
X-Stream: Edge-centric Graph Processing using Streaming Partitions
SDM:Sharing-Enabled Disaggregated Memory System with Cache Coherent Compute Express Link
START
Basic
Streaming partitions使scatter和gather的自然单位
Size and Number of Partitions
流分区的大小,一方面要能够容纳顶点,另一方面,为了最大化对慢速存储(Slow Storage)的顺序访问,以加载流式分区的边列表和更新列表,需要尽量减少流式分区的数量。
在这里,作者将限制流式分区的顶点集大小相等,每个流分区的顶点集填满快速存储。
Out-of-core Streaming Engine
核外图处理引擎的输入是包含图的无序边列表的文件。此外,我们为每个流分区存储三个磁盘文件:每个文件用于顶点、边和更新。
在第二节中可以看到,以边为中心的GAS,GS都可以做到顺序访问,困难的是shuffle阶段的顺序访问,在核外版本中,将shuffle折叠到scatter,在scatter阶段,将更新附加到内存缓冲区,当缓冲区满,将更新列表分为不同流分区中的更新列表,将这些列表附加到磁盘中每个分区的更新列表文件中
In-memory Data Structures
内存中除了顶点,还需要一些数据结构来存放输入流等数据。为了避免动态内存分配的开销,使用静态大小且静态分配的数据结构:stream buffer,包含
- 一个很大的字节数组叫chunk array
- k个索引包含K个分区的K个条目
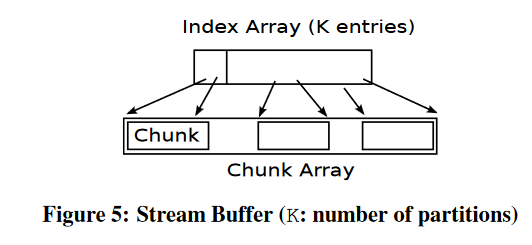
shuffle阶段使用两个stream buffer,一个存放scatter阶段产生的更新,另一个存储shuffle的结果
每次迭代在这两个buffer之间进行一次传输,第一个buffer满了以后对每个分区的更新进行计算,然后填充第二个buffer的索引,最后将更新复制到第二个buffer。
Disk I/O
X-stream绕过操作系统的页缓存,对stream buffer执行异步直接IO,为每个流分区使用额外的4K页对齐
在操作系统中,文件系统将磁盘上的数据划分为固定大小的块,称为页面(page)。当应用程序需要读取或写入文件时,文件系统将数据从磁盘读取到内存的页面缓存中,或者将内存中的页面写回到磁盘。页面缓存是内核为了加速磁盘I/O操作而维护的一部分内存区域。
页面缓存充当了磁盘和应用程序之间的缓冲区,它使读取和写入文件的操作更加高效。当应用程序请求读取文件时,如果所需数据已经在页面缓存中,则可以直接从内存中读取,避免了频繁的磁盘访问。类似地,当应用程序进行文件写入操作时,数据可以先写入到页面缓存中,然后由操作系统决定何时将数据写回磁盘,以提高写入的效率。
为输入分配一个额外的stream buffer来实现从磁盘的预取;为输出分配一个额外的stream buffer来实现计算scatter和写回磁盘的重叠
输入和输出的预取为1就可以实现磁盘100%的繁忙,如有必要可以使用更大的chunk array
In-memory Streaming Engine
存内系统考虑的主要是并行,需要所有可用内核才能达到内存的峰值带宽。第二点考虑是内存引擎必须比核外流引擎处理更多数量的分区。这就需要使用多级洗牌器
存内系统需要保证顶点全在cache中,但是我们无法显式的控制数据保存在cache中,因此将顶点占用空间计算为顶点数据大小、边大小和更新大小的总和。然后,它将图中所有顶点的总占用空间除以可用 CPU 缓存的大小,得出流分区的最终数量
我们首先将边缘加载到输入流缓冲区中,并将它们打乱为每个流分区的边缘块。然后,我们在分散阶段一一处理流分区,从流分区生成更新。所有生成的更新都附加到单个输出流缓冲区中。然后,输出流缓冲区被打乱为每个流分区的更新块,然后在收集阶段被吸收。
该引擎正好需要三个流缓冲区,一个用于保存图的边缘,一个用于保存生成的更新,另一个用于在洗牌期间使用。
Parallel Scatter-Gather
对于不同的流分区,流操作可以独立完成,基于此并行化scatter和gather
每个线程首先写入一个私有缓冲区(大小为 8K),该缓冲区将刷新到共享输出块数组,首先以原子方式在末尾保留空间,然后附加私有缓冲区的内容。并行执行流分区可能会导致严重的工作负载不平衡,因为分区可能分配有不同数量的边。因此,我们在 X-Stream 中实现了工作窃取,允许线程彼此窃取流分区。
Parallel Multistage Shuffler
存内引擎的分区数量比核外更多(cache太小)。大量分区对利用内存顺序访问带宽的设计目标带来了挑战
顺序访问高带宽的原因有二
- 硬件预取
- cache局部性的充分利用
这两者当分区数量提高时都面临挑战,针对此构建多级shuffler,将分区组合为树层次结构,将流分区数量强制为2的幂,将树的fanout设置为2的幂
为了实现在多级洗牌器中并行,对流缓冲区切片,每个线程只接受一个切片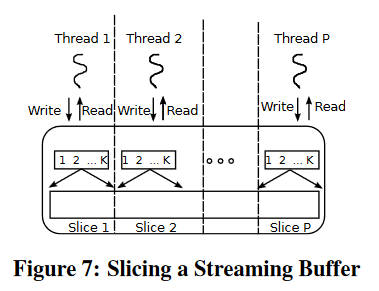
Layering over Disk Streaming
内存引擎在逻辑上位于核外引擎之上。我们通过允许磁盘引擎独立选择其流分区的数量来实现这一点。加载的输入块都会使用内存引擎进行处理,然后该引擎会为当前磁盘分区独立选择进一步的内存分区。
Evaluation
使用合成和真实世界(图 10)图形数据集来评估 X-Stream。我们使用 RMAT 生成器 [23] 生成合成无向图,并使用它们来研究 X-Stream 的缩放特性和评估配置选择。 使用术语“尺度 n”来指代具有 2n 个顶点和 2n+4 个边的合成图。
可用性:我们得出的结论是,X-Stream 是在现实世界的图上执行各种算法的有效方法,其唯一的限制是其结构需要大量迭代的图。
拓展性:X-Stream 从无序边列表开始这一事实意味着它可以轻松处理不断增长的图 总之,X-Stream 可以以很少的开销吸收新的边,因为它支持对具有新添加的边的图进行高效的重新计算。
对比ligra:BFS比ligra慢,但是ligra预处理花的时间长。PageRank ligra无法方向反转,所以比xstream慢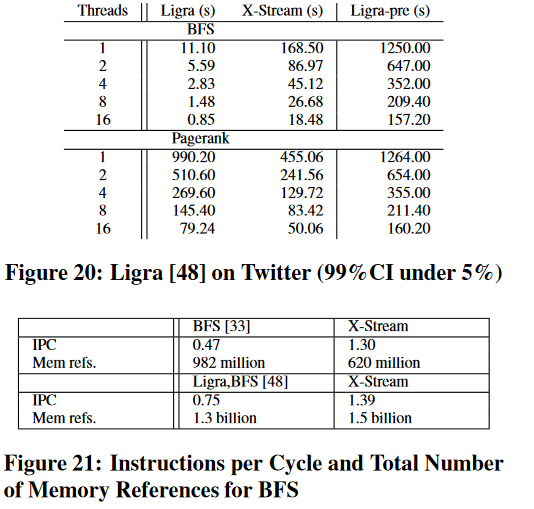
IPC更高:X-Stream 中较高的 IPC 是由于解决内存访问的延迟较低,这是因为顺序访问允许预取器隐藏一些内存访问延迟
Back: you have read it ! Tags: graph processing system END
 wechat
wechat alipay
alipay


