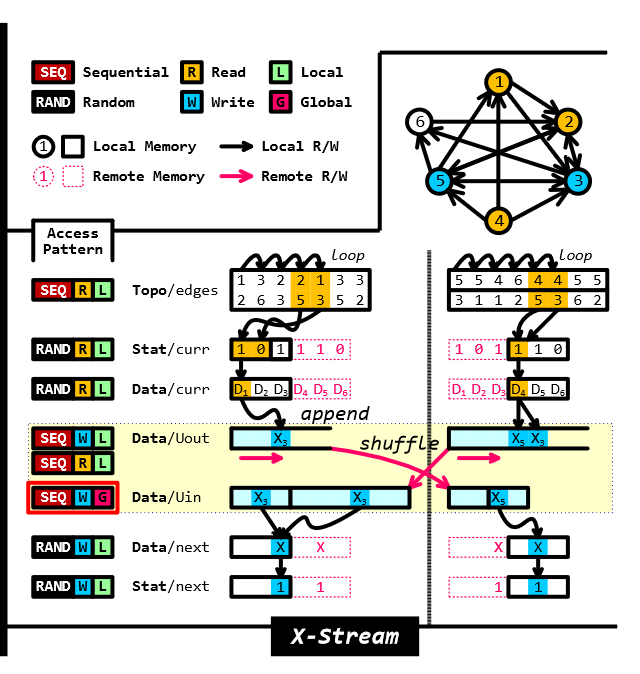
顺序的迭代边而不是点来避免对边的随机访问,引入了额外的洗牌阶段和“平铺策略”来改善对顶点的随机访问
Challenges and Issues
Issue 1: Data Layout
linux默认使用first touch策略来将虚拟页绑定到物理页。图分析分为图的构建和计算两个过程,在构建过程中多个NUMA节点的线程分配和初始化图数据,在计算阶段这些数据被计算线程访问,分配线程和计算线程不匹配,形成交错页面分配,造成大量远程和随机内存访问。
此外,短期内存数据结构(例如运行时状态)由主线程在每次迭代开始时分配和启动,并由每次迭代中来自 NUMA 节点的所有处理线程访问。这种集中分配不仅会导致过多的远程内存访问,还会导致互连和内存控制器拥塞
Issue 2: Access Strategy
即使是理想情况下的数据放置,由于遍历边时缺少局部性,也会出现不可避免的远程访问。我们观测到远程顺序访问比随机本地和随机远程有更高的带宽
在以顶点为中心的系统比如ligra中,尽管本地访问被组织为顺序,next or curr数据的远程访问和push pull的状态数组也是耦合的相应地随机顺序。更糟糕的是,绑定在不同处理器上的线程的并发远程访问将进一步导致互连拥塞。
在以边为中心的系统比如xstream中,每个核心可以独立的处理每个分区的scatter和gather,只有在shuffle阶段才会交换数据。尽管远程访问是顺序的,shuffle阶段可以造成额外的内存分配和远程拷贝开销。更糟糕的是,访问边的状态比点更难,因为边的数量比点高几个数量级。对于遍历算法来说其性能很差(e.g. SSSP),尤其是高直径图
Quantitive Performance and Scalability on NUMA
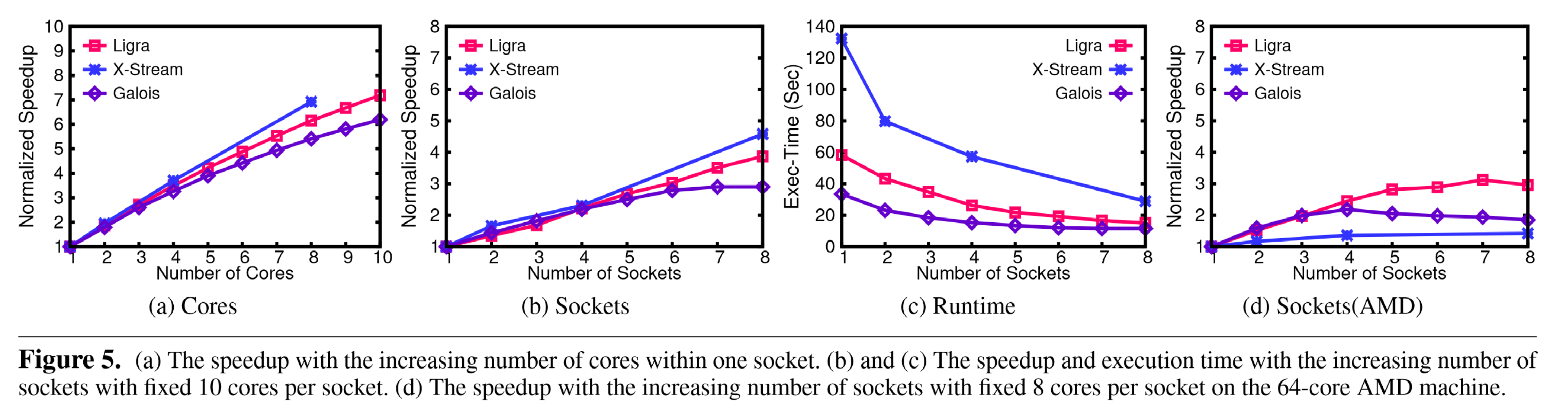
通过实验论证现存系统都是NUMA-oblivious的,其numa拓展性较差。
NUMA-Aware Graph-Analytics
Computation Model and Interface
Polymer 遵循典型的分散-聚集模型,提供了两个继承自 Ligra [43] 的接口:EdgeMap 和 VertexMap。 Polymer 中的图程序 P 同步运行在有向图 G = (V, E) 上,其中 V 是顶点集,E 是边集。对于无向图,它们的每条边都由一对有向边表示,每个方向一个。顶点 v 的拓扑数据包括一组入或出邻居(Nin(v) 或 Nout (v))及其入度或出度(|Nin(v)| 或 |Nout (v)|) 。 SubVertex 类型用于定义顶点 U ⊆ V 的子集。与大多数现有系统一样,Polymer 假设图拓扑在图计算期间是不可变的;如何扩展Polymer来支持可变拓扑是我们未来的工作
EdgeMap(G, A, F) : SubVertex
对于有向图G,EdgeMap对所有源顶点属于顶点集A的边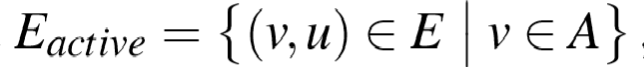
应用函数F,返回更新后的点集SubVertex 
VertexMap(G, A, F) : SubVertex
对所有属于点集A的点应用F,返回SubVertex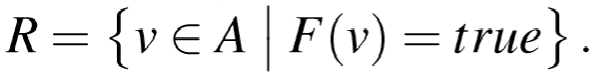
为了享受正确执行模式的优势,polymer也提供pull和push两种执行模式
Graph-Aware Data Structure and Layout
设计原则:尽可能的将数据和计算放在同一个numa节点,关键是利用图计算的独特访问模式来放置存内数据
NUMA-aware graph partitioning
polymer将存内数据结构P分为N个不相交的分区,把所有的点也分为N个分区,Ni属于Pi,边同理根据其源顶点或者目的顶点分为N个分区,Ei属于Pi
借用分布式系统中顶点复制的思想,引入轻量级的顶点复制,成为agents,代理只记录分区拓扑数据,例如边的起点和点的度数,其唯一作用是在节点内的主顶点上启动计算,基本上消除了访问应用程序定义的数据和运行时状态时的随机远程访问。由于大多数图的顶点数量远小于边数量,因此内存压力小

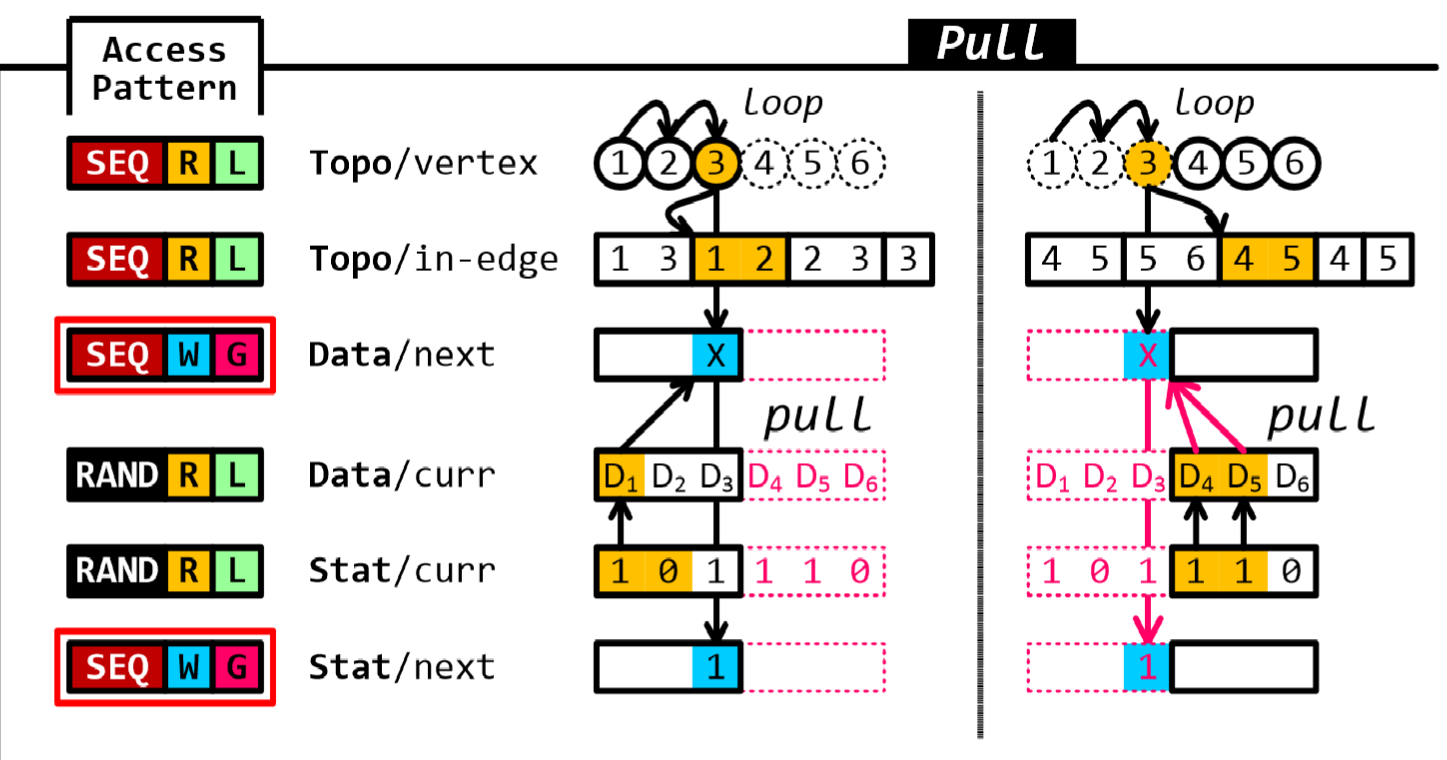

与之前的区别是每个节点内只存储对应分区节点的out-edge/in-edge,拓扑在本节点内,避免远程访问,执行时遍历本地顶点和代理来保证正确性;data也存在本地了
NUMA-aware allocation of graph data
为了避免因为first touch引起的随机或者交错访问,通过让第 i 个 NUMA 节点上的线程分配和启动分区 Pi 中的所有数据来解决分配线程和计算线程之间的不匹配问题。然而,简单地使用共置(co-location)可能会导致内存中数据的物理地址离散,这可能会导致间接访问的额外成本
为此,Polymer根据这些数据的内存访问行为,区分了它们的虚拟地址的放置策略
下表总结了polymer不同数据的放置策略
NUMA-Aware Graph Computation
即使在共置数据布局下,Polymer 仍然无法彻底消除远程访问以及访问其他分区拥有的相邻顶点时的随机访问。采用x-stream的shuffle是一种解决方案,但是会造成额外的开销,最终polymer借用分布式系统的思路,将计算分布在不同机器上,与分布式不同的是polymer的agent只复制拓扑数据,应用定义的数据仍然只有一个副本,通过共享内存同步。
每个NUMA节点的工作线程只执行所有顶点的部分计算,而不是部分顶点的所有计算。
以图六为例,第一个线程只push点3到本地顶点2,第二个线程push点3到他的本地顶点5和6,而在ligra中,会由第一个线程执行所有的任务。
在push模式下,相比于Ligra中局部顺序读取(SEQ|R|L)和全局随机写入(RAND|W|G)的组合,Polymer对源顶点的数据采用全局顺序读取(SEQ|W|G)。 R|G) 和目标顶点数据的局部随机写入 (RAND|W|L)。将原本随机的远程访问变为顺序的远程访问了。
由于更新的顺序相同,同一顶点可能会被不同NUMA节点上的多个工作线程同时或紧密更新,这可能会导致严重的争用和频繁的缓存失效。类似地,在推送模式下,同一 NUMA 节点拥有的附近顶点上的同时读取操作可能会导致互连和内存控制器拥塞。受到分布式图系统中处理消息的类似问题的解决方案的启发[12 ], Polymer 使不同 NUMAnode 上的工作线程以滚动顺序处理顶点,从自己的顶点开始。例如,第二个分区中的工作线程将从顶点 4 开始
Optimization on Polymer
Hierarchical and Efficient Barrier
由于缓存和内存的分层结构,不同核心上的线程之间的同步成本随着涉及的插槽数量的增加而迅速增加。这导致了对拓扑感知同步机制的必要性。默认的pthread_barrier使用统一的”flat”模型,使得不同核心上的所有参与者都等待一个全局共享变量,并陷入内核,这可能导致从节点内同步到节点间同步的性能降低一个数量级(30μs vs. 570μs)。
受到 Tiled-MapReduce [11] 中分层调度的启发,Polymer 设计了分层屏障。同一 NUMA 节点上的工作线程被分组以共享数据和计算任务的分区。所有工作线程首先在组内同步,然后每个组的最后一个线程将进一步跨组同步。随着涉及的套接字的增加,分层屏障可以明显减少缓存一致性广播。
主要原理是减少了跨socket的消息传递,由原来的所有线程通信变成每个socket只有一个线程互相通信。
然而pthread_barrier仍然会陷入内核,因此polymer基于fetch_and_add实现了sense_reversing集中式屏障
Balanced Partitioning
对于同步执行,进行负载均衡是至关重要的,socket内调度相对简单,因为其数据在同一分区并且内存访问是统一的,因此socket内是动态任务调度,每个线程动态的获取任务。
跨socket负载均衡,由于每个socket有自己的分区,负载均衡需要分区时任务分的均衡,由于图的幂律性,均匀分配点是不好的,受power graph的启发,以边为中心的分区方法
Adaptive Data Structures
Polymer 使用无锁树形结构查找表来表示运行时状态。表的每个叶分区都是一个位图,这对于大部分活动顶点来说是有效的。然而,由于大多数图算法收敛不对称,活跃顶点的比例将持续下降并达到零。每次迭代中遍历稀疏位图的开销都是不小的,导致性能显着下降,特别是对于高直径图的遍历算法。
受到 Ligra [43] 中解决方案的启发,Polymer 在树结构表中使用自适应数据结构来实现运行时状态,并根据活动顶点的比例自动切换叶分区的数据结构。与 NUMA 节点内所有工作线程共享的位图不同,不同核心上的每个线程将分配一个专用队列并向其附加活动顶点 ID,而不会发生争用。如果需要的话,当对顶点 ID 进行重复数据删除时,可以合并 NUMA 节点内的队列,或者链接到本地间接路由器阵列以形成两级树结构。最后,Polymer 使用活动顶点的总度数和应用程序定义的阈值来决定是否切换数据结构。
evaluation
实验
- PR
- SPMV
- BP
- BFS
- CC
- SSSP
PR SPMV BP访存敏感的应用polymer性能较好
BFS CC SSSP等迭代型访存较少的应用polymer效果不是最好,但仍然是最优或接近的性能,这得益于部分优化例如幂律图的平衡分区和高直径图的自适应数据结构
Ligra 的性能与 Polymer 相似。然而,由于其 NUMA 感知设计,Polymer 在大多数情况下都优于 Ligra。像 X-Stream 这样的以边为中心的系统,由于对边的过度访问和运行时状态的数据结构效率低下,其遍历算法的性能极差,特别是对于道路网络等高直径图。
可拓展性:Polymer for PageRank 的可扩展性比所有现有系统都要好得多。可扩展性比率甚至超过了套接字数量(即 12.1 与 8)。随着套接字数量的增加,总缓存的大小会增加,每个套接字的分区大小会减少,从而减少缓存未命中,从而实现超线性加速。
由于每次迭代中的活动顶点较少,BFS 的可扩展性在所有系统中都相对较差。然而,Polymer 仍然表现出更好的可扩展性,并且优于其他使用 8 插槽的现有系统。
Reduced Remote and Random Accesses
ageRank,如表 4(a) 所示,由于图数据和计算共置,Polymer 的远程访问无论是速率还是数量都少得多。此外,Polymer 中的远程访问是连续的,可将远程访问导致的 LLC 丢失率降低高达 70%(原为 55%)。对于 BFS,由于内存访问次数较少,改进空间有限,表 4(b) 中的结果仍然证实了 Polymer 的更好性能。
Memory Consumption
galois使用了自己的内存分配器,所以其效果最好,X-stream在shuffle阶段使用额外内存,其使用内存最多,Polymer和Ligra的内存消耗接近,都使用默认的内存分配器。除了roadUS 图(38.3%)之外,由于边与顶点的比率(2.43X)低得多,内存消耗的增加低于30%。
Hierarchical and Efficient Barrier
通过实验展示层次屏障和用户态屏障的好处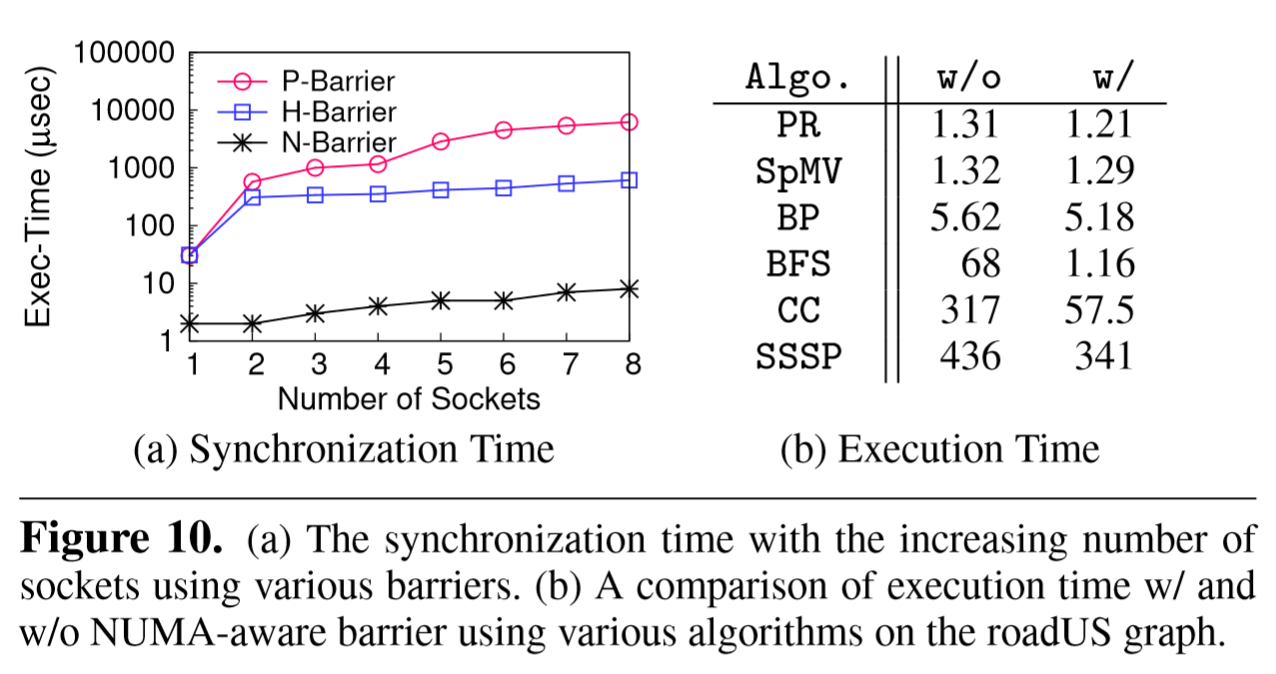
Adaptive Data Structure
为了研究自适应数据结构的好处,表 6(a) 比较了有和没有对 roadUS 图进行优化的各种算法在 Polymer 上的性能。因为主要的改进是在活动顶点很少时降低性能成本来检查运行时状态。对于稀疏矩阵乘法算法(PR、SpMV 和 BP),活跃顶点数相当稳定。数据结构的切换发生得较晚,甚至根本没有切换,因此改善有限,最多可达9%。相比之下,包括 BFS、CC 和 SSSP 在内的遍历算法可以显着受益于更高效的数据结构
Balanced Partitioning
带平衡的在拓展socket时其波动很小且平均执行时间减少。
API和ligra相同
 wechat
wechat alipay
alipay


