
Toward CXL-Native Memory Tiering via Device-Side Profiling
START Basic
# Toward CXL-Native Memory Tiering via Device-Side Profiling TL;DR:将内存访问分析放入CXL控制器中,以实现高精度低开销的内存访问分析,从而实现高效的分层内存管理 ## I. INTRODUCTION 面向CXL的内存分层系统,困难源于内存访问分析方法,现有的分析方法比如PTE-scan [50], hint-fault monitoring [25], and PMU sampling都有固有的缺陷 PTE 扫描和提示错误监控操作页表条目 (PTE) 中的特殊位来实现页面跟踪。PTE 扫描定期清除 PTE 中的访问位,在处理器设置这些位后通过扫描来识别访问的页面 Hint-fault monitoring [25] 也会毒害一些采样的 PTE。对这些页面的以下访问将触发保护错误,并通知操作系统该页面访问。 显然,PTE-scan 在每个 epoch 中每页仅捕获一次访问,导致时间分辨率低且开销高。显然,PTE-scan 在每个 epoch 中每页仅捕获一次访问,导致时间分辨率低且开销高 **更糟糕的是,这两种技术都在 TLB 级别运行,缺乏有关真正的 LLC 未命中的信息。如果一个页面被频繁访问但驻留在缓存中,则将其迁移到快速内存是多余的。** **此外,它们无法区分读取和写入操作,这是基于 NVM 的 CXL 存储器的一个重要方面,该存储器具有不对称的读取和写入带宽** CPU 中的性能监控单元 (PMU)(例如 Intel 的 PEBS 和 AMD 的 IBS)可用于跟踪 LLC 未命中。例如,PEBS 支持以可配置的时间间隔对 LLC 缺失进行采样。它将记录存储在缓冲区中,并在达到容量时触发中断将它们传输到指定的内存空间。虽然 PMU 采样直接跟踪 LLC 缺失,但它始终以较低的采样频率运行以控制开销 [21]、[44],这阻碍了在实际场景中实现最佳热页检测召回 [21]。此外,基于 PMU 的方法是特定于 CPU 供应商的,这限制了它们的通用性提出NeoProf,将其集成进入CXL controler
本文贡献:
- 我们研究了现有内存分层方法的局限性,并证明了在新兴的基于 CXL 的分层内存系统中高效内存访问分析技术的必要性
- 我们提出了一种新颖的 NeoMem 解决方案,它利用内存侧控制器中的专用硬件分析器 NeoProf 来实现高效的内存分析
- 真实平台原型设计。我们基于支持 CXL 的 FPGA 平台和 Linux 内核 v6.3 以及我们的 NeoMem 补丁(第 VI 节)进行了 NeoMem 的真实平台原型设计。
II. BACKGROUND AND MOTIVATION
分层内存管理的关键阶段
- 内存访问分析:系统首先通过特定的内存分析技术收集页面访问统计信息
- 页面划分:将页面划分为冷热页面
- 页面迁移:热页面迁到快速层(promotion),冷页面迁到慢层(demotion)
本文注重内存访问分析阶段
对比现存的系统
- 观察#1:PTE 扫描方法无法在保持较低开销的同时实现高时间和空间分辨率。
- 观察#2:基于 TLB 的内存分析方法可能无法捕获实际的 CXL 内存访问模式。
- 观察#3:PMU 采样方法是特定于 CPU 供应商的,在提高时间分辨率时会带来显着的开销。
III. NEOMEM SOLUTION
设计思想就是将内存分析卸载到CXL内存控制器中
主要功能:(1)检测慢内存中的热页(2)检测运行时状态
- Hot Page Detection.
NeoProf (❶) 驻留在 CXL 内存的设备端控制器中。它监听通过 CXL 通道发送的内存访问请求,对其进行分析并生成页面热度信息以及其他有用的统计信息(❸).
主机CPU控制NeoProf的执行,并通过MMIO(内存映射I/O)接口发送命令(❷)定期读取热度统计数据。在操作系统内核空间中,我们实现了驱动程序(❹)来与 NeoProf 硬件进行交互。由于基于 NeoProf 的热页分析仅需要设备端修改,因此它可以直接兼容任何支持 CXL 的服务器平台。
NeoMem 采用 Linux 内核中完善的 LRU 2Q 机制 [35] 来检测冷页 (❻)。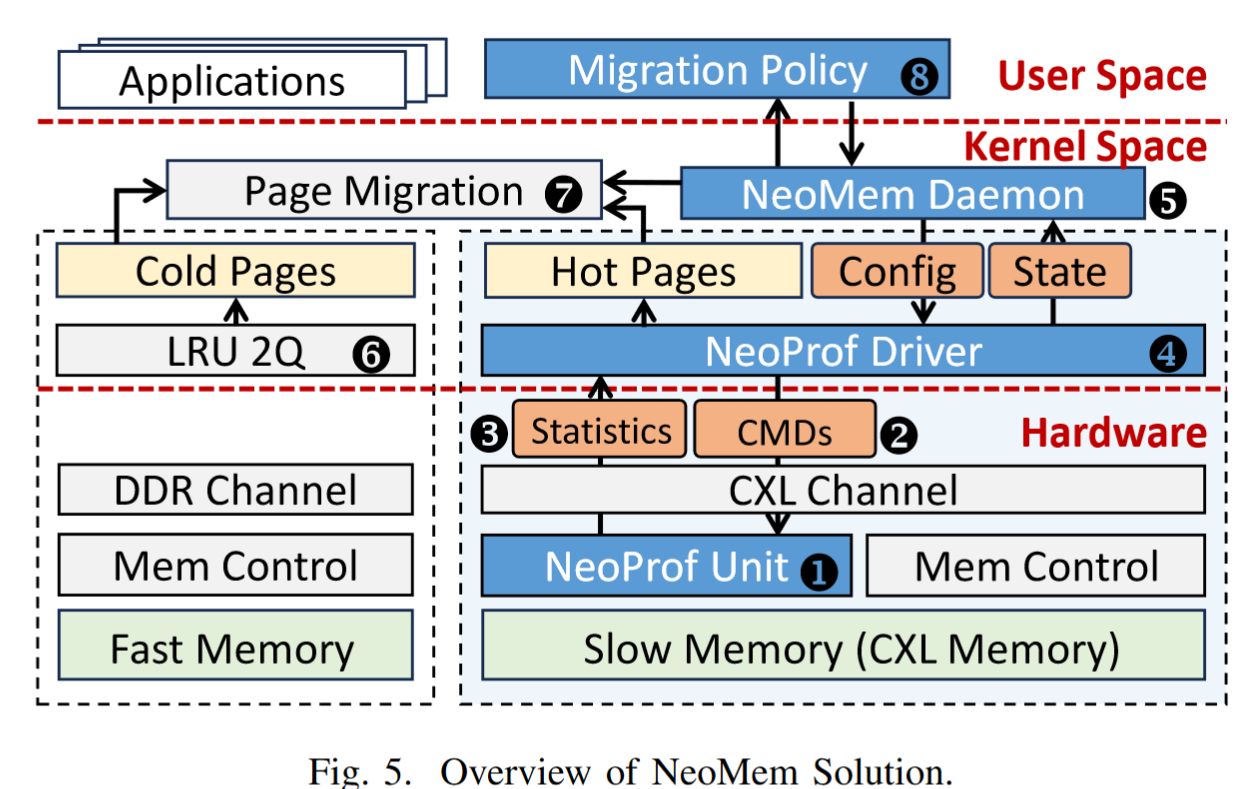
- State Monitoring
在分层内存系统中,监控运行时状态,例如带宽利用率、读/写比率[65]和页面访问频率分布[44],对于有效的内存分层至关重要。
NeoMem Daemon.在 Linux 内核中,我们实现了一个 NeoMem 守护进程 (❺),它与 NeoProf 交互以收集运行时统计信息。该守护进程负责管理热页升级,遵守用户空间 (❽) 中指定的迁移策略。热点页是通过调用内核的页面迁移函数(❼)来迁移的,间隔由migration_interval参数设置。此外,守护进程会定期重置 NeoProf 的状态,具体时间间隔由clear_interval 设置确定。
Migration Policy。基于 NeoProf 提供的丰富信息,NeoMem 的迁移策略为 NeoMem 守护进程制定了协调内存分析和迁移的指南 (❼)。该策略决策是在用户空间中做出的,允许用户进行定制和调整。我们将在第五节介绍 NeoMem 守护进程的实现和迁移策略。
IV. NEOPROF DETAILS
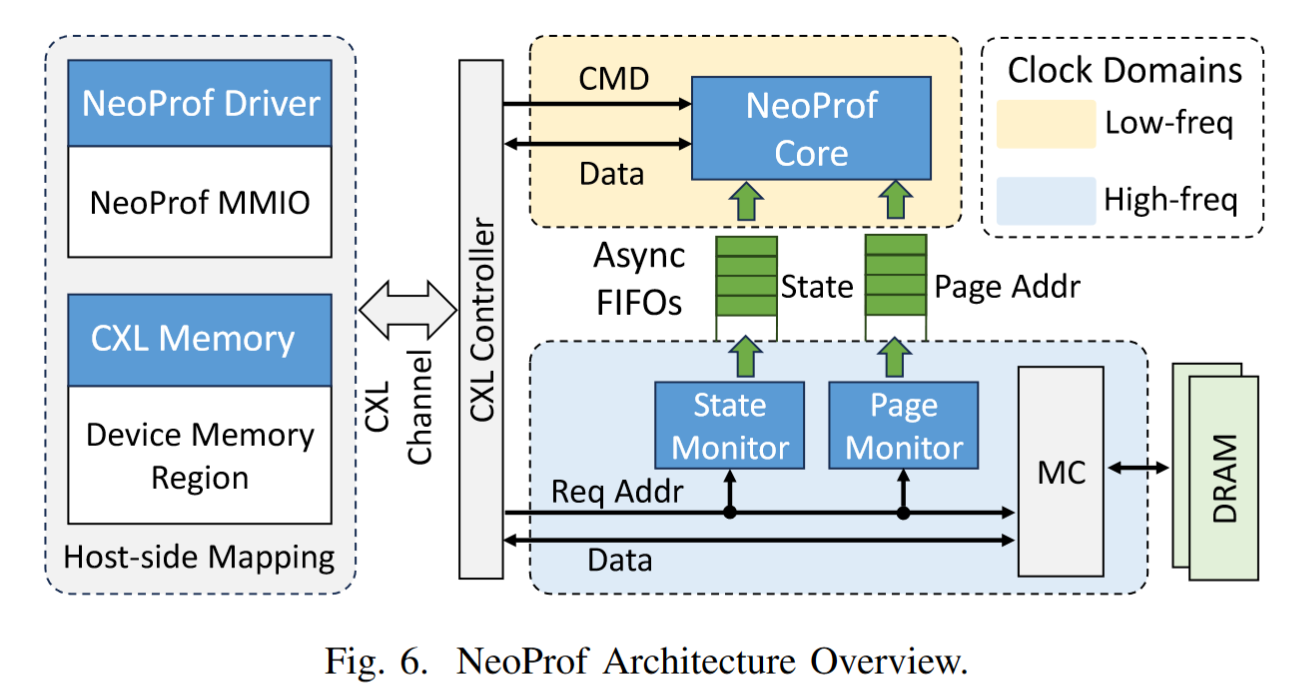
图 6 显示了 NeoProf 硬件的框图,由三个自定义单元组成:状态监视器、页面监视器和 NeoProf 核心。页面监视器监听设备端 CXL 控制器请求,识别物理页面地址,并将它们复制到 NeoProf Core 进行分析。状态监视器跟踪读/写事务,估计带宽利用率和读/写比率,而 NeoProf Core 与两个监视器协作,识别热点页面并响应主机 CPU 控制命令
如左图所示,NeoProf 内核的寄存器被内存映射到预定义的地址空间,使操作系统内核能够通过内存映射 IO (MMIO) 访问它们。主机CPU通过将数据写入具有不同偏移量的特定地址来向NeoProf发送命令。此外,CXL 内存被映射到另一个地址空间,允许操作系统将其作为无 CPU 的 NUMA 节点进行管理
值得注意的是,NeoProf 原型是在 FPGA 平台上实现的。因此,我们将 NeoProf 核心置于低频域,而状态监视器和页面监视器则在高频域运行,以满足内存控制器的要求。我们使用异步 FIFO 将数据从监视器传输到 NeoProf 核心。
热页面检测的挑战:
512G的内存拓展器就有128百万个4K页,如果每个页32位计数器就需要512MB内存,更新这些计数器开销也很大
我们的方法取决于 Count-Min (CM) Sketch 算法 [18],这是一种基于哈希的技术,旨在估计数据流中的项目频率。我们通过两项功能增强了 CMSketch:(1)我们提出了一种有效的热门页面过滤机制来防止重复。 (2)我们在热页检测器中引入了错误绑定控制机制,以保证高检测精度。
具体算法。。。
VI. EVALUATION
性能优于所有现存的方法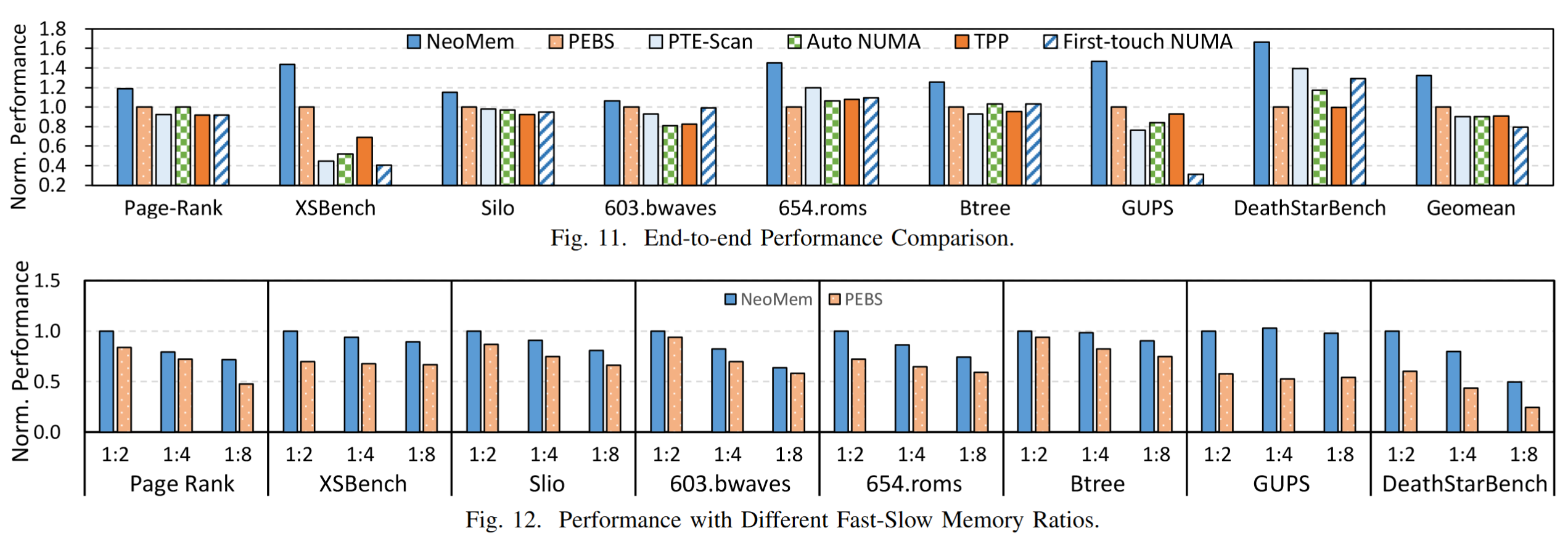
IX. CONCLUSION
在本文中,我们介绍了 NeoMem,这是一种专为基于 CXL 的异构内存系统设计的新型内存分层技术。 NeoMem 体现了硬件-操作系统协同设计理念,将名为 NeoProf 的专用硬件分析器集成到 CXL 内存的控制器中。这使得操作系统能够访问配置文件信息并根据定制的迁移策略执行高效的热页迁移。
Back: you have read it ! Tags: cxl END
 wechat
wechat alipay
alipay


