
HydraRPC: RPC in the CXL Era
START Basic
# HydraRPC: RPC in the CXL Era TL;DR:1 Introduction
传统的RPC基于消息传递,但是CXL可以基于共享内存
三个问题
1)如何设计RPC的控制平面和RPC协议,以充分发挥CXL HDM的潜在性能;
2)CXL HDM提供共享内存接口。如果没有消息传递接口,就没有高效且易于使用的机制来通知CPU请求/响应到达;
3)在RPC场景中使用CXL HDM时如何管理它。
延迟低、拓展性好
Challenges of State-of-the-art RPC
现有RPC的挑战,
网络开销
数据复制开销
拓展性问题
相较于传统的传值,基于共享内存的通信只需要传引用
优势包括
- 不涉及网络通信
- 字节寻址,可以对动态数据就地更新。这消除了序列化和反序列化的需求从而提高性能
为什么要不过cache的CXL内存访问?
不是3.0的共享内存,是在2.0的池化基础上做的,可以访问同一块内存,但是没有缓存一致性.mem协议、,所以手动规定不能被缓存,保证正确性
Design of HydraRPC
5.1 Architecture Overall
每个RPC链接都有两个消息队列和相应的数据区,消息队列传递引用作为请求、相应缓冲区,数据区存储请求、相应的原始数据。
消息队列每个条目大小64位,包括63位偏移量和1位到达标志
控制层:与普通 RPC 类似,HydraRPC 在每个物理服务器中至少维护一个 RPC 服务。当应用程序部署时,它与此类服务连接,该服务将为服务器端和客户端分配CXL HDM中消息队列和数据区的全局地址。然后遵循服务器和客户端之间典型的握手协议[40],建立RPC连接。
HydraRPC包括三个步骤:客户端请求、服务器执行、响应客户端。
请求阶段:客户端首先将用户定义的请求数据写入数据区域中预分配的内存,该数据区域是缓存行对齐的以启用不可缓存共享(参见第5.2节)。接下来,客户端将一个条目附加到请求消息队列中。在发送下一个请求之前,不需要等待服务器端的响应(参见5.5节滑动窗口机制)。同时,服务器轮询请求消息队列尾部条目中的到达标志。
执行阶段:一旦获得新的请求,工作进程就利用条目中的偏移量来执行该请求。对于轻量级 RPC 请求,HydraRPC 遵循“运行到完成”原则,将执行阶段内联到轮询过程中 [11]。如果服务器已准备好响应数据,则将其写入数据区域中预先分配的内存。为了减少内存复制,服务器可以在执行期间直接使用预分配的内存。
响应阶段:响应阶段可以包括将数据捎带至客户端。因此,服务器将一个条目附加到响应消息队列中。然后,发送请求的客户端将轮询响应消息队列中的条目。当客户端确认响应时,RPC 过程被认为完成
5.2 Non-cachable sharing
2.0没有缓存一致性的共享,而作者又认为3.0的共享开销大,所有提出非缓存一致性版本
MTRR。英特尔的内存类型范围寄存器(MTRR)技术[31]提供了一种控制物理内存区域的访问和缓存能力的方法。此方法在 Intel 和 AMD CPU 中均可用。它通过优化 CPU 缓存某些范围的内存地址的方式来提高系统性能,从而允许诸如直写、写组合或回写缓存等变化。
设置 MTRR 有两种接口:一种是 ASCII 接口,允许在 /proc/mtrr 中读写;另一种是 ioctl() 接口。此外,参数是内存区域的物理基地址和长度。我们从ACPI中的SRAT获取CXL HDM的物理内存区域,然后使用ioctl将该内存区域的属性设置为不可缓存。
非时间访问。 Intel ISA 提供了 clflush、clwb 或 ntstore 等特定指令来刷新或直接将数据写入 CXL HDM。在 HydraRPC 中,客户端和服务器端都使用非临时内存操作。为了确保数据从 CXL HDM 而不是本地缓存(即可见)加载或存储,我们使用 clflush/prefetch 来绕过本地缓存。然后是内存存储/加载栅栏(sfence/lfence)以同步非临时访问。我们评估了这两种绕过缓存机制的延迟,它们表现出相同的性能。因此,我们在后续的实验中不会区分它们。
5.3 Notification
HydraRPC 需要一种通知机制来通知客户端/服务器请求/响应的到达。这样双方就可以按时处理请求/响应。我们在HydraRPC协议中提供了两种方式
基于轮询的优化。为了实现最佳的低延迟,HydraRPC 利用 CXL HDM 上的轮询来检测传入的请求/响应 [23, 47]。在这种方法中,CPU 读取请求/响应条目的到达标志,并在到达标志有效时启动处理。然而,这可能会导致不必要的工作,因为 CPU 可能会多次读取和验证到达标志。为了缓解繁忙轮询期间内存位置旋转的问题,我们利用两个内在函数(monitor 和 mwait),专门为具有流 SIMD 扩展 3 (SSE3) 的 Intel 处理器设计。此外,它们还有用户模式的等效项(umonitor 和 umwait)。客户端/服务器可以针对循环缓冲区以高速缓存行粒度发出监视指令。随后,执行 mwait 指令以暂停 CPU 并节省电量。当监控到的数据被对方修改时,CPU就会被唤醒。这种方法有效减少了CPU占用并提高了内存轮询的性能。
基于中断。即使在优化轮询之后,CPU 开销也不能忽略。目前,PCIe MSI(消息信号中断)允许 PCIe 设备通过消息而不是物理中断线向 CPU 发送中断信号 [6]。通过为每个设备允许多个可扩展的中断向量,PCIe MSI 的通知机制可提供更高的性能。幸运的是,CXL 的事务层基于 PCIe,因此 MSI 在 CXL 3.0 规范中实现。我们可以在修改内核的MSI表中定义新的中断类型。当新的内存写入即将到来时,它会启动针对主机软件的内存写入事务层数据包 (TLP)。该 TLP 数据包是使用源自 MSI 表中相应条目的地址和数据生成的。随后,主机的中断服务例程将 TLP 识别为中断并相应地对其进行寻址,并且 RPC 处理被唤醒。由于我们平台中的当前邮箱无法启用注册来发出 MSI 信号,因此我们将把它留到将来的工作中。
5.4 Memory Management
消息队列使用固定大小的内存池,数据队列使用CXLSHM中描述的两层分配器
当有多个连接,可以共享消息队列,这样可以减少轮询的开销
使用滑动窗口来控制消息队列
6 Demonstrations and Evaluations
6.1 Performance
延迟低
原始加载/存储延迟为 300 ns,无需添加额外的刷新指令。 HydraRPC 的平均延迟为 1.47μs。相对于原始 CXL 访问延迟(约 300 ns),假设总共有 4 次 CXL 访问,mRPC 增加了 0.27μs 的额外延迟,主要由于轮询和内存管理的开销
带宽高
mRPC 和基于 RDMA 的 RPC 的吞吐量较差。性能下降的原因是这两个RPC受到RDMA网络最大带宽的限制。在HydraRPC中,请求/响应数据可以就地更新,可以进一步利用CXL HDM的高带宽
6.2 Efficiency
拓展性
增加线程数,RDMA的拓展性差
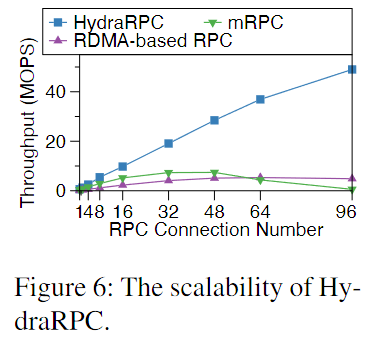
CPU开销低
低负载场景下,HydraRPC的CPU占用率低

6.3 End-to-end Application
TensorPipe 是一个开源库,用于分布式机器学习中的高性能张量传输,可实现高效的 GPU 通信。 TensorPipe 具有共享内存(SHM)传输,同一服务器上的两个进程可以使用它来通过执行以下方式进行通信
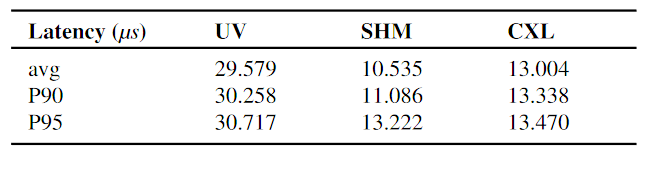
使用 HydraRPC 作为传输的 Tensorpipe 的延迟比使用 UV 库 [36] 至少低 2 倍。与利用本地共享内存但不支持节点间 RPC 的 SHM 传输相比,它表现出相似的性能,但延迟仅增加了 20%。
7 Related Works
NCCL [27]利用共享内存作为其通信方法之一,以在同一节点内的 GPU 之间有效地传输数据。这种方法利用共享内存的高速数据交换能力,减少数据通过较慢的 PCIe 总线传输的需要,从而加速节点内 GPU 通信。在 Linux 内核中,SMC(共享内存通信)[25] 利用共享内存来实现快速高效的数据传输。通过使用共享内存缓冲区,SMC 绕过了传统的 TCP/IP 堆栈,减少了通信延迟和 CPU 利用率
8 Conclusion
在本文中,我们提出了 HydraRPC,它通过一个 CXL HDM 实现跨节点 RPC。 HydraRPC 利用不可缓存共享和零复制数据布局来启用基于 CXL 的 RPC,并应用滑动窗口和总线轮询免费通知机制以获得更高的性能。我们真实平台的结果表明,HydraRPC 可以享受内存共享的好处,并且比基于 RDMA 的 RPC 实现高几个数量级的吞吐量。
Back: you have read it ! Tags: cxl END
 wechat
wechat alipay
alipay


