
Sidekick: Near Data Processing for Clustering Enhanced by Automatic Memory Disaggregation
START Basic
# Sidekick: Near Data Processing for Clustering Enhanced by Automatic Memory Disaggregation TL;DR:一套基于CXL的NDP聚类算法系统,使用函数调用堆栈区分函数类型,使用遗传算法来决定自动迁移策略 ## INTRODUCTION 面向聚类的NDP 聚类是常见的算法,其需要大内存来进行计算,且CPU会频繁的访问DRAM。CXL可以提供一种拓容方法,然而会增大延迟,且目前带宽弱于DRAMNDP是此类应用的一种有前途的解决方案,我们可以实现一个 NDP 加速器,以卸载内存密集型任务以减少数据通信。同时,主机可以基于一致的设备间内存访问能力来执行其余的计算。
然而,对于聚类算法有两个挑战
- 需要支持多种聚类技术,而不是特定应用优化
- 以自动化方式执行适合 NDP 的任务,不需要手动修改。
在本文中,我们提出了一种支持 NDP 的内存分解系统,称为 Sidekick,它基于 2 型 CXL 设备,并通过系统软件进行增强,该系统软件实现了聚类算法的自动分配技术。 Sidekick在CXL设备上利用轻量级通用处理器来满足各种聚类算法的需求。
Sidekick是第一个基于CXL的全面加速多种聚类算法的系统。
OVERVIEW OF SIDEKICK
系统架构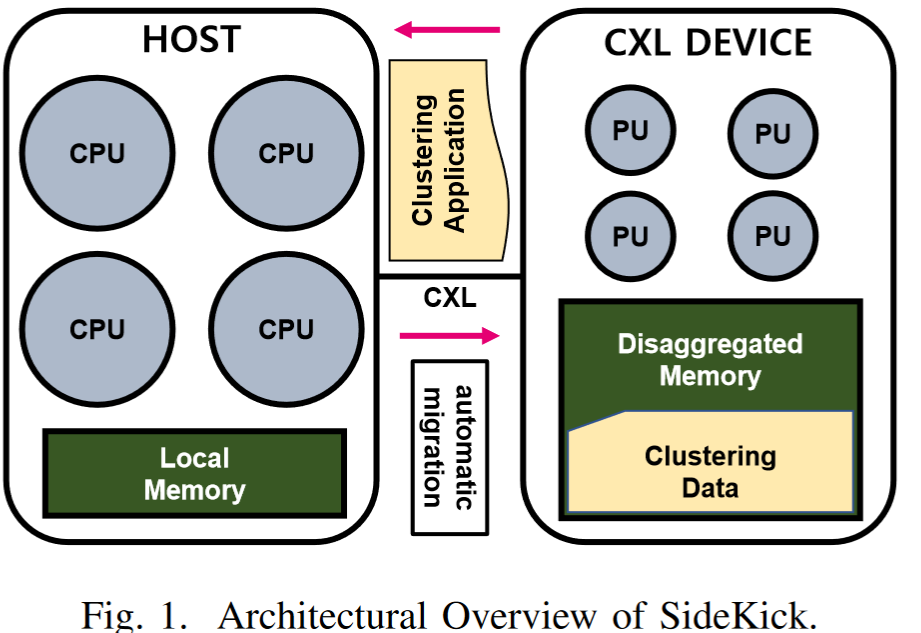
核心软件:自动迁移技术
Sidekick 的核心是自动迁移技术,它识别应在 CXL 设备上执行的函数、线程和内存分配,以获得最佳加速性能。图 2 显示了 Sidekick 如何在没有每种聚类算法的源代码的情况下以系统的方式识别迁移策略。为了成功确定是否迁移程序的一部分,Sidekick 使用中等大小的合成数据集(例如 16 MB)离线表征目标聚类算法。我们将迁移的最小感兴趣区域定义为正常的函数调用,包括线程生成,并收集它们以在后续过程中考虑迁移候选者。 Sidekick 还跟踪内存分配,即 libc 库中典型的 malloc 函数。一旦我们执行聚类算法,我们就会收集实际运行期间可能发生的大部分潜在函数调用和内存分配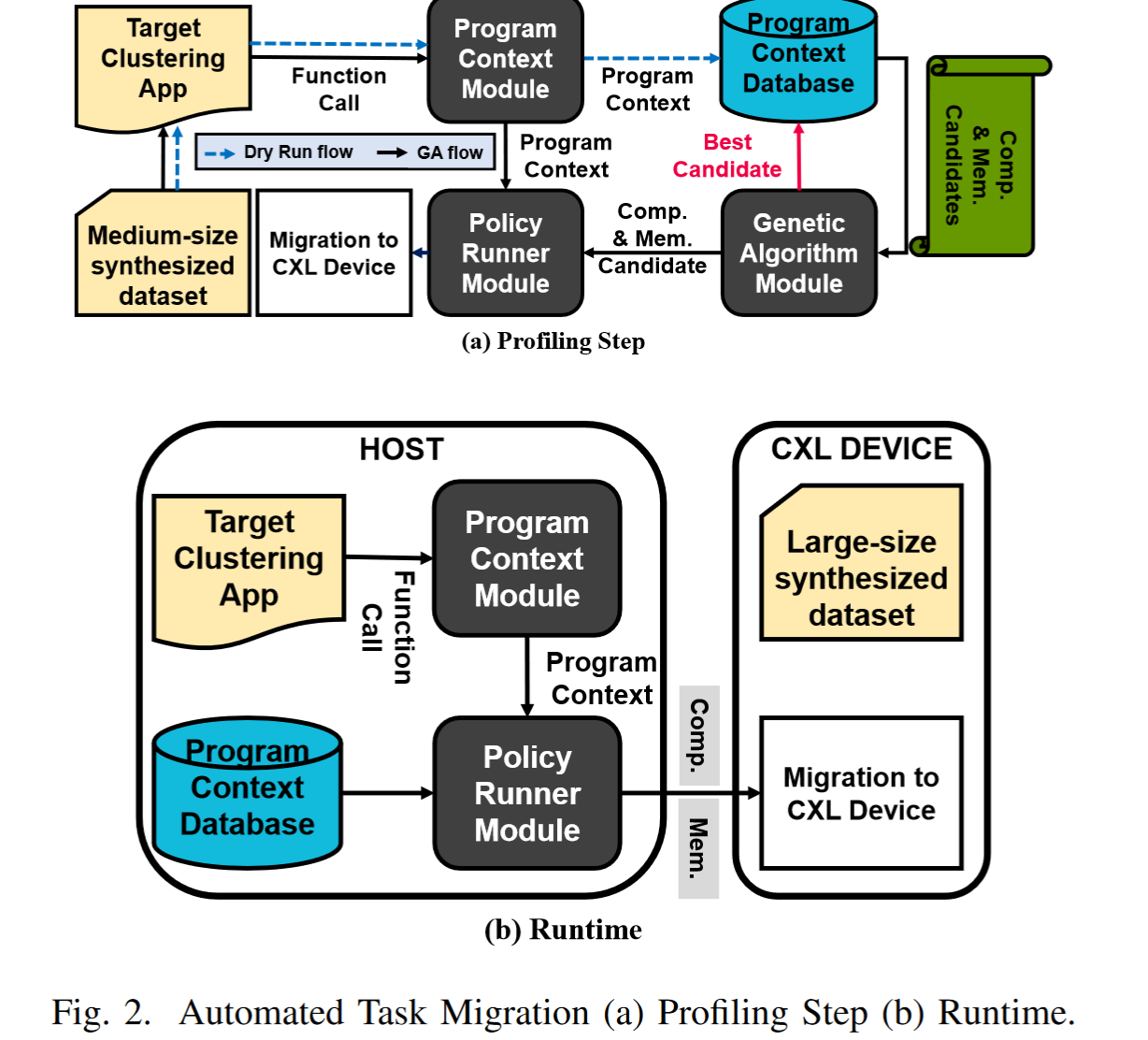
然后我们根据遗传算法(GA)确定最佳迁移程序。
在初始化阶段,Sidekick 随机创建多个候选场景。然后,我们运行每个场景,同时监控系统级指标,例如指令数量、主机和 NDP 中发生的内存访问等。根据系统指标,我们评估每个场景并为下一代制定高级候选方案通过随机填充已执行场景的迁移决策。 GA 算法运行多次迭代,然后我们可以确定最佳场景。在运行时,Sidekick 应用最佳场景来最大限度地发挥基于 CXL 的分解内存系统的优势。
AUTOMATED PROGRAM CONTEXT EXTRACTION
Program Context:which represents a snapshot of the function call chains, is useful for analyzing the internal program behavior
由于函数调用栈包含了从主函数开始的被调用函数的地址,因此我们可以比使用单个调用跟踪更准确地识别程序的上下文信息,即在程序执行过程中为什么使用该函数
如何区分两个相同的函数?根据函数调用堆栈。
例如,到达第一个 calloc() 调用的调用链由多个由其被调用者地址标识的函数调用组成,即 A = ⟨addr0, addr1, · · · , addrn⟩。为了生成唯一标识符号,我们使用生成 32 位值的哈希函数,即 H(A)。另一方面,第二次 calloc() 调用具有不同的结束地址,即 A′ = ⟨addr0, addr1, ··· , addr′ n⟩。因此,我们可以用 H(A) 和 H(A′) 区分两个被调用者,期望具有相同调用堆栈的未来函数调用在计算/内存使用方面表现相似。
首先用模拟数据试运行一次聚类算法,记录大部分的编程上下文,包括线程分配(pthread_create函数)内存分配(malloc、calloc等)
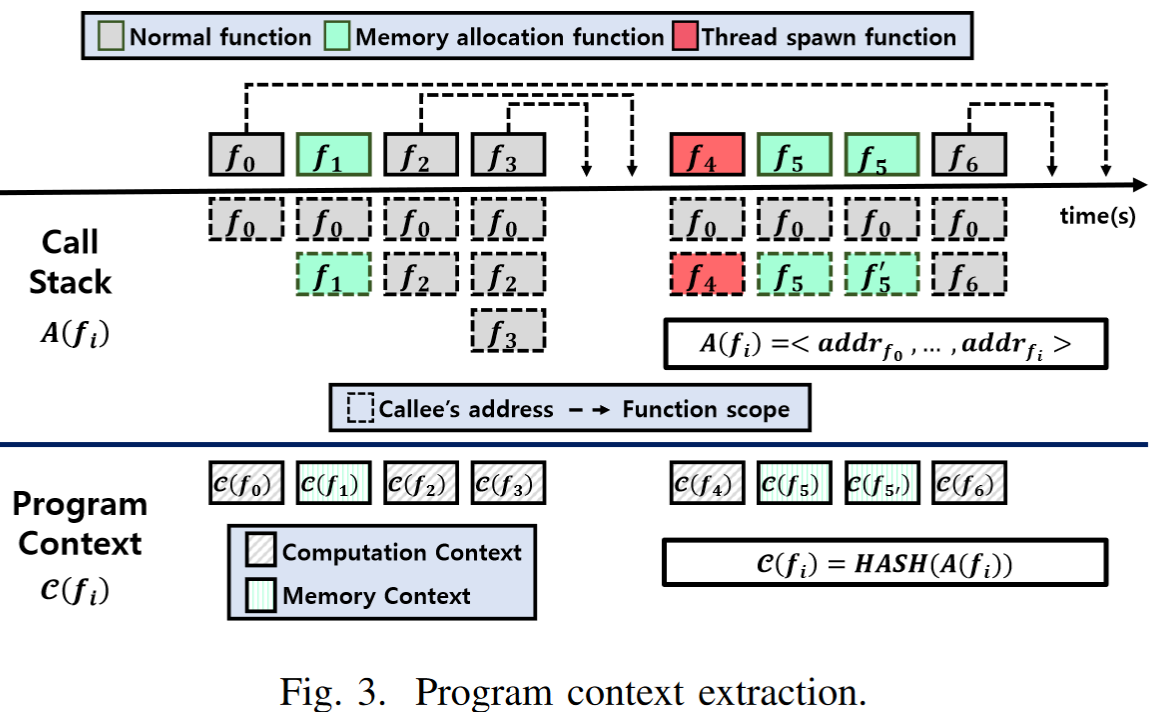
上图描述Sidekick怎么区分计算上下文、内存分配上下文、新建线程上下文。
当普通函数f0执行,其上下文为c(f0),这就是计算上下文。
当内存分配函数f1执行,其调用堆栈为f0 f1,上下文为c(f1),这就是内存分配上下文。
当另外的普通函数f2f3执行,其调用堆栈为f0 f2,f0f2f3(即不包括内存分配上下文),其上下文为c(f2)c(f3)。
当新建一个线程执行f4时,f4的堆栈为f0f4,上下文为c(f4),这就是新建线程上下文。
注意虽然f5被调用了两次,其上下文是不同的,因为返回地址是不同的。
所有的上下文被存储进program context database, in short, PCDB
这套系统的实现非常简单,比如可以用python的分析器和linux的backtrace
MIGRATION POLICY DECISION
使用遗传算法来决定最佳的迁移策略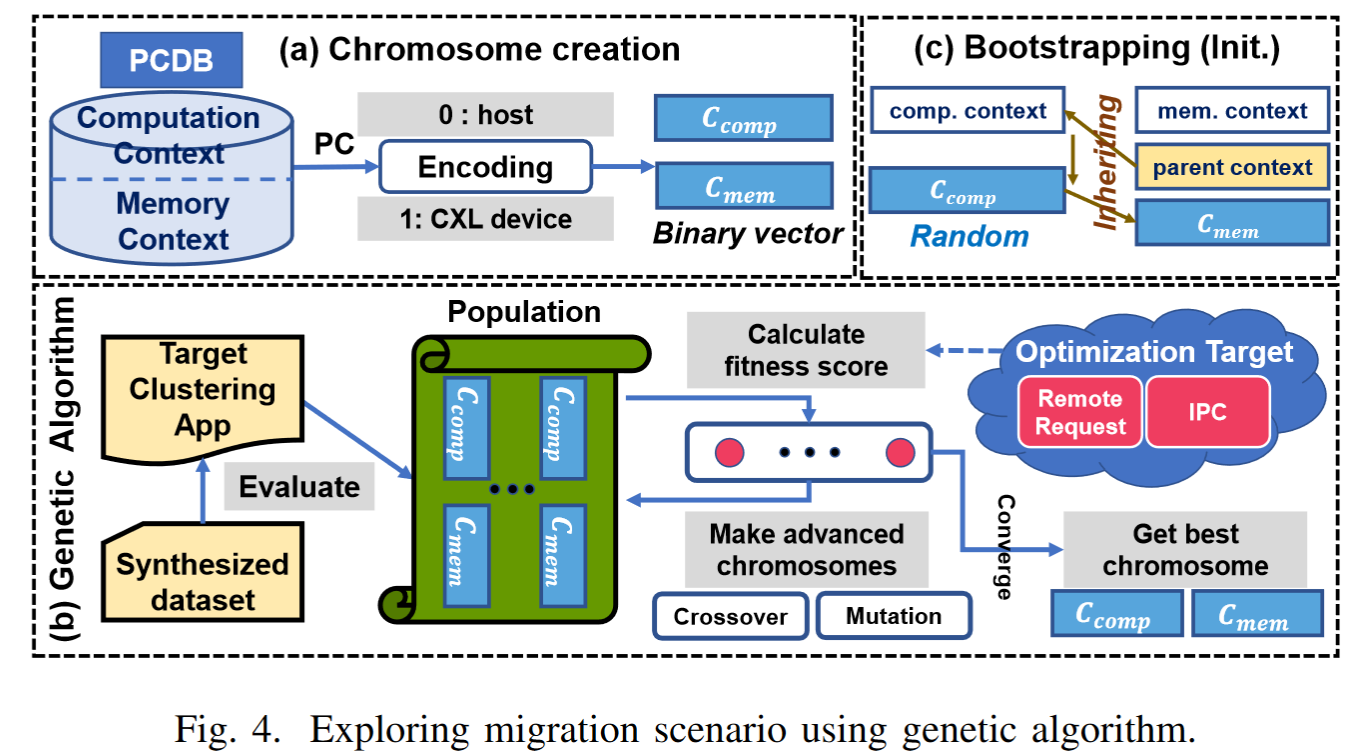
为了以不同的方式考虑 NDP 核心上的计算迁移和 CXL 内存上的内存分配,我们将 PCDB 中的程序上下文分为两组:(i) 从主线程或派生线程启动的函数和 (ii) 函数调用与内存分配。我们使用二进制向量 Ccomp 和 Cmem 对这两个组进行编码,其中向量的每个元素表示它是分配给主机 (0) 还是设备 (1)。遗传算法的初始阶段,Sidekick 创建具有随机性的二进制向量来探索各种迁移场景。全随机分配的一个问题是,由于不同程序上下文的数量导致搜索空间非常大,因此可能需要很长时间或无法收敛才能找到最佳分配场景。
bootstrapping method解决这个问题
如果我们决定迁移 NDP 上的 lloyd iter() 函数调用(称为父程序上下文),我们可以预期在函数上下文中分配的数组也更有可能在 CXL 设备上使用。即使事实并非如此,由于主机系统也可以访问分配的内存层,因此我们可以通过在 GA 的变异过程中给它一个机会更改分配的设备来找到最佳分配。
Sidekick GA 过程的一个关键优点是它允许用户根据所需的优化目标自适应地设置不同的适应度指标。例如,可以使用每周期指令数 (IPC) 或执行时间来获得更好的性能;另一方面,我们可以引导GA减少远程CXL请求的数量,以避免两个系统之间的重负载。在我们的评估中,我们讨论了 Sidekick 如何使用两个不同的优化目标作为代表性示例(第 V-B 节)。为此,我们收集系统级指标,包括周期数、指令数和远程内存访问数,然后计算适应度指标。
使用适应度度量,我们通过遵循一般 GA 规则 [13] 执行交叉和变异来生成下一代染色体。生成和评估过程运行多个时期以找出最佳迁移策略,直到目标指标收敛。请注意,在 GA 迭代期间,由于空运行中看不到的函数调用流程,它可能会找到新的程序上下文。在这种情况下,我们根据具有最相似函数调用堆栈的上下文来卸载相应的计算或内存分配。然后,我们将新看到的上下文添加到 PCDB,将其视为下一次迭代的迁移候选者。
EXPERIMENTAL RESULTS
Intel Xeon Gold 5218 CPU, 两个NUMA,用NUMA模拟CXL,由于 CXL 设备上的通用处理器的计算性能可能会低于服务器级主机处理器,因此我们将模拟 NDP 内核的时钟频率降低了 80%;
为了准确评估,我们的仿真环境使用 OpenMP 执行实际的任务迁移,同时利用内核级模块,以与 [14] (Hme: A lightweight emulator for hybrid memory.)中所示的类似方式为每个内存请求注入内存延迟。性能的话参考directCXL
我们将 Sidekick 与使用分解内存但没有 NDP 核心的系统进行比较。对于评估基准,我们选择了 Scikit-learn 库中最先进实现的九种聚类算法。然后,为了评估 Sidekick 的可扩展性,对于每种算法,我们使用其他三个测试数据集,其样本是根据高斯分布创建的,以形成多个集群。1 我们将它们分为三组:中型、大型和超大,其中平均值内存大小为中型 4 GB、大型 8 GB、超大型 20 GB
当优化目标是IPC时,性能比较
没太看懂后面三个什么意思
请注意,Sidekick 仅使用 16 MB 的相对较小的数据(在图中表示为 GA)通过自动探索过程确定了迁移策略,那其他三个呢?
跟手动定义迁移策略比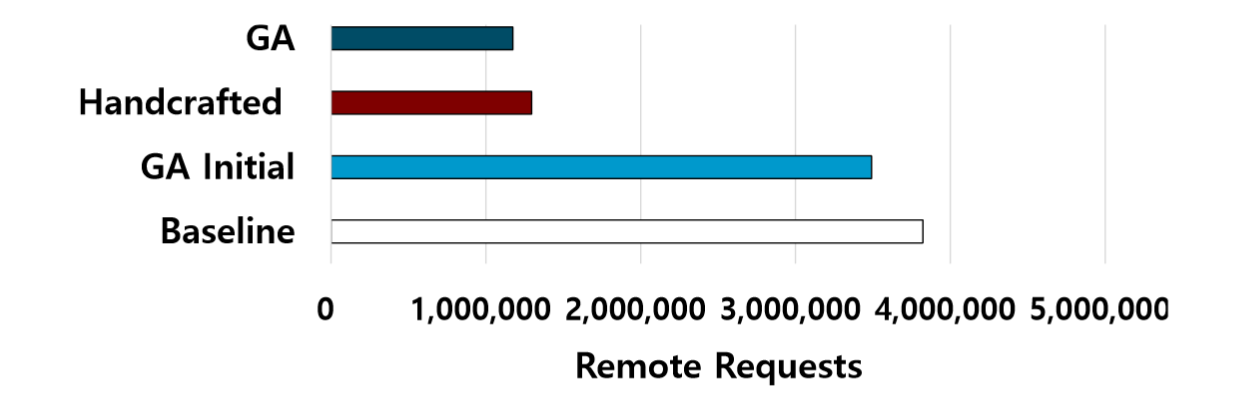
CONCLUSION
提出了一种基于 CXL 的支持 NDP 的内存分解系统Sidekick,我们提出了基于遗传算法(GA)的自动迁移决策来减少远程CXL内存访问
Back: you have read it ! Tags: cxl END
 wechat
wechat alipay
alipay


