
Low-overhead General-purpose Near-Data Processing in CXL Memory Expanders
START Basic
TL;DR:利用mem协议解决NDP卸载延迟大的问题,
I. INTRODUCTION
CXL技术提出,延迟对于延迟敏感性应用很重要,带宽也比不过内存带宽,所以NDP是不错的解决方案。
本文提出一种新颖的Memory-Mapped NDP (M2NDP) architecture.基于两个设计
- Memory-Mapped function (M2func) for lowoverhead communication between the host and NDP-enabled CXL memory,
- Memory-Mapped μthreading (M2μthr) for efficient NDP kernel execution.
M2func 有选择地重新利用 CXL.mem 中定义的读写数据包,以实现内存事务之外的高效主机设备通信。
通过将 CXL.mem 请求中的 NDP 管理命令(即函数调用)封装到预先确定的地址,我们可以避免使用 CXL.io / PCIe 的传统卸载的高延迟开销。M2func 的关键推动因素是放置在 CXL 存储器输入端口的数据包过滤器。它检查传入请求的内存地址是否与专用于每个主机进程的预分配内存范围相匹配。然后,为了匹配请求,根据地址触发不同的NDP管理功能。因此,NDP 管理功能调用(例如,内核注册、启动和状态轮询)可以简单地通过从主机发出内存访问来完成。因此,M2func 最大限度地减少了 NDP 卸载的延迟,尤其有利于细粒度的 NDP。此外,我们不需要对 CXL.mem 标准进行任何修改,以获得与主机 CPU 的最佳兼容性。因此,M2func 通过提供干净的函数调用抽象,避免了管理主机和 CXL/PCIe 连接设备之间基于环形缓冲区的共享任务队列的复杂性
此外,我们提出 M2μthr 用于 NDP 的直观抽象和经济有效的内核执行。内存限制工作负载往往比计算限制工作负载使用更少的寄存器。因此,我们提出了一个μthread,它是一个轻量级线程,具有架构寄存器的子集,作为执行单元。通过减少寄存器的使用,NDP单元可以同时执行许多μ线程以隐藏DRAM访问延迟,而无需过多的物理寄存器文件成本(这不就协程吗)
传统的计算会将线程和要处理的数据显式关联,也就是说要计算每个线程处理数据的地址,比如cuda要根据blockid threadid计算索引。但是M2μthread可以直接和内存位置关联即μthread是内存映射的,这样可以避免初始地址计算代码。(看看是怎么实现的)
我们的 NDP 单元的架构基于具有矢量扩展的 RISC-V ISA [6],以利用 SIMD 单元并经济高效地充分利用 CXL 内存中的 DRAM BW,同时支持标量操作,以避免仅 SIMT GPU 中的冗余地址计算
许多内存映射 μthreads 使用细粒度多线程 (FGMT) 执行,以隐藏内存访问延迟
μthreads是单独生成的,这与 GPU 中生成线程块相反,后者可能会由于warp分化而浪费资源
贡献
- general-purpose NDP in CXL
- M2func支持低开销的NDP卸载和管理,克服了 CXL.io 的高开销,实现细粒度 NDP 卸载,同时保留标准兼容性
- M2μthr支持高效的NDP kernel执行
II. BACKGROUND AND MOTIVATION
介绍CXL协议
使用CXL IO/pcie的通信开销,对细粒度卸载影响很大,可以使用更快的mem协议
用于各种设备(例如 GPU、SSD 和 NIC)的常见方法是基于由主机驱动程序和 CXL.io 设备共享和操作的环形缓冲区 [45]。对于 GPU 内核启动,主机运行时首先将内核启动命令写入用户缓冲区,然后驱动程序将指向 GPU 命令的数据包推送到内核空间中的环形缓冲区。然后,主机更新环形缓冲区的写入(或尾部)指针,以通知 GPU 新命令 [92]、[129],这会通过 PCIe 产生额外的延迟,并触发来自 GPU 的两个 DMA 操作来获取 GPU命令。总体而言,主机和 GPU 之间共享的环形缓冲区的复杂操作可能会导致内核启动需要两次半的 CXL.io 往返次数 [45],从而导致约 4.5μs 的高延迟 [94]。为了检查内核完成情况,可以使用轮询或中断,它们会消耗额外的主机处理器周期。 PCIe 轮询可能会产生 2-3μs [67] 开销,而中断具有类似或更高的开销 [58]、[60]、[136]。因此,内核启动和完成检查的总延迟可能会比 2 GHz 下的 5μs 或 10,000 个周期长得多。这种延迟对于粗粒度的 NDP 来说可能是可以接受的,但对于延迟敏感的细粒度 NDP 内核来说可能太高。
但是 CXL.mem 消息的发送延迟较低。当前的 CXL.mem 协议在数据包格式中定义了几个未使用的位。因此,人们可能会考虑使用这些位来编码实现标准中未定义的特殊功能(例如,NDP 管理)所需的信息。然而,为了实现这种定制通信,应该修改主机处理器硬件以支持保留位的特殊用途。因此,仅支持标准协议的商品处理器无法使用它。此外,为了发送特殊数据包,需要在主机的 ISA 中引入特殊指令,如先前的工作 [64]、[78]、[105] 中一样。标准协议或主机 ISA 的这种适当扩展将阻碍广泛采用。
III. MEMORY-MAPPED NEAR-DATA PROCESSING
B. Memory-mapped NDP Management Function (M2func)
IO用于卸载的话通信开销太大,mem不修改的话只支持访存,修改了通用性不强。
提出M2func,其基本思想是在CXL内存中保留一些物理内存空间用于主机通信,称为M2func区域。
为了区分 CXL.mem 的两种不同用法,我们在 CXL 内存的输入端口引入了一个数据包过滤器,用于检查所有数据包并根据数据包地址确定数据包是否应被解释为正常数据包读取/写入或 M2func 调用。
M2func 可以提供不同的功能,包括 NDP 内核注册、取消注册和启动。通过使用距 CXL.mem 数据包的 M2func 区域基址具有不同偏移量的地址,可以调用不同的函数(表 II)。
为了初始化 M2func,主机上的每个用户进程都会在 CXL 内存中分配一个不可缓存的 M2func 区域。通过 CXL 内存驱动程序,可以使用 CXL.io 将区域的地址范围插入到数据包过滤器中。初始化后,NDP 不再需要 CXL.io,CXL.mem 可用于正常读/写和 M2func
对于 M2func 调用,我们使用写入请求格式在请求的写入数据部分中包含参数。为了发送它,主机使用保存参数的寄存器执行存储指令(图 3)。向量寄存器 [6]、[17]、[120] 可用于发送最多可达向量寄存器大小的多个参数。由于 M2func 区域不可缓存,因此写入将绕过主机缓存。但是,对写入请求的响应不能包含来自使用 CXL.mem 的 NDP 控制器的任何返回值数据。因此,我们使用对同一地址的后续读取请求来访问当前进程最近一次调用该函数的返回值。由于返回值将通过正常的内存访问进行访问,因此 NDP 控制器可以简单地将函数的返回值存储在相应的内存地址中,并以正常访问的方式处理读取请求。为了正确排序,主机进程代码应该在请求之间有一个栅栏指令。
C. NDP Kernel Launch
NDP 内核启动可以通过发送带有内核启动参数的写入请求来调用偏移量 2≪5 处的 M2func(表 II)来完成
返回值写在CXL内存上,可以通过memory fence和load指令获得
D. Memory-mapped μthreading (M2μthr)
Fine-grained multithreading (FGMT),
类似GPU的SIMT执行标量操作的性能较差
类似协程的μthreads(SISD+SIMD by RISC-V ISA)
每个μthread和固定的μthread pool region绑定,所以不需要计算地址
Back: you have read it ! Tags: cxl END
为了负载平衡 NDP 单元,μthreads 以内存访问粒度的交错方式映射到 NDP 单元。 μthreads 在批量同步并行模型中同时执行,没有任何顺序保证,就像 GPU 内核中的 CUDA 线程一样。因此,NDP内核应该相应地编写。 ### E. NDP Unit Microarchitecture  其实跟CPU的超线程还是很像的,计算单元共享,有独立的PC寄存器等NDP 控制器命令 μthread 生成器通过在 NDP 单元的子核之间分配 μthread 槽和寄存器文件资源来生成 μthread。使用多个子核而不是单片核可以简化调度单元。 μthread 插槽由 PC(程序计数器)、RISC-V 的 CSR(配置和状态寄存器)、解码的当前指令的操作码和寄存器 ID 以及 INT/FP/向量寄存器的基 ID 组成。基址寄存器 ID 在创建每个 μthread 并为内核分配所需寄存器时确定。只需将逻辑 ID 添加到基本 ID 即可将逻辑寄存器重命名为物理寄存器。此外,前两个非零值标量寄存器(即 x1 和 x2)使用与 μthread 关联的 μthread 池内的地址和偏移量进行初始化。当一个μthread被分配一个槽后,它的PC被内核代码位置初始化以开始执行。
F. Caches Hierarchy
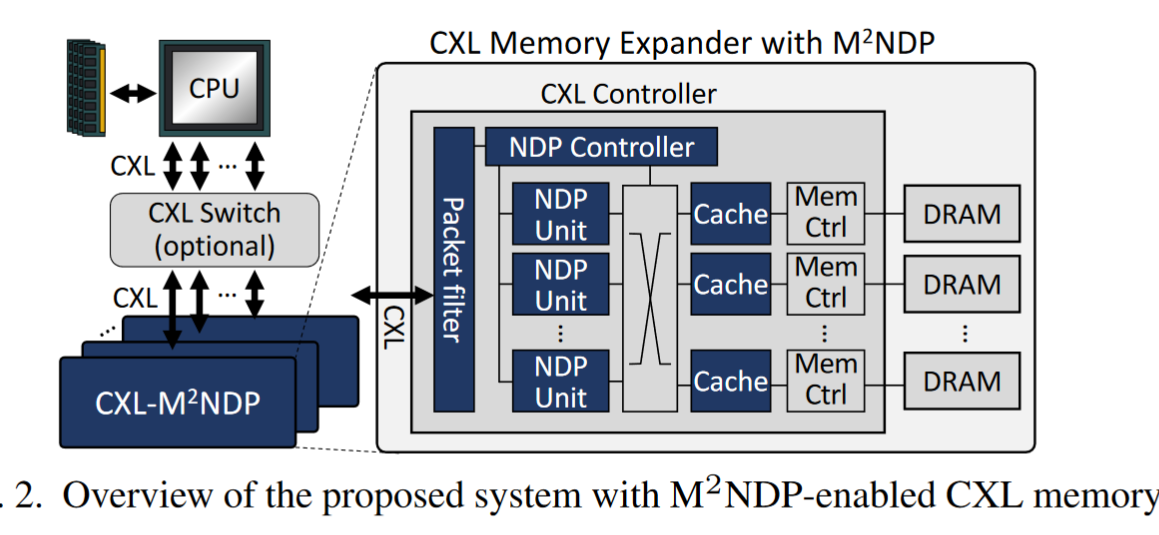
为了避免缓存一致性的复杂性,我们采用GPU的缓存层次结构[127],对NDP单元的L1数据缓存使用直写策略,并将L2缓存放置在内存控制器之前
L1 数据缓存的容量也可以在普通 L1 数据缓存和暂存存储器之间进行配置。 L2 缓存支持对 DRAM 数据的全局内存原子操作。
IV. EVALUATION
具有被动 CXL 内存的基准 CPU 和 GPU 使用修改后的 ZSim [111] 和 AccelSim 进行建模
 wechat
wechat alipay
alipay


