
Improving key-value cache performance with heterogeneous memory tiering:A case study of CXL-based memory expansion
START Basic
Improving key-value cache performance with heterogeneous memory tiering:A case study of CXL-based memory expansion
TL;DR:提出了基于CXL的内存拓展原型和软件开发套件,并在此基础上开发KV应用。
KV是非常重要的应用,常作为缓存,保证高命中率十分重要,主要依靠 DRAM 来实现最佳性能。DRAM无法完全满足需求,向DRAM以外的内存拓展系统发展。
我们为键值缓存提供了两种不同的内存系统架构:透明分层和数据分层。在透明分层中,DRAM 和 CXL 内存作为统一内存层共存,而数据分层将 DRAM 和 CXL 内存区分为单独的内存层。特别是,我们应用这些内存系统架构来优化 Meta 的 CacheLib,这是 Meta 开发的开源进程内缓存引擎
主要贡献
- 开发接近商业性能的 CXL 内存扩展器原型和 HMSDK,提供两种编程模型:1) 操作系统级控制和 2) 应用程序级控制。
- 数据中心键值缓存工作负载内存分层的详细增强:1) 高性能,2) 高命中率。
- 引入了两种针对键值缓存量身定制的不同内存优化方法:1) 透明分层和 2) 数据分层,并附有指导原则,可帮助根据工作负载特征选择最合适的方法。
- 通过 CXL 内存扩展改进键值缓存的全面性能分析,利用数据中心环境中常见的各种实际工作负载。
利用所提出的 CXL 2.0 内存扩展器解决方案,可以增加整体系统带宽,从而使吞吐量性能最多提高 15%,延迟最多减少 9%。从容量方面进行比较,相同容量的 DRAM 和 CXL 内存具有相同的吞吐量值和相似的命中率,这表明 CXL 内存是 DRAM 的可行替代品。此外,通过采用更大容量的CXL内存,RAM缓存面积增大,从而带来更高的吞吐量和命中率
提出了一套基于CXL2.0的内存拓展原型和异构内存软件开发套件
HMSDK
异构内存软件开发套件 (HMSDK) Linux 内核将每个 CXL 内存模块识别为单独的纯内存 NUMA 节点 [17]、[18]。为了有效管理跨 NUMA 节点(包括 CXL 仅内存 NUMA 节点)的内存分配,我们开发了 HMSDK。 HMSDK 提供两种不同的编程模型,并支持新颖的内核内存分配策略。
编程模型。 HMSDK[10]为应用程序开发人员提供了两种利用CXL内存的方式:1)操作系统级控制和2)应用程序级控制。操作系统级别的控制允许开发人员快速部署CXL内存,而无需依赖操作系统修改其应用程序。另一方面,应用程序级控制允许开发人员直接在其应用程序中管理 CXL 内存,从而提供更大程度的定制。
MEMORY SYSTEM ARCHITECTURE
透明分层 透明分层使用 HMSDK 的操作系统级控制将 DRAM 和 CXL 内存视为同一内存层。当基于交错权重值确定NUMA节点分配比例时,整个系统的内存带宽通过带宽感知页面交错从DRAM扩展到DRAM和CXL内存。图7(a)展示了CacheLib RAM Cache模式下系统内存带宽扩展的过程。
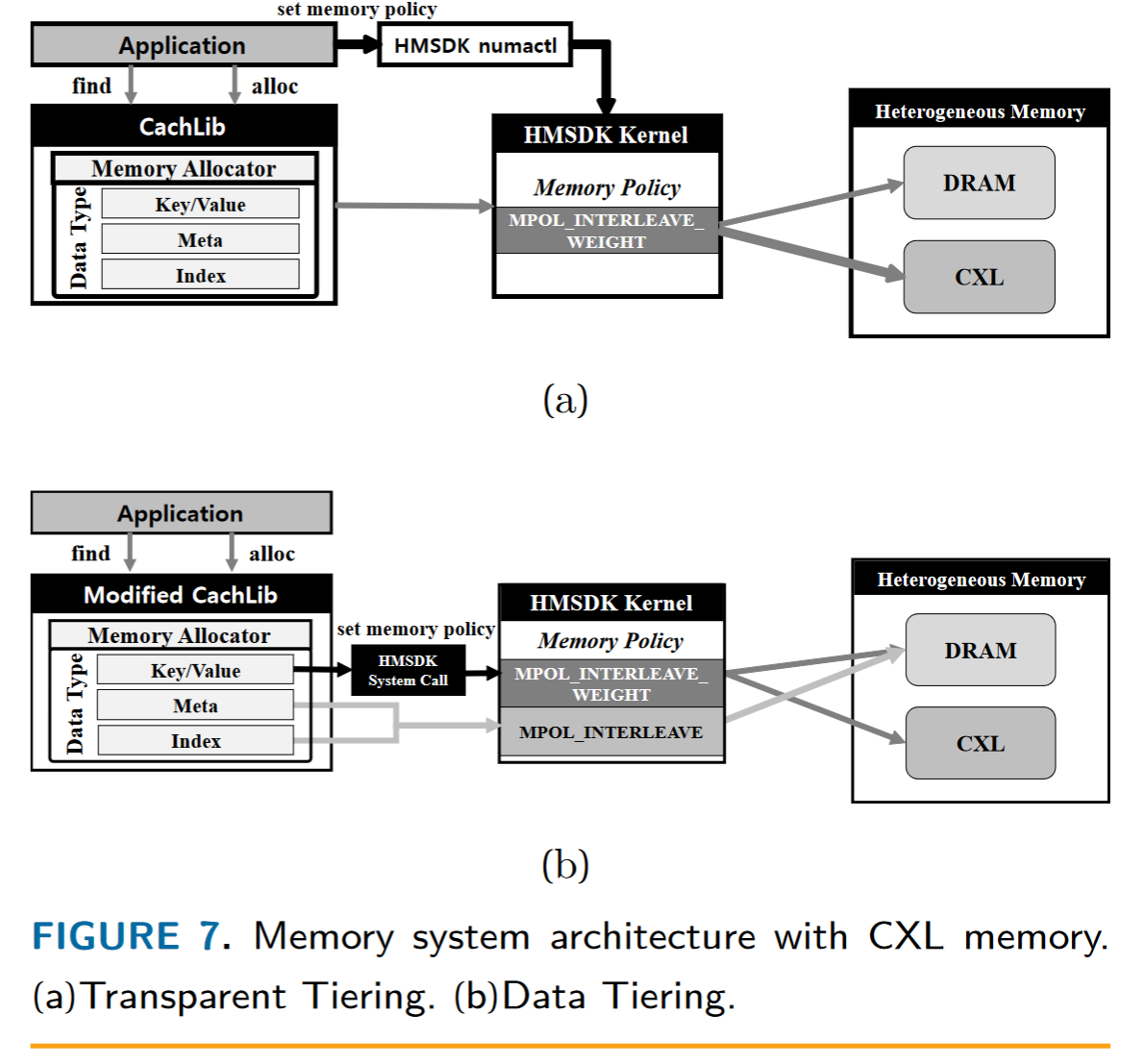
数据分层
数据分层架构通过将元数据和索引存储在 DRAM 中以及将键值存储在 CXL 内存中或两者都存储来解决此问题,具体取决于对象的带宽要求。
评估
关注图分析
CDN 相比,图服务工作负载由小对象(10B 到 10KB)组成,并且需要较低的带宽和容量。
我们使用了 Graph Follower 工作负载。对于 Graph Follower 工作负载实验,我们在 RAM 缓存模式下部署了三个 CacheLib 引擎,命中率为 95%,缓存大小为 40GB。每个引擎利用 20 个核心并在单个套接字服务器上并行工作。我们的结果显示,CPU 的利用率为 55%,DDR 内存(带宽为 40GB/s)的利用率为 16%。由于 DRAM 带宽足以满足 Graph Follower 工作负载,因此 CXL 内存不会产生带宽扩展效应。此外,Graph Follower 工作负载中小于 4KB 的大量数据通常不会分区到 DRAM 和 CXL 内存。在这种情况下,由于 CXL 内存的带宽较低(40GB/s),系统可能会遇到性能瓶颈。不过,使用CXL内存可以节省DRAM成本。我们分析了当主要数据大小小于 4KB 时添加 CXL 内存对性能的影响,并确定了我们提出的内存架构的 DRAM 总容量和性能之间的权衡
总结
提出了基于CXL的内存拓展原型和软件开发套件,并在此基础上开发KV应用。提出了透明分层和数据分层两种内存系统架构,并将其应用到Meta的缓存系统中。证明了 CXL 内存可以提高包含多个带宽密集型或容量消耗型工作负载的缓存系统的服务质量
Back: you have read it ! Tags: cxl END
 wechat
wechat alipay
alipay


