
Demystifying CXL Memory with Genuine CXL-Ready Systems and Devices
START Basic
# Demystifying CXL Memory with Genuine CXL-Ready Systems and Devices - CXL性能分析 - 内存带宽敏感性应用能够从CXL内存中受益 - CXL内存感知动态页分配策略caption来更加高效的利用CXL作为带宽拓展器。与为传统 NUMA 系统设计的默认页面分配策略相比,Caption 可以自动收敛到经验上有利的页面分配比例,从而将内存带宽密集型应用程序的性能提高高达 24%。EVALUATION SETUP
System and Device
server:two Intel Sapphire Rapids (SPR) CPU sockets一个socket有 eight 4800 MT/s DDR5 DRAM DIMMs (128 GB) across eight memory channels. 另一个socket is populated with only one 4800 MT/s DDR5 DRAM DIMM to emulate the bandwidth and capacity of CXL memory.
每个Intel SPR CPU有四个chiplets,每个有15个核心和两个DDR5 DRAM。用户可以把这四个chiplets看作一个完整的CPU,也可以在SNC模式下将每个chiplet看作一个numa
device:
三个FPGA,两个硬IP一个软IP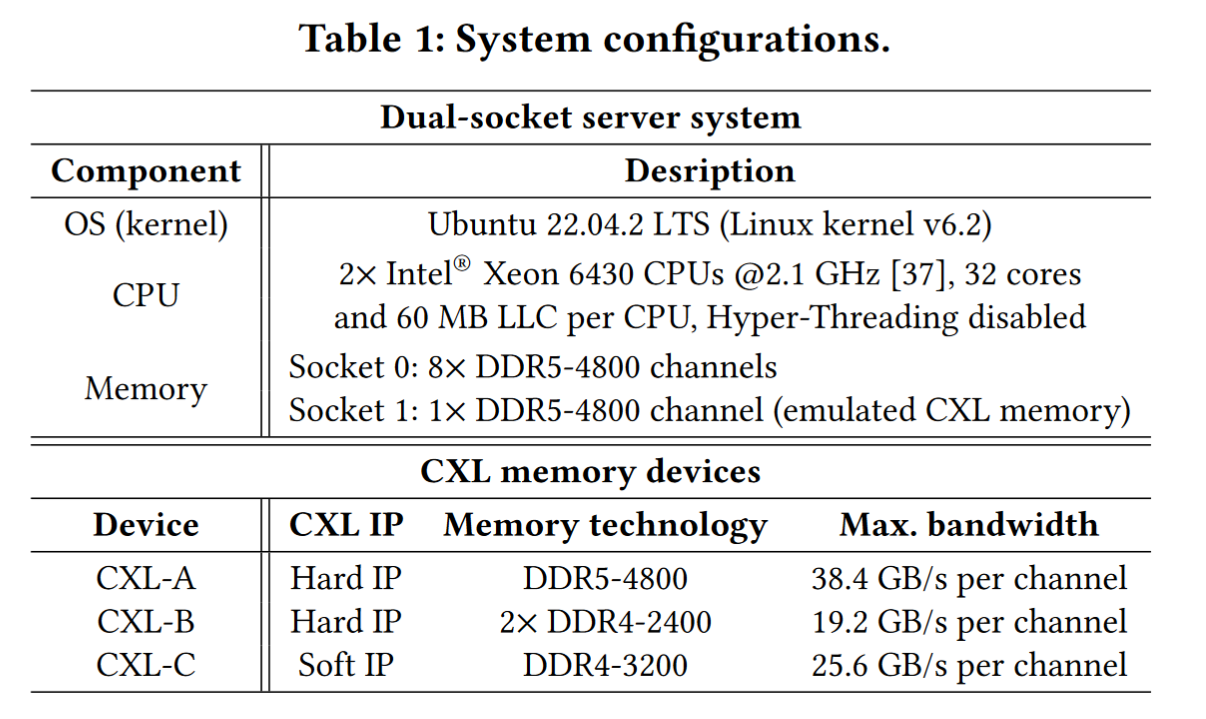
Microbenchmark
- MLC
- MEMO(measuring efficiency of memory subsystems)
Benchmark
延迟敏感的应用
Redis
DeathStarBench (DSB)它使用 Docker 启动微服务的组件,包括机器学习 (ML) 推理逻辑、Web 后端、负载均衡器、缓存和存储
体来说,我们评估了三种 DSB 工作负载:(1) 撰写帖子,(2) 读取用户时间线,以及 (3) 混合工作负载(10% 撰写帖子、30% 阅读用户时间线和 60% 阅读主页时间线)作为社交网络框架。
FIO一种开源工具,用于对存储设备和文件系统进行基准测试,以评估使用 CXL 内存作为操作系统页面缓存的延迟影响。
吞吐量应用
首先,我们运行一个基于深度学习推荐模型(DLRM)的推理应用程序,其设置与 MERCI [58] 相同
其次使用SPECrate CPU2017 套件
MEMORY LATENCY AND BANDWIDTH CHARACTERISTICS
图一是MLC的指针追逐测得的延迟
图二是MEMO,分别是(1) temporal load (ld), (2) non-temporal load (nt-ld), (3) temporal store (st), and (4) non-temporal store (nt-st).非局部性non-temporal 即不过cache
关于延迟的观察
(O1) 全双工 CXL 和 UPI 接口减少了内存访问延迟。 memo 使模拟 CXL 内存的 ld 延迟比 Intel MLC 低 76%。出现这种差异的原因是 Intel MLC 的串行化内存访问无法利用连接 NUMA 节点的 UPI 接口的全双工功能。相比之下,memo 的随机并行内存访问可以通过全双工 UPI 接口并行发送内存命令/地址并接收数据。有效地将通过 UPI 接口的平均延迟成本减半。由于真正的 CXL 内存也基于全双工接口(即 PCIe),因此它具有与模拟 CXL 内存相同的优势
(O2) 访问真正的 CXL 内存设备的延迟高度依赖于给定的 CXL 控制器设计
(O3) 模拟 CXL 内存可以提供比真实 CXL 内存更长的内存访问延迟。
当向模拟 CXL 内存发出内存请求时,本地 CPU 必须首先检查通过芯片间 UPI 接口连接的远程 CPU 的缓存一致性 [62, 66]。此外,内存请求必须通过远程 CPU 内的长芯片内互连才能到达其内存控制器 [83]。这些开销随着 CPU 内核的增加而增加,即更多的缓存和更长的互连路径。
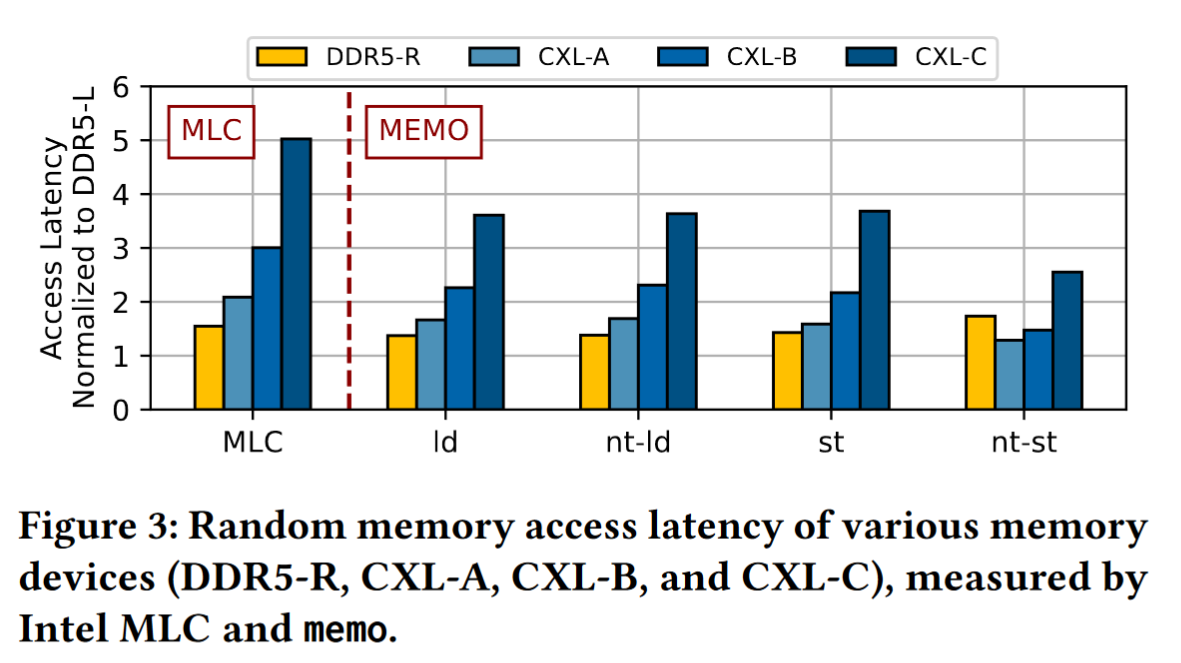
关于带宽的观察
因为不通设备的带宽不同,使用带宽效率作为统一的标准,将测量的带宽标准化为理论最大带宽
(O4) 带宽很大程度上取决于 CXL 控制器的效率
(O5) 与模拟 CXL 内存相比,真正的 CXL 内存可以为存储提供有竞争力的带宽效率。
Interaction with Cache Hierarchy
INTEL的non-inclusive cache architecture
假设具有非包容性缓存架构的 CPU 内核发生 LLC 未命中,需要由内存提供服务。然后,它将数据从内存加载到 CPU 核心(私有)L2 缓存而不是(共享)LLC 中的缓存行中,当驱逐L2缓存中的缓存行时,CPU核心会将其放入LLC中。
在SNC模式下,如果L2上的数据来源于SNC node上的DDR,当L2上的缓存行被驱逐时,不是放入随便的LLC,而是只能放到属于SNC节点的LLC中
然而当数据来自远程内存时,可以放到任意的LLC中
CPU 内核访问 CXL 内存会破坏 SNC 模式下 SNC 节点之间的 LLC 隔离。这使得此类 CPU 内核受益于比访问本地 DDR 内存的内核大 2-4 倍的 LLC 容量,特别是补偿了 CXL 内存较慢的访问延迟。
(O6) 与本地 DDR 内存相比,CXL 内存与 CPU 缓存层次结构的交互方式不同
指的是在SNC模式下访问CXL会打破LLC隔离
IMPACT OF USING CXL MEMORY ON APPLICATION PERFORMANCE
延迟
redis:TPP没啥卵用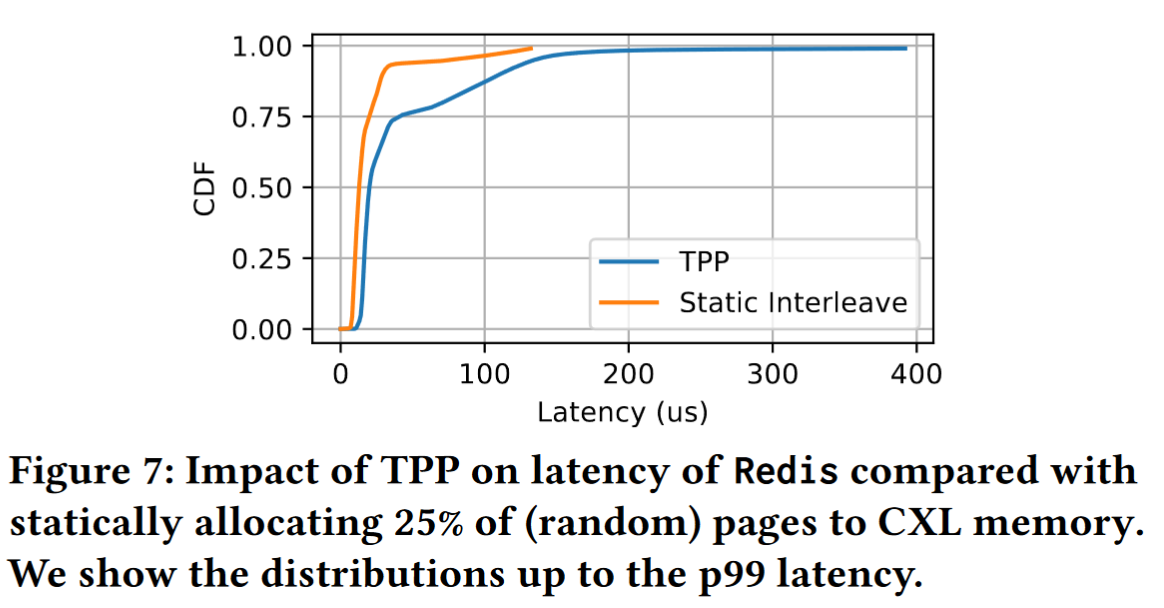
DSB:对延迟不敏感
FIO:
吞吐
DLRM
当 100% 的页面分配给 DDR 内存时,超过 20 个线程就会开始饱和。这种情况下,我们观察到将一定比例的页面分配给 CXL 内存可以进一步提高吞吐量,因为它补充了 DDR 内存的带宽,增加了 DLRM 可用的总带宽。
Redis
尽管Redis是一个对延迟敏感的应用程序,但其吞吐量也是一个重要的性能指标。图 9b 显示了分配给 CXL 内存的不同页面百分比的最大可持续 QPS。例如,对于 YCSB-A,将 25%、50%、75% 和 100% 的页面分配给 CXL 内存所提供的吞吐量比将 100% 的页面分配给 DDR 内存低 8%、15%、22% 和 30% 。由于Redis没有充分利用内存带宽,其吞吐量受到内存访问延迟的限制。因此,类似于其 p99 延迟趋势(图 6a),向 CXL 内存分配更多页面会降低 Redis 的吞吐量。
CXL-MEMORY-AWARE DYNAMIC PAGE ALLOCATION POLICY
作者提出了将CXL作为内存拓展器,可以提高带宽密集型应用程序的性能。如果给定应用程序的吞吐量受到带宽的限制,则将较高百分比的页面分配给 CXL 内存可以减轻 DDR 内存上的带宽压力,从而减少平均内存访问延迟。
对带宽受限型分配比较多的CXL页面,对非带宽受限型,应当少分配写cxl页面
我们提出了 Caption,一种动态页面分配策略。 Caption 根据三个因素自动调整操作系统分配给 CXL 内存的新页面的百分比:(1) CXL 内存的带宽能力,(2) 共同运行应用程序的内存密集度,以及 (3) 平均内存访问延迟。Caption重点关注DDR内存和CXL内存之间的页面分配比例,与TPP正交且互补。
Caption 由三个运行时模块组成(图 10)。 (M1)定期监视一些与内存子系统性能相关的CPU计数器,然后(M2)根据计数器的值估计内存子系统性能。当给定应用程序请求分配新页面时,(M3) 调整分配给 CXL 内存的新页面的百分比
CONCLUSION
在本文中,我们首先分析了真正的 CXL 内存的设备特定特性,并将其与基于 NUMA 的仿真(CXL 研究中的常见做法)进行了比较。我们的分析揭示了模拟 CXL 内存和真实 CXL 内存之间的关键差异,并对性能产生重要影响。我们的分析还发现了有效使用 CXL 内存作为内存带宽密集型应用程序的内存带宽扩展器的机会,这导致了 CXL 内存感知动态页面分配策略的开发并证明了其功效。
Back: you have read it ! Tags: cxl END
 wechat
wechat alipay
alipay


