
EMS-i: An Efficient Memory System Design with Specialized Caching Mechanism for Recommendation Inference
START Basic
# EMS-i: An Efficient Memory System Design with Specialized Caching Mechanism for Recommendation Inference TL;DR: ## 1 INTRODUCTION DLRM 对于大规模嵌入表不规则和稀疏的数据访问模式导致内存带宽利用率低和缓存中的数据局部性差。 一些先前的工作[15,33,37]通过直接使用近数据处理(NDP)解决方案来增加内存带宽来加速DLRM的推理。其他工作[2]尝试通过使用定制的软件管理缓存技术来提高数据局部性,例如,在缓存中保留频繁访问的嵌入向量。 然而,所有这些工作都有一些突出的弱点:例如,在 NDP 解决方案中,DRAM 或 SSD 内部架构的重大变化导致研发 (R&D) 成本高昂,并可能潜在增加制造成本。此外,仅使用 DRAM 来存储数百/数千 GB 的嵌入向量会导致较高的内存成本,因为 DRAM 芯片比 SSD 贵得多。虽然基于SSD的NDP平台内存成本较低,但有限的I/O带宽和较低的计算能力导致推理延迟较高。此外,当前NDP加速器的存储器层次结构仅具有驻留在DRAM或NAND闪存芯片上方的小型一级缓存。较差的内存层次结构无法充分利用 DLRM 工作负载的数据局部性。 在软件管理缓存的解决方案中,当发生缓存未命中时,通常需要主机CPU运行相应的算法来维持自定义的缓存策略。因此,除了 DRAM 或 SSD 访问的延迟之外,缓存未命中损失还包括算法的执行时间(~10 ms)以及主机 CPU 和加速器之间的通信延迟(~100ns)。通过将批量大小增加到一个大值(例如 2048 或更大)来训练 DLRM 期间,缓存未命中的总延迟可能会重叠,以仅提高吞吐量 [5,20,25]。然而,训练中采用的方法对于 DLRM 的推理是不可接受的,其中批量大小不能很大 [15, 37](通常不大于 64),因为要同时考虑推理延迟和推理吞吐量 为了解决先前工作中的问题,我们提出了 EMS-i,这是一种高效的内存系统设计,具有专门的缓存机制和用于推荐系统推理的推理内核。 EMS-i的内存系统基于FPGA上的内存组件(URAM/BRAM/HBM)和SSD的组合,实现了内存成本和DLRM推理性能之间的最佳点。 为了将SSD集成到我们的内存系统中,我们采用Compute Express Link(CXL)[7]来扩展内存空间,并在FPGA上构建一个由主机内存、SSD和HBM组成的统一内存空间。主要贡献
- 我们提出了EMS-i,这是一种基于两个CXL 器件、一个支持HBM 的FPGA 和一个SSD 的推荐系统的高效内存系统设计。
- 我们专注于缓存机制,包括精密的硬件缓存控制器以减少流行嵌入向量的驱逐以及缓存替换粒度的灵活调整。
- 我们根据嵌入向量的相关性开发了一种新颖的预取机制。
- 考虑到SLS 操作中的多级并行性,我们开发了高效的推理内核和定制的映射方案来处理DLRM 推理。
实验结果表明,EMS-i 比最先进的基于 SSD 的 NDP 解决方案 RecSSD 实现了高达 10.9 倍的加速。 EMS-i 还实现了与 DRAMonly 加速器 RecNMP 相当的性能,并且节能 72%。在内存成本方面,EMS-i 的成本效益分别比 RecSSD 和 RecNMP 高 8.7 倍和 6.6 倍。
4 DESIGNOFEMS-I
通过CXL将FPGA和SSD集成起来,用于推荐模型的推理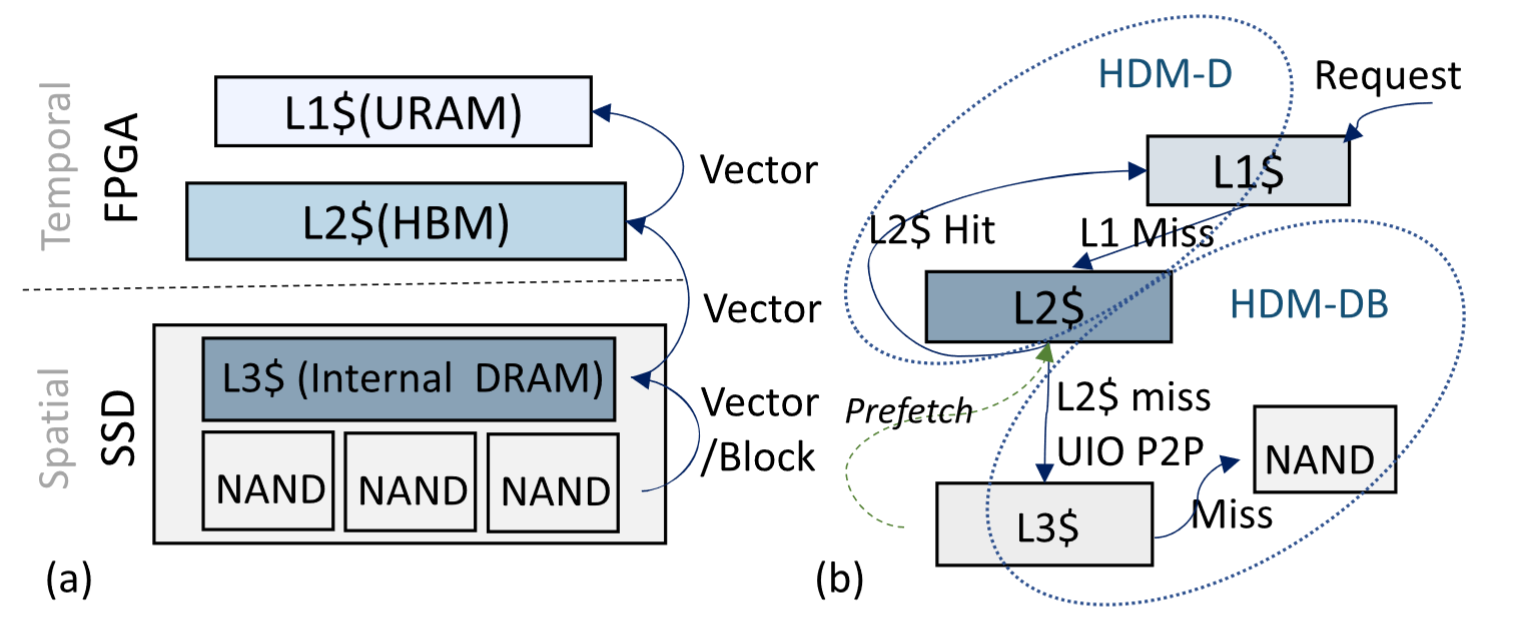
URAM作为L1 HBM作为L2 SSD的DRAM作为L3
L1和L2缓存的替换粒度都是“Vector”,而L3缓存的替换粒度可以根据不同的数据集调整为“Vector”或“Block”。
图b描述了缓存结果和数据流,FPGA和SSD通过UIO通信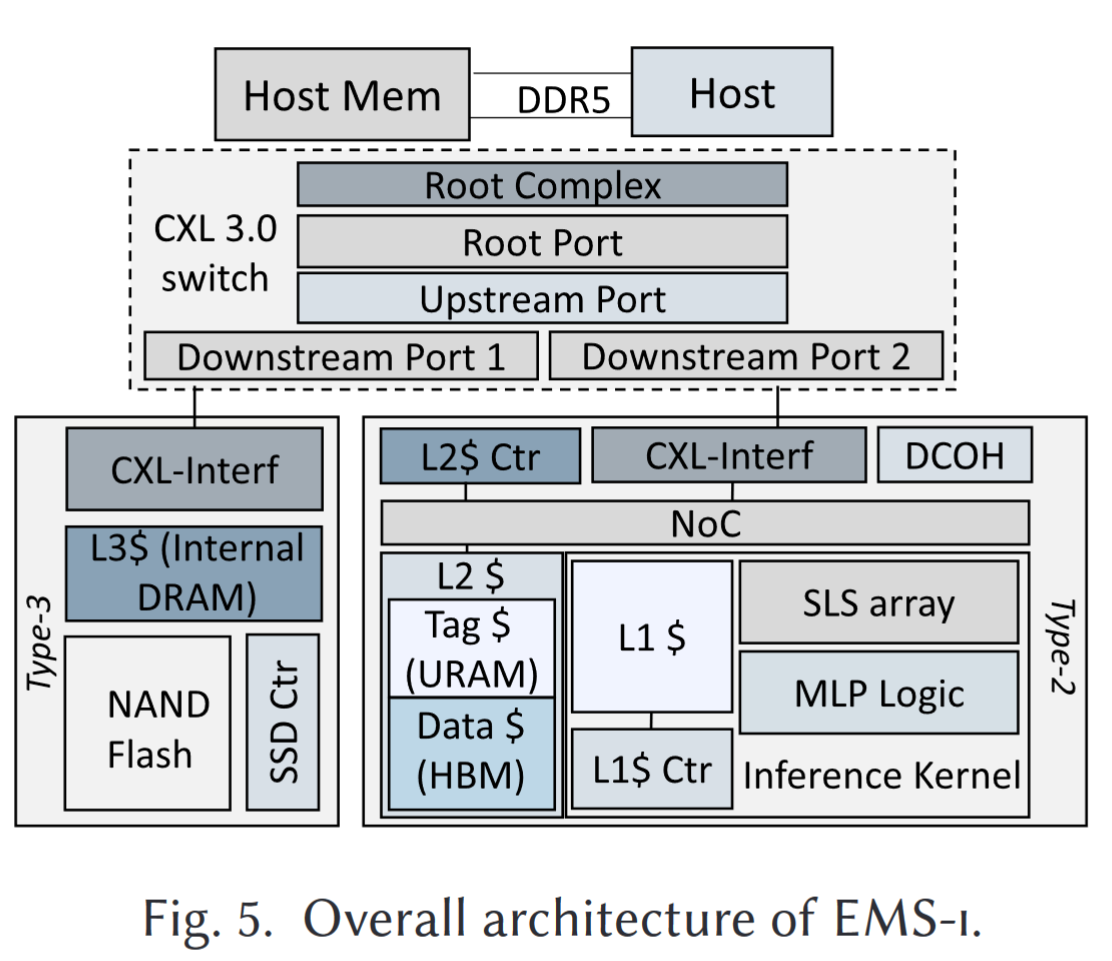
7 CONCLUSION
我们提出了 EMS-i,这是一种高效的内存系统,包括各种内存资源和多级缓存。 EMS-i专为DLRM推理而定制,具有精心设计的推理内核和专门的缓存和预取机制。总体而言,EMS-i 在执行延迟、节能和内存成本方面优于 SOTA NDP 解决方案。
Back: you have read it ! Tags: cxl END
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 wechat
wechat alipay
alipay
Related Articles

Comment

