
HME: A Lightweight Emulator for Hybrid Memory
START Basic
# HME: A Lightweight Emulator for Hybrid Memory TL;DR: ## Ⅰ. INTRODUCTION NVM硬件不可用,现有的模拟平台存在种种问题 - Gem5 - Zim - Intel Persistent Memory Emulation Platform (PMEP) - Quartz 本文提出HME,不专注于准确的模拟内存访问的细节,而是专注于模拟带宽和延迟带宽限制类似PMEP和Quartz,用DRAM thermal control interface控制(intel CPU支持)。定期注入额外的软件创建的延迟(NVM 和 DRAM 延迟之间的差异)来模拟 NVM 延迟。
II. NVM EMULATION MODELS
令 RDi 表示在给定时间间隔 i 内应注入的总读取延迟,NVM r 和 DRAMr 分别表示平均 NVM 和 DRAM 读取延迟,M i 表示间隔 i 内的内存访问总数。等式1描述了计算附加延迟RDi的基本模型,其中M i 是我们需要在时间间隔i内计数的唯一关键参数。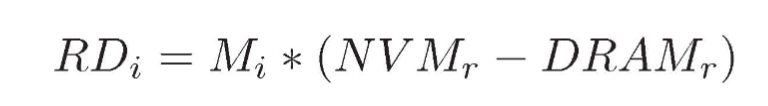
当前的商用 CPU 提供硬件性能计数器来监控 LLC 未命中。在每个给定间隔结束时,HME 读取硬件性能计数器并计算额外延迟,然后停止应用程序的 CPU 以注入软件创建的延迟。
实际上,aLLC 未命中通常伴随着页表遍历,这会消耗更多时间来访问主存储器中的页表条目。因此,我们改进了公式 2 中的 NVM 延迟仿真模型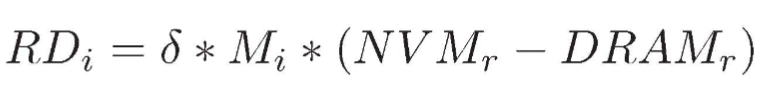
其中第一个系数是主要与应用程序的LLC未命中率相关的系数。可以通过对各种工作负载执行大量实验并使用线性回归等先进学习技术对其进行建模来估计其价值。
由于内存写操作不在应用程序执行的关键路径上,因此由于现代 CPU 上的回写式缓存和推测指令执行,应用程序无法感知它们。
为了模拟 NVM 写入延迟,我们通过使用 Intel Xeno CPU 中的性能监控单元 (PMU) 和模型特定寄存器 (MSR) 来监控 NVM 直写和回写的次数,并计算由内存写入引起的 CPU 停顿时间。令 WDi 表示在给定时间间隔 i 内应注入的总写入延迟,Mi 和 Ni 表示间隔 i 内 NVM 上的内存写通和写回操作总数,Δwtl 和 Δwbl 表示分别注入直写和写回延迟(NVM 和 DRAM 写入延迟之间的差异)。 NVM写入的注入延迟可以计算如下: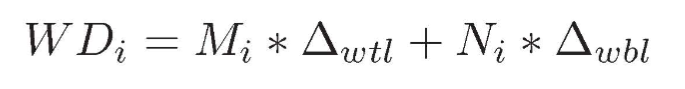
III. HME IMPLEMENTATION

们采用 NUMA 架构来模拟双路服务器上的混合内存系统。 NUMA 架构支持本地 DRAM 的普遍使用,同时在远程套接字上提供更高的 DRAM 访问延迟。我们在远程 NUMA 节点上使用 DRAM 来模拟更高延迟和更低带宽的 NVM。
如图 1 所示,我们选择远程套接字(节点 1)处的一个core 来计算应注入到本地套接字(节点 0)上运行的应用程序的额外延迟。
不使用远程套接字上的其他核心,以避免对计算核心的性能干扰。 HME 使用 非计算核心的 Intel Xeon 处理器 [16] 的PMU(性能监控单元)中的 Home Agent(HA)来记录对节点 1 上 DRAM 的内存读取访问(LLC 未命中)和写入访问的次数,并且这些内存请求应该是从节点 O 上运行的应用程序发出。HME 通过处理器间中断 (IPls) 向节点 0 的核心注入额外的延迟。通过这种方式,HME 增加了远程内存访问延迟来模拟 NVM 延迟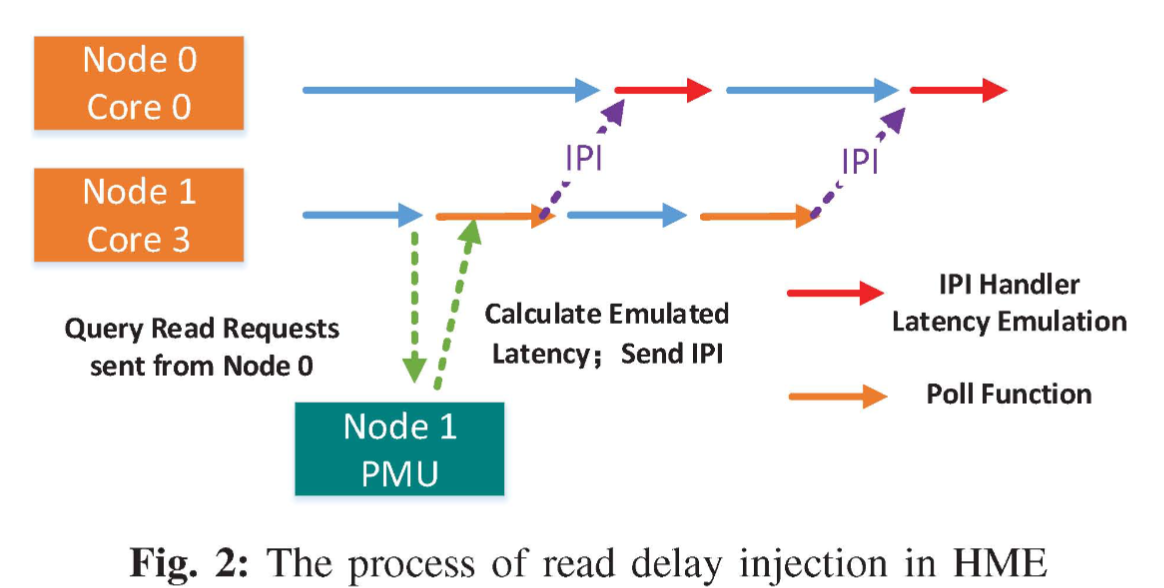
读延迟注入的流程如图2所示。程序运行在Node 0的Core 0上,而Node 1的Core 3则模拟NVM。当程序访问远程 DRAM(即模拟 NVM)时,Core 3 会调用 apoll 函数。它定期读取节点1上的PMU寄存器,并获取轮询周期内Core 0访问远程内存的次数。之后,Core 3计算模拟延迟并通过IPls将延迟注入到Core 0,这会导致 CPU 空转,从而产生模拟 NVM 读取延迟的软件延迟。
总结下:通过IPIs一个处理器向另一个处理器发送中断来增加延迟,通过PMU中的HA来记录内存读取数,并凭借此来决定增加多少延迟。
Model Specific Registers (MSR) [18] and PMU模拟NVM写延迟
由于每个核心的 MSR 无法被其他核心访问,因此应用程序的核心会定期中断以读取其 MSR 计数器,然后将此信息发送到远程套接字以计算写入延迟。这些中断可能会减慢应用程序的执行速度。
此外,由于硬件计数器仅记录socket上的LLC逐出总数,因此我们无法确切知道回写的LLC逐出来自哪个核心。为此,我们将写入延迟平均分配到每个核心上。我们认为这也是这种方法的局限性。如果处理器供应商将来提供更丰富的性能计数器,这个问题就可以得到解决。
我们使用集成内存控制器 (IMC) 非核心 PMU 和第 II-B 节中描述的模型来模拟 NVM 带宽。我们限制内存控制器在一个时隙中可以处理的内存访问指令的数量,以控制 NVM 带宽。我们还为用户提供了一套带宽控制API。
IV. NVM PROGRAMMING INTERFACE
开发了AHME,一台API,提供了粗粒度的numactl和细粒度的malloc/nvm_malloc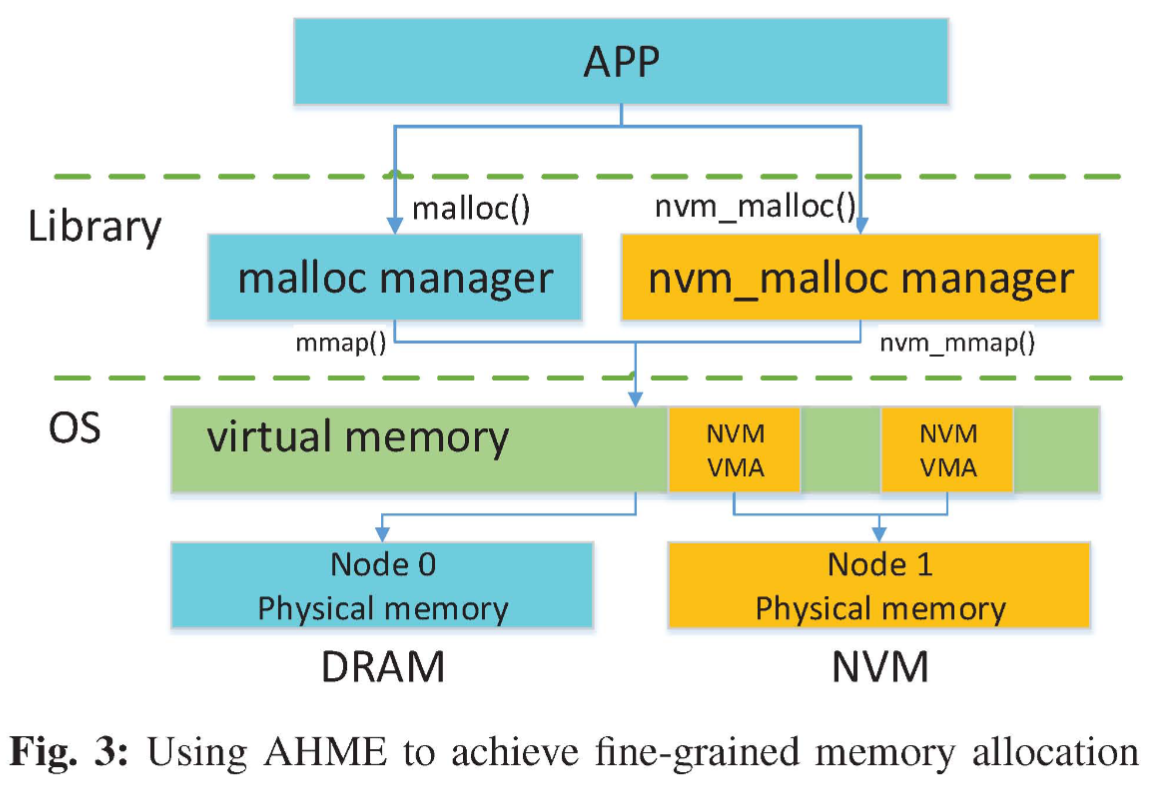
我们修改Linux内核,为nvm_mmap内存分配提供分支。该分支处理 nvm_malloc 函数中的过程分配。同时,NVM页面和DRAM页面在VMA(virtual address space)中不同。AHME 在 VMA 中标记 NVM 标志,并在页面错误时调用指定的 do_nvmpage_fault 函数来分配远程 NUMA 节点上的物理地址空间。
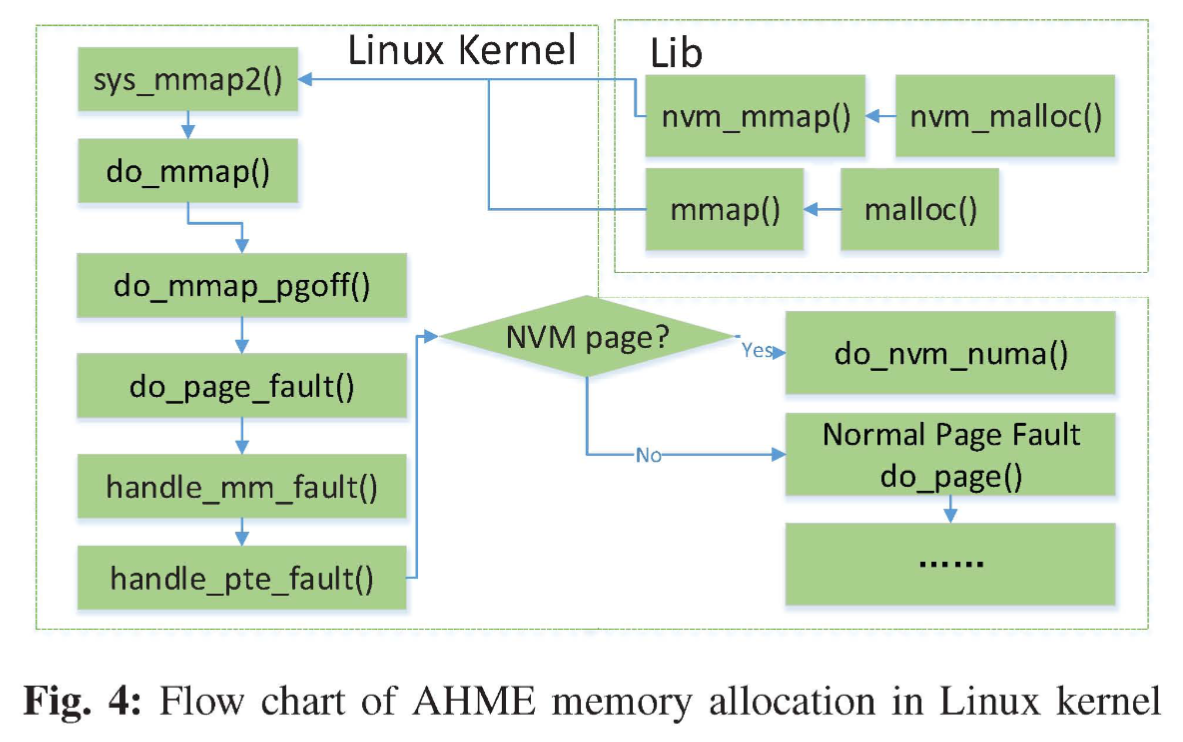
NVM内存分配分支如图4所示。当调用扩展Glibc的nvm_mmap()时,内核调用do_mmap()函数,并在do_mmapygoff()函数申请VMA时在VMA结构上设置NVM_VMA标志。当第一次访问NVM页面时,它会触发页面错误,内核调用handle_mmJault()函数来处理页面错误。如果 NVM_VMA 标志匹配,则调用 do_nvm_numa() 函数来分配物理 NVM 页,该页实际上是远程 NUMA 节点中的 DRAM 页。如果页面错误不是指NVM页面,则内核使用正常的doyage()在本地节点中分配DRAM页面。我们在 Glibc 库中实现了 nvm_malloc 函数,并添加了新的系统调用 nvm_mmap。 nvm_malloc() 调用 nvm_mmap() 将 mmap 参数传递给修改后的 Linux 内核。之后,上述NVM分配由内核执行。
为什么要修改pagefault
V. EVALUATION
总体而言,HME 中的写入延迟仿真误差小于 5%。
VI. RELATED WORK
- Pelley et al. [21] propose offline analysis with PIN to calculate the average number of cache misses referenced by aprogram.
我们使用PIN离线分析来确定(1)缓存页的重用统计,以及(2)缓存页每次锁存的平均访问行数。这些离线统计数据使我们能够在考虑页缓存的影响时,计算Shore-MT中每个页闩锁事件的缓存行访问的平均数量。然后,在每个锁存器中引入一个延迟,该延迟是基于测量的平均漏读数和基于NVRAM技术的每次读取延迟增加的假设。
意思就是先离线分析统计数据,再根据统计数据加延迟 - LEFF [22] supports both NVM emulation and simulation in the same framework. The trace-driven model usually takes much time on profiling and analysis. Instead, HME emulates NVM read/write latency in an online manner.
- Volos et al. [10], [23] achieve NVM write latency emulation by injecting software generated delays. This progress needs programmers to explicitly flush cache lines out of the last level cache.
- PMEP isan in-house NVM emulator, which emulates NVM read latency and bandwidth by using Intel’s special CPU microcode and custom platform firmware
- Lee et al. [24] design FPGA-based hybrid memory prototypes with DRAM and PCM.
- Quartz [15] perhaps is the most similar work to HME. Italso emulates NVM read latencies using adelay injection model on aNUMA-based architecture.First, Quartz does not support write delay emulation while HME provides areasonable approach to NVM write emulation with agood accuracy. Second, Quartz uses the local cores to sample the PMU counters and performs the delay injection
VII. CONCLUSION
我们提出了一种混合内存模拟器,称为 HME。它可以有效地模拟各种 NVM 读/写延迟和商用硬件上的带宽限制,对应用程序性能的影响微乎其微。此外,我们还开发了一个用户友好的API,以方便在我们的模拟器上进行编程。该API是Glibc的扩展,具有与Glibc相当的内存分配性能。实验结果表明,HME中NVM读/写延迟的平均仿真误差低于5%。与最先进的 Quartz 相比,它还显示出更高的仿真精度和更低的应用程序性能开销。
Back: you have read it ! Tags: cxl END
 wechat
wechat alipay
alipay


