
Partial Failure Resilient Memory Management System for (CXL-based) Distributed Shared Memory
START Basic
# Partial Failure Resilient Memory Management System for (CXL-based) Distributed Shared Memory TL;DR:基于CXL的共享内存部分容错设计 > 我对疑问是,这篇文章是否描述了共享内存多进程之间如何对同一块物理内存建立映射 > > 答案:在使用前先mmap共享内存到自己的虚拟地址上去 > 正常来说,单机内多进程使用共享内存就是通过shm或mmap,cxl3.0的共享内存就类似这个,但是GIM呢,难道也要提前mmap吗?恐怕是需要的,一个进程就算能访问所有的物理内存也得先malloc才能访问,对于共享内存也得先shm或mmap才能访问 ## 1 Introduction DSM的相关论文 Efficient distributed memory management with RDMA and caching. {Latency-Tolerant} Software Distributed Shared Memory. Distributed Shared Persistent Memory CoRM: Compactable Remote Memory over RDMA. The Case for Distributed Shared-Memory Databases with RDMA-Enabled Memory Disaggregation相比于传值的RPC,CXL提供了字节寻址直接访问并且有缓存一致性的DSM。
不同的进程/机器可以通过共享并发内存队列交换零拷贝数据引用来进行通信,它避免了输入参数和返回值的(反)序列化和 I/O 堆栈处理的成本。
文章主要提出了一个能够容忍可能的网络、进程和机器故障的自动分布式内存管理系统。
2 The Potentials and Challenges of RDSM
RDSM的应用场景
2.2.1 Pass-by-reference RPC
Unlike the traditional passby-value RPC, pass-by-reference can avoid the expensive data copying in many cases and is therefore widely used in modern distributed processing systems [57, 58, 71, 80](可以研究下这些)
这些系统中,大输入参数和返回值首先存储在分布式对象存储中 [9, 10],然后仅通过 RPC 传递引用
用 RDSM 而不是分布式对象存储来实现引用传递 RPC 的优点有两个。首先,正如 Lightning [90] 所证明的,传统的对象存储架构要求客户端通过 RPC/IPC 与服务器交互。该接口给低延迟工作负载带来了显着的性能瓶颈,并且可以通过基于共享内存的设计来很大程度上缓解。尽管Lightning只是一个基于POSIX SHM的单机多进程内存对象存储,但可以通过RDSM将其架构扩展到分布式环境。
其次,与原始对象接口不同,RDSM 提供内存分配器接口,允许使用链接指针和就地更新构建动态数据结构。这些功能进一步消除了复杂数据结构的序列化和反序列化成本。甚至可以通过使用并发内存队列作为通信通道来避免 I/O 堆栈处理成本,其中内存队列也是共享对象
2.2.2 Shared-Everything Distributed Processing.
一切皆可共享,因为共享内存可以被所有的进程、服务器访问,所以可以实现更好的负载均衡。然而,上述的共享一切架构也带来了许多复杂性,这些复杂性应该被 RDSM 的内存管理系统隐藏。
3 Overview of CXL-SHM
3 Overview of CXL-SHM
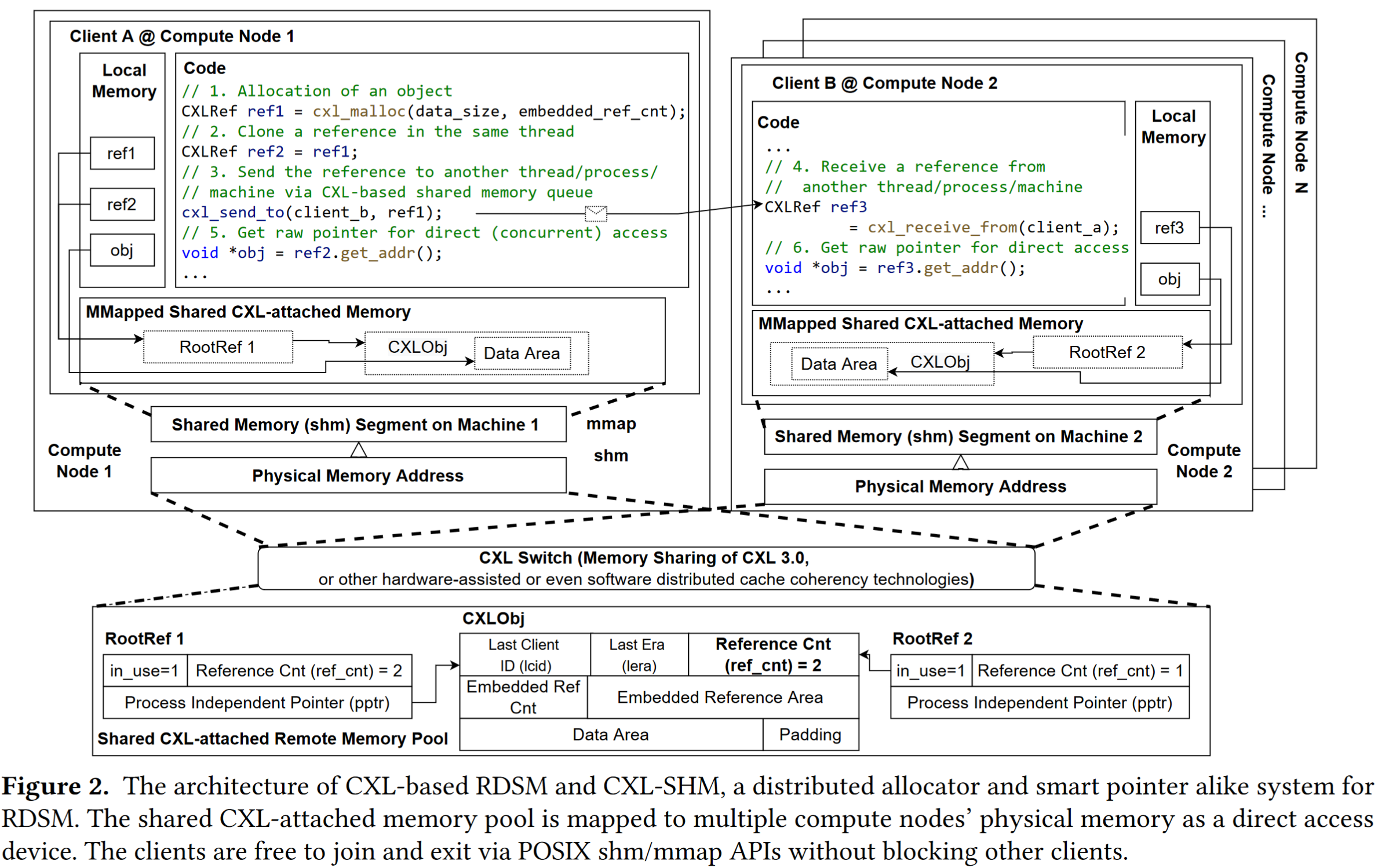
3.1 Interface
cxl_malloc从内存池中申请内存,会返回一个CXLRef,类似一个shared pointer,但是不同点在于1)支持部分失败容错2)不是线程安全的,所以需要显示的复制,复制过程如上图所示cxl_send_to cxl_receive_from来传递引用
3.2 Recovery
与 Lightning [90] 类似,CXL-SHM 使用独立监视器来检测客户端故障(由于进程或机器故障)并异步启动恢复过程。检测故障客户端的机制与我们的主要贡献没有关系,并且需要硬件可靠性、可用性和可服务性(RAS)功能[2]来确保故障客户端在恢复开始后无法修改共享内存池(意思这部分不是我们要做的)
特别强调在CXL-SHM中,恢复不会阻塞其他线程的执行,恢复服务本身是异步的、无状态的和故障安全的。因此,如果恢复服务崩溃(例如,由于机器故障),可以简单地在另一台机器上重新启动,而不会出现任何问题
3.3 Memory Management
基于mimalloc
在mimalloc中,首先通过全局同步从整个内存区域分配线程独占段。每个段的标头之后的区域进一步划分为专用于分配特定大小类别的对象的页面。例如,16 字节大小类别的页被划分为固定大小的 16 字节数据块。页面中的空闲块可以组织为侵入式链表[7]。该列表的头部作为空闲指针存储在页元(段头中的字段)中。它指向该页中的第一个空闲块。每个空闲块都包含一个指向下一个空闲块的指针,如果它是该页中的最后一个空闲块,则为 NULL。通过这种设计,来自段的任何进一步的细粒度分配都在本地执行,因此不需要跨线程同步,即快速路径
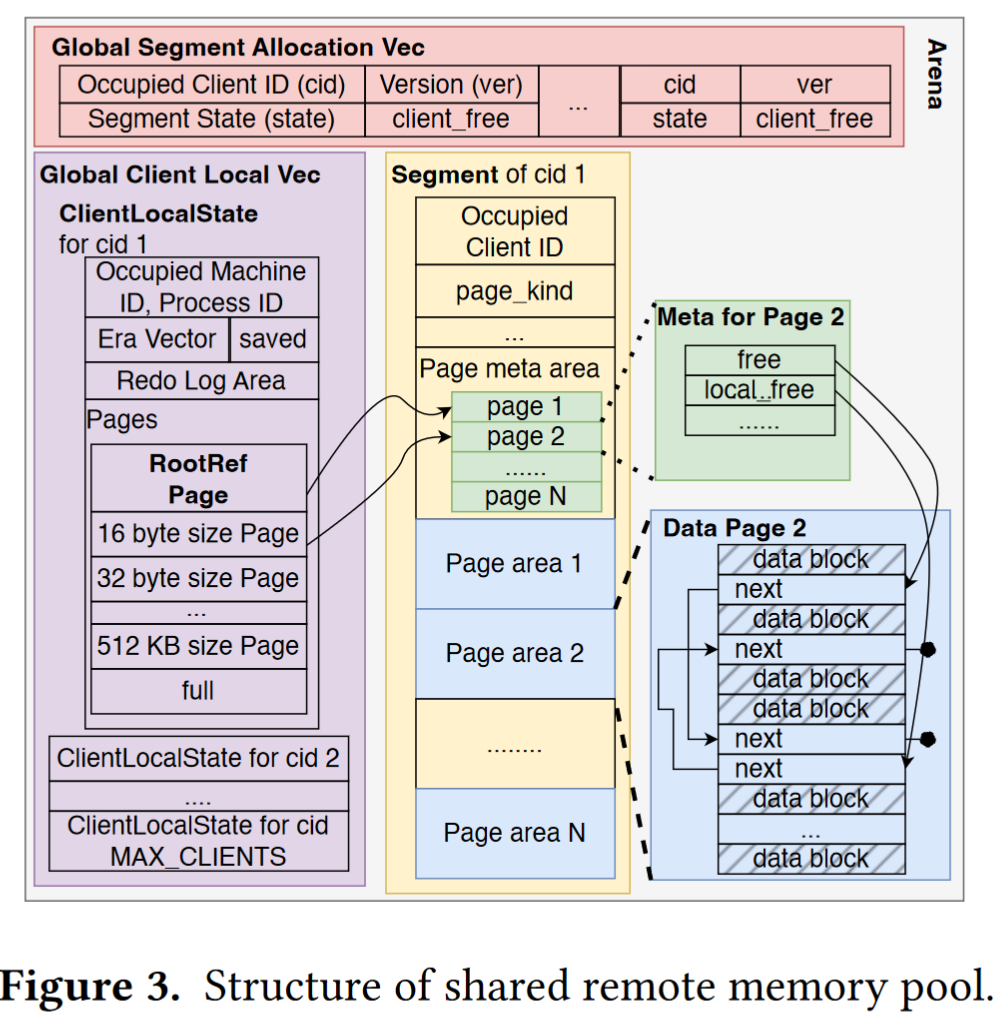
CXL-SHM的组织结构如图所示,
整个共享内存池组织为arena,每个线程首先会从arena中分配一个独占段
前面提到的 SegmentAllocationVec 是用于与其他线程协调并发段分配的元向量,其中的每一个元素表示一个段的占用者,线程可以通过CAS来更新,大于单个段的对象通过占用连续段的简单重试和回滚方法来支持
ClientLocalState 中的大多数字段与 mmalloc 相同,例如指向仍具有可用空间以供进一步分配的页面的大小类别列表。主要区别是:
- 我们的大小类别从 16 字节而不是 8 字节开始,因为每个 CXLObj 都会附加一个标头。
- 除了正常大小类别外,还有一个专门用于仅分配RootRef 的页面的大小类别。这是一个关键的设计,因为在发生故障后,我们只能使用这些页面中的内容来销毁该失败线程所拥有的 RootRef 引用。
- 线程本地状态中有一个事务元字段和一个固定大小的重做日志区域。它们用于从失败的事务中恢复,这将在后面描述
4 Partial Failure Resilient Automatic Memory Management
4.1 Failure Recovery in Persistent Memory
由于进程失败后操作系统可以安全地回收进程的所有内存,因此易失性内存管理系统不需要从故障中恢复。相反,持久内存(pmem)分配器[19,25,39,61,75,83,84]必须考虑“崩溃一致性”问题。但是持久内存分配器必须考虑“崩溃一致性问题”,内存分配和引用链接(将分配空间的指针的值存储到引用中)是两个单独的操作,无法使用单个原子指令来实现。如果只分配内存没有引用链接,就会造成内存泄漏,如果只链接内存,不分配内存会造成野指针问题。
为了解决这个问题,持久内存分配器通常为用户提供 setRoot() 函数来指示某个对象是根对象。根对象记录在发生故障后仍然可以找到的特殊位置,因此 pmem 分配器可以执行垃圾收集以回收未与任何根对象链接的空间。然而,pmem 分配器通常假设一个完整的故障模型,因此使用“stop-the-world”垃圾收集 [25] 从单个进程的故障中恢复。正如我们将在第 6.2.1 节中展示的,当存在大量对象时,这种恢复可能会导致全局暂停几秒甚至几十秒。这个假设简化了它们的实现,并且在持久内存的单机场景下是合理的,因为垃圾收集仅在应用程序重启的初始化过程中执行
而,如§2.1 中所述,远程 CXL 内存可以由单独的 PSU 供电,并通过独立的 PCIe/MCIO 连接连接到处理机器。部分故障不会影响其他活动计算节点的可访问性。因此,需要一种非阻塞恢复方法。
与复杂的大多数并发垃圾收集器不同,如果不考虑失败的可能性,基于引用计数的自动内存管理系统的实现要简单得多。
。。。。。。。
5 Implementation of CXL-SHM
基本上就是讲错误恢复
直接看代码吧,重点看RPC和share everything
代码
Back: you have read it ! Tags: cxl END
 wechat
wechat alipay
alipay


