
OmniCache: Collaborative Caching for Near-storage Accelerators
START Basic
# OmniCache: Collaborative Caching for Near-storage Accelerators TL;利用neardata cache 和主机设备cache的协作来加速IO(文件系统)和数据处理 ## 1 introduction 数据量激增,高性能数据处理需求,传统CPU面临性能和能耗瓶颈,引入近存储数据处理设备,减少数据移动和相关开销。 之前sota的方法:using storage as a raw block device [33], developing near-storage key-value stores [13, 17, 24, 34], and creating near-storage file systems 除此之外还有特定应用的设计。在近存储加速器上利用内存缓冲区对于减轻较高存储延迟和有限带宽的影响至关重要,带宽高,局部性好,但是容量比DRAM小很多。
希望协同利用device和host memory,最大限度地减少存储层和主机层之间的数据移动,从而加速数据处理和常规 I/O 操作(read,write)
对比SOTA:以前的SOTA要么取缺乏any memory caching support,要么无法协作device host memory作为缓存,结果就是缺乏缓存支持或无法利用近存储内存进行 I/O 和数据处理会增加主机和设备之间的存储访问和数据移动。
先前的设计使用简单的指标来减轻数据处理的负担,(例如,计算能力)而不考虑以存储为中心的指标(例如,数据分布、I/O 处理比率、数据移动带宽和排队成本),导致性能不佳
OmniCache:near-storage accelerators, host CPUs, and their memory (DRAM)的结合,加速IO和数据传输
提出了一种新颖的原则”near-cache”,它专注于最大化最近缓存上的数据访问,有效地结合主机(例如更高的内存容量和更多的CPU)和设备(更靠近存储)的优势,同时减轻它们的限制。
horizontal paradigm(横向模式)其中应用程序线程可以同时存储和访问来自主机和设备缓存的数据,从而改善聚合带宽和数据访问延迟。
贡献
- Near-cache I/O:同时利用hostcache 和devicecache,仅将应用程序线程请求的数据大小而不是整个块从存储传输到主机。
- Collaborative Caching for Concurrent I/O:分层缓存方法不同,分层缓存方法中,当缓存(例如 HostCache)已满时,线程必须等待缓存逐出完成,OmniCache 的水平范例允许线程更新其他缓存(例如,DevCache),直到逐出为止完成并减少应用程序停顿。为了定位存储在这些缓存或磁盘上的数据,我们引入了一种可扩展的、主机管理的索引机制,称为 OmniIndex。 OmniIndex 利用配备细粒度范围锁的每文件间隔树,使线程能够同时访问主机和设备缓存以获取非冲突块
- Exploiting CXL.mem Capabilities:除了在基于NVMe的近存储设备上应用Ominicache,也在基于CXL mem的设备上实验
- End-to-end Evaluation:用levelDB、KNN做了测试
在计算机科学和信息技术领域中,”端对端评估”(End-to-End Evaluation)是一种评估系统或服务的方法,它关注整个系统的端到端性能和功能,而不仅仅是其中的部分组件或模块。这种评估方法旨在考虑系统在实际使用环境中的行为和性能,从用户的角度来评估系统的整体表现。
2 Background and Motivation
2.1 Background and Related Work
Hardware Near-storage Processing Trends
Computational Storage Devices (CSD)计算存储设备,通常配有16GB的RAM和 16 核 Cortex 处理器,它们提供预定义的功能和定制选项,以消除主机和设备之间的数据移动,同时提高性能和灵活性。此外,ScaleFlux [35] 和 Newport [15] 等 CSD 无缝集成了处理器、内存和 SSD 控制。这种集成消除了片外通信,并实现了向设备计算单元的快速数据传输,为探索设备资源的利用提供了新的机会
Software Support for Near-storage Acceleration
除了硬件支持,还有软件优化
INSIDER [33] 等设计使用基于块的接口将计算任务卸载到基于 FPGA 的 CSD。键值接口设计,例如 POLARDB [13]、PINK [17] 和 KEVIN [24] 将数据库特定的计算卸载到近存储。此外,NearPM [37]和SmartRec [39]专注于定制的应用程序级优化或系统级保证
与这些系统相比,近存储文件系统设计将文件系统卸载到更靠近存储的位置,同时保持类似 POSIX 的接口。 DevFS [21] 和 CrossFS [31] 等系统采用这种方法,通过卸载元数据结构来提高性能和效率。 FusionFS [9]在这项工作中进行了比较,将文件系统操作与计算步骤结合起来,并结合了设备级任务调度程序以及持久性和可恢复性机制
Data Processing Support
已经探索了各种近存储数据处理系统。 POLARDB [13] 开发了新的应用程序逻辑,通过将数据卸载到基于 FPGA 的键值存储来加速应用程序。 λ-IO [44]利用操作系统文件系统作为统一的IO堆栈来管理主机和设备上的计算和存储资源。它扩展了 eBPF 以在异构硬件上执行功能,并为定制计算逻辑提供额外的编程接口。最后,FusionFS引入了CISCOps抽象,它结合了I/O和数据处理操作,以减少与I/O操作相关的应用程序更改和开销,例如系统调用、数据移动、通信和其他软件开销
In-memory Caching for Storage
在 DRAM 中缓存 I/O 数据对于现代 I/O 堆栈至关重要,传统的缓存是操作系统级别的页缓存,面临用户态到内核态的开销,许多系统探索用户级缓存支持,但是OmniCache是第一个结合主机设备cache的
2.2 Limitations of State-of-the-art Systems
- Failure to Exploit Near-storage Memory for Caching:现有的近存储设计要么忽视设备内存,要么没能协同host和device cache
- 缺乏并发IO和数据处理的支持
- 缺乏动态卸载支持
2.3 Analysis
直接展示性能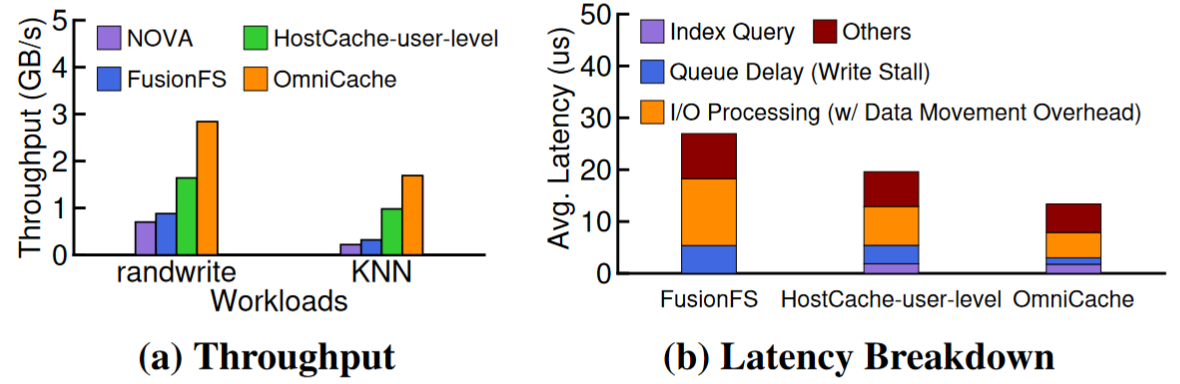
512 GB DC Optane NVM for storage, 64 CPUs, and 32 GB DRAM,20GB的cache
NOVA (a kernel file system) [43], FusionFS (a near-storage file system without caching support),extended hostonly caching design using OmniCache
第一个测试包含两个workload:IO密集的随机写bench,IO+处理密集的KNN
由于系统调用和内核软件开销以及缺乏缓存支持,NOVA 表现出较差的性能。由于缺乏缓存,FusionFS 的性能也很差。
HostCache-用户级在缓存驱逐期间遭受数据移动和频繁的写入停顿。然而,OmniCache 通过利用协作主机和设备缓存使用显着提高了性能
第二,为了强调利用近存储 RAM 来优化未对齐 I/O 请求的必要性,表 2 显示了流行的实际应用程序中大量未对齐的 I/O 请求比率,包括 RocksDB、MySQL 和 DiskANN[18]。这激发了 OmniCache 的协作 I/O 缓存,旨在最大限度地减少与未对齐 I/O 请求相关的数据移动开销
第二个测试针对随机写入工作负载的平均延迟细分,首先OmniIndex的开销很低,其次可以看到OmniCache减少了write stalls,最后由于其高效的近缓存 I/O 原理,I/O 中的数据移动开销以及未对齐 I/O 请求的数据处理减少了
3 Goals and Overview
Omnicache包含三部分
(1) a userlevel library (OmniLib), (2) a user-level cache indexing structure (OmniIndex), and (3) a device manager (OmniDev).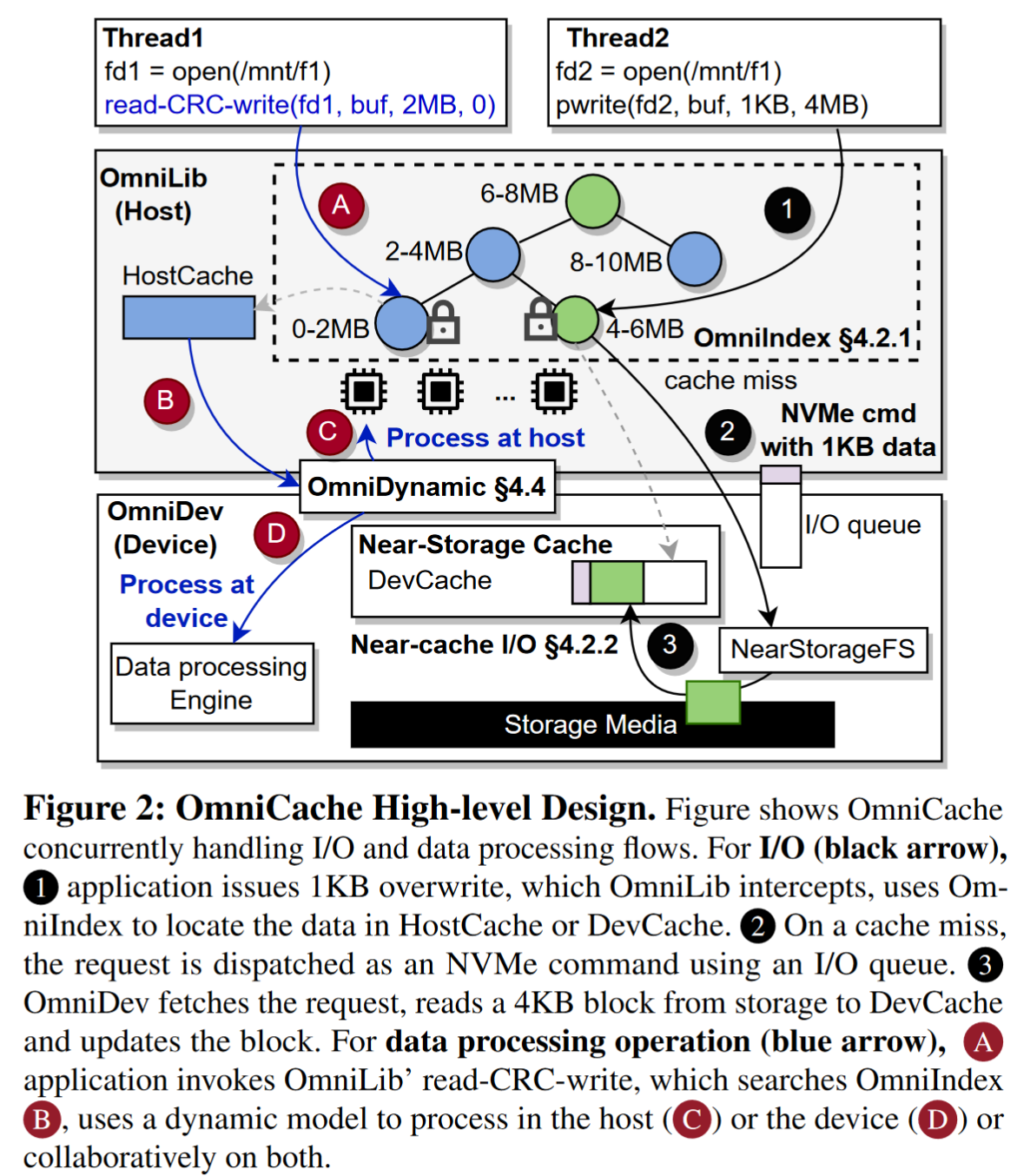
OmniLib:用户级组件利用主机级多核 CPU,启用协作缓存并执行数据处理。 OmniLib 执行各种任务,例如调度 I/O 请求、管理缓存资源、促进并发 I/O 和数据处理操作以及处理数据逐出。
OmniLib 拦截系统调用并创建每个文件的 I/O 队列,将所有 POSIX I/O 调用转换为类似 NVMe 的命令并将它们添加到 I/O 队列中以供设备 (OmniDev) 处理(如 1 到 3 所示)
OmniLib 还处理数据处理操作并提供预定义的应用程序接口,这些操作被转换为 NVMe 命令向量并添加到 I/O 队列中,以便卸载到设备或在主机上进行处理。
For caching:OmniCache 将职责划分到主机层和设备层。 OmniLib 为 HostCache 和 DevCache 提供索引,使用索引检查数据是否存在,并管理 HostCache。 OmniLib 还通过实施两步 LRU 驱逐来决定何时从 HostCache 和 DevCache 中驱逐
For data processing:OmniLib 实现了模型驱动的卸载引擎,以动态 (B) 决定是否将处理(例如,读取-CRC-写入)卸载到主机 (C) 或设备 (D)。最后,OmniLib 还通过直接将数据和命令复制到 DevCache 并避免排队延迟和数据复制来提供使用 CXL.mem 的可扩展性。
**Fine-grained Indexing (OmniIndex)**:OmniLib的一部分,实现高效的数据检索,能够定位到数据在hostcache、devcache还是storage。
除此之外还执行文件中块范围的所有权管理和数据驱逐,OmniIndex 是一个每文件的范围树索引结构,每个节点对应于文件的特定范围/段,并具有指向 HostCache 或 DevCache 中内存缓冲区的指针,图中蓝色和绿色节点分别表示数据驻留在HostCache和DevCache中,OmniIndex 的细粒度范围锁可跨线程处理并发 I/O 和处理请求,确保跨主机和设备的无冲突访问。 OmniIndex 还跟踪脏数据以进行缓存驱逐
OmniDev:近存储组件由文件系统、数据处理引擎和近存储缓存支持组成。OmniDev 的文件系统类似于之前的近存储文件系统,包括内存中和磁盘上的元数据结构以及用于崩溃一致性的日志记录[9]。数据处理引擎处理处理请求,从 I/O 队列检索它们,使用处理后的输出更新 NVMe 命令,并设置完成标志。
cache功能:一旦cache miss,OmniDev就使用内部的内存分配器分配空间,处理请求,返回cache的内存地址来更新OmniIndex
4 Design
4.1 Cache Architecture
我们讨论分布式缓存管理的布局、管理和挑战的基本原理。
DevCache 的两个重要设计考虑因素是:(1) 在主机和设备缓存中独占或包含地维护数据,而不增加数据移动和通信开销; (2) 确保只有具有正确权限的应用程序才能访问缓存块,尽管直接 I/O 绕过操作系统。
关于(1),我们采用独占缓存方法,其中数据块要么存储在HostCache中,要么存储在DevCache中,或者存储在存储中(这会导致缓存未命中)。原因如下
- 首先,与包含式缓存不同,独占式缓存避免了跨缓存的重复块,从而增加了缓存覆盖率。
- 其次,用于保持一致性的包容性缓存可能会导致主机和设备之间的通信成本较高。
- 最后,由于 HostCache(较大)和 DevCache(较小)容量显着不同,独占缓存提供了改变逐出频率的灵活性。
关于 (2),操作系统和 OmniDev 管理权限检查和访问控制,这是我们从先前系统继承的 [9,31,33]。简而言之,对于访问文件的进程,只有当进程具有文件的访问权限并且队列也由操作系统标记有凭据时,操作系统才会创建每个文件的 I/O 队列。
4.2 Collaborative Caching for I/O
4.2.1 Scalable OmniIndex
基于范围树的可扩展且高度并发的缓存索引机制。
并发无冲突访问:OmniIndex 中的每个节点范围都配备了读写锁。线程在从缓存访问相应数据、执行 I/O 或处理之前获取按范围锁。当数据不在主机和设备缓存中时,在发出 I/O 命令之前会获取范围锁。
Avoiding Conflicts:防止主机和设备的冲突:将范围的所有权分配给主机和设备,确保只有一个实体(host or device)可以修改节点范围内的数据并保持数据完整性
Memory Overheads of OmniIndex:很小,1TB数据只需要128MB(<0.001%)每个node156字节
4.2.2 I/O Operations with OmniCache
写:OmniCache 采用近缓存 I/O 原理。首先,数据被写入OmniIndex节点的HostCache,然后更新节点的信息,包括更新OmniIndex节点的脏位信息。此外,为了减少 OmniIndex 的深度并启用批量驱逐,写入操作将合并到单个节点中,其最大范围为预配置大小(默认为 2 MB)。然而,缓存页是以块大小的粒度分配的。我们将很快讨论更新 HostCache 和 DevCache 的并发和协作方法。
(写回策略,不直接写到storage,而是先写到缓存,提交时才写到存储里)
覆写:如何要覆写的块在缓存里,就更新缓存标记为脏,如果cache miss与现有设计不同,OmniCache 避免将整个范围的块从存储器获取到主机。相反,它仅将相关块读取到 DevCache,以减少设备和主机之间的写入放大,将更改直接应用于 DevCache 中的块并更新 OmniIndex。(覆写的话就有可能不在cache,要读到cache,不过怎么做到细粒度读的?)
读:先读omniindex看数据在哪,如果cache miss就类似覆写,对于多个OmniIndex节点或存储中的块,使用带有细粒度锁的OmniIndex来并发读取块,从而实现更低的延迟和更高的吞吐量。
**File Commit (fsync)**:OmniCache 使用 OmniIndex 的范围和每块脏位将一个或多个块提交到存储。对于 DevCache 中的块,OmniCache 创建并发出 I/O 命令,OmniDev 处理文件提交。 fsync 被视为文件上的屏障操作
文件共享:在共享内存分配器的支持下在共享内存区域内分配缓存页。对共享缓存和 OmniIndex 的访问仅限于具有必要文件权限的进程。受信任的第三方服务器使用基于租约的锁来调解对共享 OmniIndex 的访问。
4.2.3 Concurrent Caching and Reducing Eviction Stalls
同时使用 HostCache 和 DevCache 以及低开销缓存驱逐对于最大限度地减少应用程序停顿和优化性能至关重要。
为解决挑战,提出collaborative caching and concurrent eviction;在协作缓存中,应用程序线程同时使用 HostCache 和 DevCache,当一个缓存已满时在它们之间进行切换。这减少了计算停顿并提高了性能。
Two-step LRU Eviction:
当有新的数据更新时,首先将其写入HostCache。当HostCache达到容量上限(没有可用空间)时,OmniLib将写操作转到DevCache,并同时开始在HostCache中进行并发的缓存淘汰操作
为了管理两个级别的LRU信息,系统使用了一个后台淘汰线程。这个线程维护了两个LRU列表:文件级LRU和每个文件的OmniIndex LRU。文件级LRU列表包含了所有已关闭或非活动文件的信息。OmniIndex LRU列表用于跟踪最近未被访问的文件范围。如果一个文件或一个范围在可配置的30秒时间段内没有被访问,它就会成为LRU。
驱逐缓存的第一步:逐出LRU的文件,如果此时缓存占用空间下降到阈值以下,比如10%,应用程序就继续插入缓存,否则进行第二步。第二步进行文件内范围LRU驱逐,从设备和主机缓存中删除文件的LRU的范围块。
协作缓存和两步驱逐确保 HostCache 和 DevCache 之间的无缝过渡、不同缓存的并发利用、减少计算停顿并提高性能。
4.3 Collaborative Processing with Caching
近存储处理的卸载操作的有效性取决于 I/O 操作的频率以及使用功能较弱的设备上计算和较小的内存资源的影响等因素。
Application Interface for Processing:Omnicache需要应用使用Omnilib预定义的处理函数,提供了丰富的op,比如checksum or compression.
I/O和数据处理操作被转换和堆叠为NVMe命令向量,并作为批处理操作卸载(称为CISC操作[9]
Challenges:协作数据处理需要并行的主机设备处理、跨缓存的动态数据迁移以及基于硬件和软件成本(例如,数据移动开销、数据处理时间、队列延迟)的智能卸载决策。
Key Ideas:首先,继承了cache的协作,我们使用 OmniIndex 在主机和设备上进行并发范围级数据处理,并具有细粒度的范围并发性。其次,我们引入了一个考虑硬件和软件指标(例如存储、内存、计算时间、排队延迟)的动态模型。
4.3.1 Extending OmniIndex for Compute Cache:
我们通过添加处理缓冲区processing buffer(与高速缓存缓冲区分开的中间计算缓冲区)来改进 OmniIndex。处理缓冲区链接到每个树节点,并且可以存储在主机或设备内存中。通过每个区间树节点中的地址引用来访问处理缓冲区。这有助于 OmniCache 快速查找处理状态,在主机和设备上拆分和合并处理。
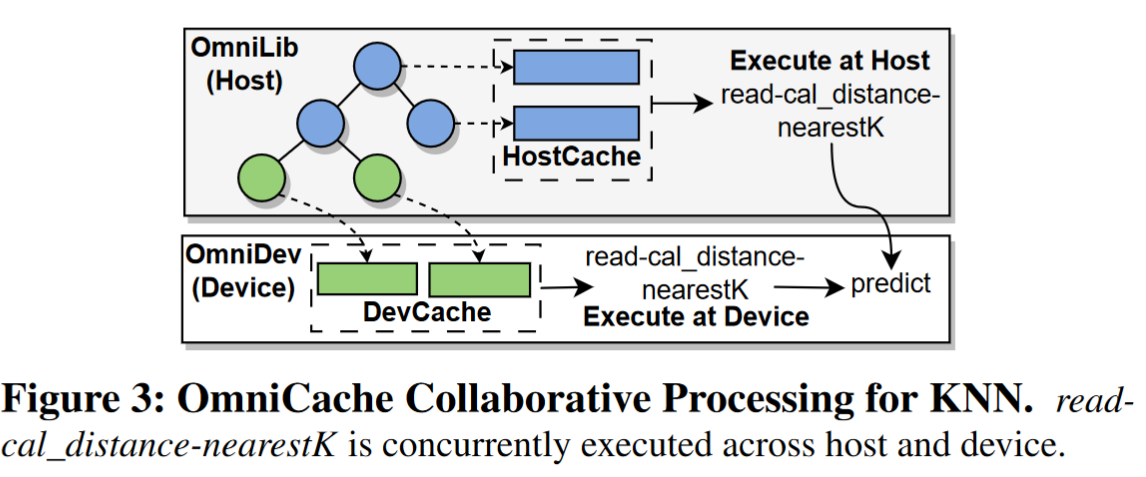
借用一个例子来看processing buffer的作用
引入read-cal_distance-nearestK操作,这个操作计算距离、选择最近的K个点,中间结果比如说计算得到的距离将会被存储在processing buffer中。
这个操作可以并发在host和device中执行,协作处理。
之后,OmniCache会合并K个最近点并进行最终分类预测,这里会涉及到数据传输,
预测操作具体在host还是在device上执行由动态任务卸载策略决定。
4.4 Resource-driven Dynamic Offloading
目的:增加主机和设备上的近缓存和近数据处理,同时最大限度地减少数据移动
困难:存储、HostCache 和 DevCache 之间不同的计算能力、缓存容量和数据传输时间需要动态方法来达到最佳处理位置,有三重挑战:
首先,数据分布在主机和设备缓存之间的处理操作可能会导致数据移动。其次,决定卸载位置的硬件和软件指标(例如计算成本、内存要求和 I/O 频率)可能会根据处理复杂性而发生显着变化。第三,在不干扰数据平面操作的情况下监控主机和设备硬件和软件指标至关重要。
Model-driven Approach:
模型驱动的策列基于以下公式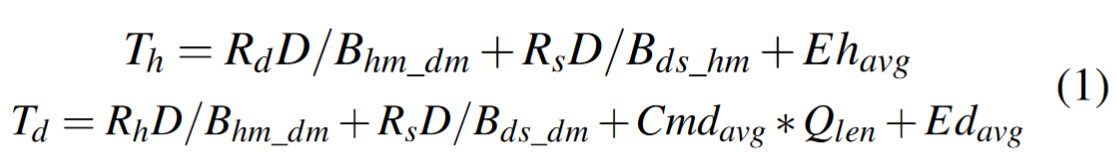 Th 和 Td 通过考虑各种因素分别计算主机和设备上请求的处理时间: 数据比率 (R) 表示与分布在 HostCache、DevCache 和存储上的请求关联的数据。比率 Rhm、Rdm 和 Rs 表示每个请求的主机内存 (hm)、设备内存 (dm) 和存储 (s) 中的数据部分。执行时间 (E) 仅捕获处理成本,Ehavg 表示在主机上执行请求的平均时间,而 Edavg 表示在设备上的平均时间。数据传输成本 (B) 捕获 HostCache、DevCache 和存储之间的数据移动。 Bhm_dm表示HostCache和DevCache之间的数据传输带宽,Bds_hm表示存储和HostCache之间的带宽,Bds_dm表示存储和DevCache之间的带宽。最后,Queue Latency 表示请求的完成时间,这取决于排队延迟。这取决于每个文件 I/O 队列中的 I/O 和数据处理请求的数量以及处理请求所需的平均时间 (Cmdavg * Qlen)。缓存驱逐期间队列延迟会增加。
Th 和 Td 通过考虑各种因素分别计算主机和设备上请求的处理时间: 数据比率 (R) 表示与分布在 HostCache、DevCache 和存储上的请求关联的数据。比率 Rhm、Rdm 和 Rs 表示每个请求的主机内存 (hm)、设备内存 (dm) 和存储 (s) 中的数据部分。执行时间 (E) 仅捕获处理成本,Ehavg 表示在主机上执行请求的平均时间,而 Edavg 表示在设备上的平均时间。数据传输成本 (B) 捕获 HostCache、DevCache 和存储之间的数据移动。 Bhm_dm表示HostCache和DevCache之间的数据传输带宽,Bds_hm表示存储和HostCache之间的带宽,Bds_dm表示存储和DevCache之间的带宽。最后,Queue Latency 表示请求的完成时间,这取决于排队延迟。这取决于每个文件 I/O 队列中的 I/O 和数据处理请求的数量以及处理请求所需的平均时间 (Cmdavg * Qlen)。缓存驱逐期间队列延迟会增加。
Continuous and Low-interference Monitoring
为了实现动态卸载模型,OmniCache 使用 OmniDynamic 组件持续监控主机和设备层的硬件和软件参数。该组件在 OmniLib 和 OmniDev 的交叉点上运行,收集缓存数据比率、数据移动带宽、处理成本和队列等待时间开销等指标。
对于设备上的指标收集,我们使用附加计数器扩展了用于数据处理的每个 NVMe 命令,包括设备上处理时间 (Ed)、DevCache 和 HostCache 之间 (Bhm_dm) 以及存储和 DevCache 之间 (Bds_dm) 之间的数据移动带宽。
使用上面的算法进行决策,最后还会更新平均执行时间、处理请求所需的平均时间
4.5 Exploring CXL Extensibility with OmniCXL
我们研究了 OmniCache 如何利用 CXL.mem 减少数据复制和排队瓶颈,同时确保在没有硬件级缓存一致性支持的情况下安全运行。
在 OmniCache 基于队列的设计中,所有请求都会产生开销,例如将数据和 NVMe 命令从应用程序(或设备)缓冲区打包和复制到启用 DMA 的 I/O 队列、排队延迟以及主机 CPU 开销(例如轮询请求完成)。
如何利用CXL.mem来减少这部分开销
对于 write() 等 I/O 操作,由于空间限制,无法缓存在 HostCache 中,OmniLib 直接将数据写入devcache并进行flush。
避免 (1) 在应用程序和设备队列之间复制数据,(2) 打包(在主机上)和解包(在设备上)NVMe 命令,(3) 减少排队延迟,以及 (4) 连续轮询请求完成,从而最大限度地减少 CPU 开销。
(传统的写要先写道host memory,然后执行memcpy到device,这就会带来上述的开销,引入cxl后可以直接写到device memory)
5 Implementation Details
首先,由于缺乏对可编程存储硬件的访问,我们将模拟 OmniDev 实现为设备驱动程序 (8K LOC),这与之前的工作类似 [9, 31]。为了了解 OmniCache 对更快和更慢存储的影响,我们实现了两个不同的近存储后端:一个通过扩展 PM 文件系统在 Intel Optane 持久内存 (PM) 上,另一个在基于 NVMe 的 SSD 上使用块级 ext4 和 I/ O 绕过操作系统缓存的操作。我们还向 OmniDev 添加了一个存储处理引擎。
其次,为了管理 DevCache,在 OmniDev 中,我们实现了一个轻量级且高效的内存分配器,它使用位图数组来跟踪缓存块的可用性。分配器将块 ID 返回给主机级,而不是将设备的内存地址暴露给主机。
第三,OmniLib(在第 3.2 节中讨论)使用 shim 库来拦截 POSIX I/O 操作并将其转换为符合 OmniDev 的 NVMe 命令。对于 HostCache 管理,我们扩展了可扩展的 jemalloc[4] 分配器来进行缓存块分配和释放。使用非 CXL 近存储设备时,NVMe 命令将复制到每个文件的 NVMe 队列,稍后由 OmniDev 出队并分派。相反,对于 CXL.mem,OmniLib 直接访问设备内存。我们为 OmniLib 实现了 CXL 内存分配语义,以注册和分配在 OmniLib 和 OmniDev 之间共享的 CXL 命名空间。
最后,为了模拟设备内存和计算速度以及 CXL.mem 延迟和带宽,我们采用了两步模拟。首先,为了模拟从主机 CPU 访问较慢的设备内存,我们将设备内存映射到主机 CPU 远程但位于设备 CPU 本地的 NUMA 套接字(节点)上。准确地说,在具有两个套接字的系统中,我们在 NUMA Node0 上分配主机内存,该内存对于主机 CPU 来说是本地的,对于设备 CPU 来说是远程的。相反,我们在 NUMA 节点 1 上分配设备内存,该节点对于设备 CPU 来说是本地的,但对于主机 CPU 来说是远程的。接下来,为了模拟设备内存带宽,我们使用热调节 [6] 来限制设备内存的带宽,使用频率缩放来降低设备 CPU 速度,并添加软件延迟来改变 PCIe 延迟。在第 6.4 节中,我们研究了 OmniCache 对这些硬件参数的敏感性
6 Evaluation
6.1 Experimental Setup
dual-socket, 64-core, 2.7GHz Intel(R) Xeon(R) Gold platform with 32GB memory
512GB (4x128GB) Optane DC persistent memory with App-Direct (persistent) mode to represent the upcoming fast storage as well as 512GB NVMe SSD to study the benefit of OmniCache on slower storage.
DevCache with 4GB of DRAM for caching and for OmniDev, we reserve 4 CPUs.
对比对象:
- SOTA PM file system NOVA
- near-storage file system FusionFS(这俩都没cache)
- HostCache-user-level:只用hostcahe
- lambda-IO-emulate:引入λIO,使用hostcache(可以将操作卸载到device)
- OmniCache:同时用host device cache,但是没有模型驱动的任务卸载,卸载仅由数据比率决定
- OmniCache-dynamic:有动态卸载
- OmniCXL:结合CXL
6.2 I/O Performance

读写私有文件,1KB IO共64GB,总cache20GB
研究IO size的影响
对于跨各种工作负载的非块对齐请求,OmniCache 始终优于其他方法,从而获得了近缓存 I/O 的优势。对于块对齐 (4KB) 随机写入,OmniCache 提供了性能提升,这要归功于其并发 I/O 和协作缓存,可减少写入停顿。对于块对齐的随机读取(例如 4KB),OmniCache 的性能与 HostCache 用户级类似,因为它将整个块移动到主机。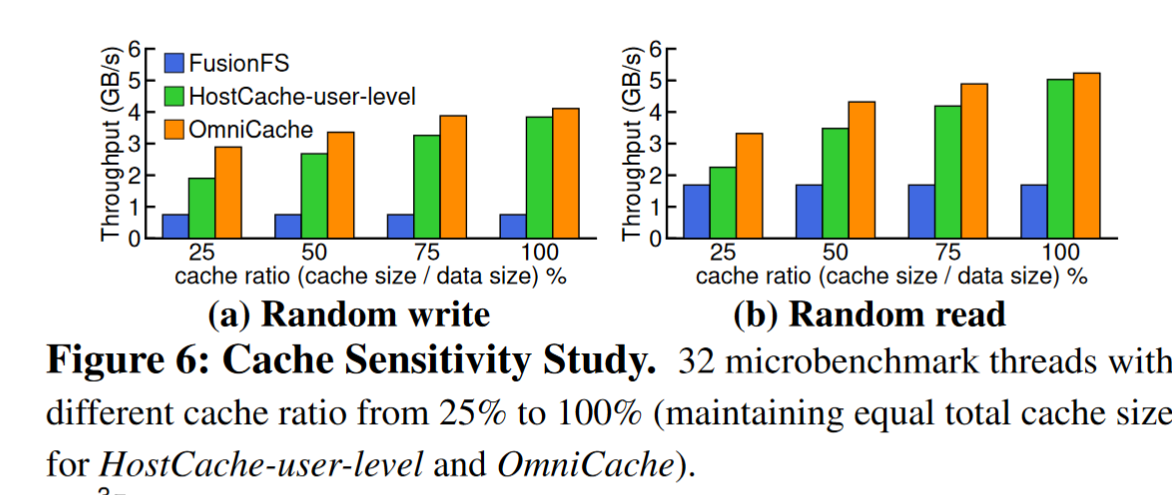
cache数据比率的影响
较低比率下只用hostcache会经历频繁的驱逐和线程停顿,OmniCache 会平滑地将应用程序线程转换为利用 DevCache,所以性能好些,即使在 100% 缓存比率下,OmniCache 通过使用近缓存 I/O 原则最大限度地减少数据移动,也优于其他缓存。
6.3 Data Processing with OmniCache

IO+数据处理负载(read-CRC-write)
吞吐量分析:
FusionFS 遇到 NVMe 命令通信和数据复制开销。它需要将每个请求卸载到设备,在设备上执行计算,然后将数据写回设备存储。而HostCache可以直接在主机上进行操作,所以效率更高。
但是在缓存未命中的情况下,HostCache 用户级会产生存储和主机内存之间的数据移动开销,从而阻碍计算。
OmniCache-dynamic 显着提高了性能,尤其是在繁重的工作负载场景下。这种性能的提高得益于其模型驱动方法,该方法持续监控执行时间、队列延迟和其他因素,以动态确定最佳卸载位置
延迟分析:
HostCache 最初可以很好地处理写入请求,但由于 epoch 1000 之后的驱逐而出现波动和延迟,从而导致更长的队列延迟。OmniCachedynamic 的模型驱动方法考虑了数据分布率、队列长度和执行成本等因素,保持了较低且稳定的延迟,性能比 HostCache 用户级高出 1.42 倍。
6.4 OmniDynamic Model Effectiveness
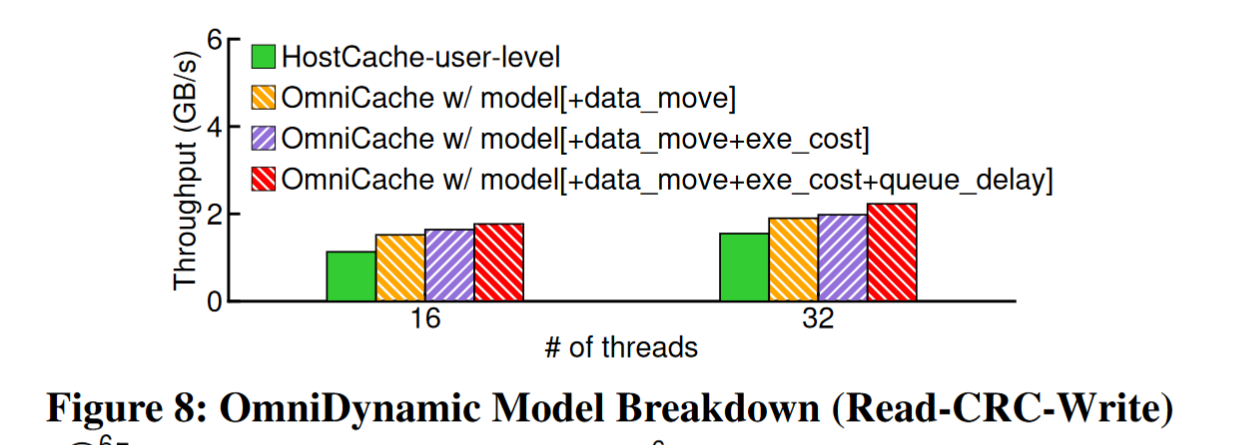
拆分公式验证每个参数都是有用的
验证硬件参数的敏感性,即使是低频率的内存也有很好的性能
6.5 CXL.mem enabled OmniCache

性能提升
6.6 Real-World Applications
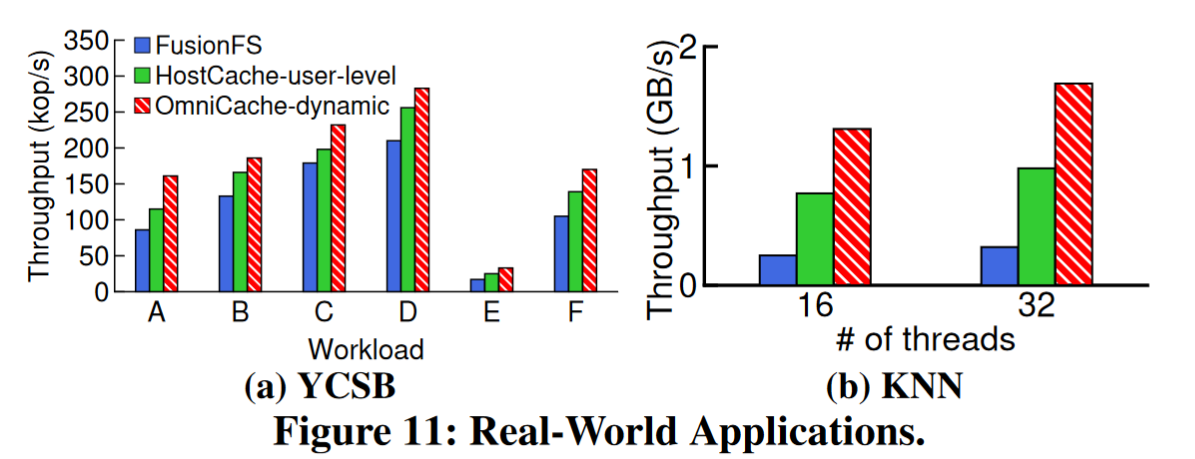
7 Conclusion
我们开发了 OmniCache,这是一种协作式缓存设计,利用主机和设备内存作为缓存来加速 I/O 和数据处理。 OmniCache 通过可扩展索引、并发缓存和处理支持以及以模型为中心的动态卸载技术来实现这一目标,从而显着提高微基准测试和应用程序的性能
Back: you have read it ! Tags: cxl END
 wechat
wechat alipay
alipay


