
DFabric: Scaling Out Data Parallel Applications with CXL-Ethernet Hybrid Interconnects
START Basic
TL;DR:结合CXL和以太网,实现两层互联架构,解决数据密集型应用的通信困难 ## 1 Introduction cxl互联可以很好的解决分布式数据密集型应用中的通信问题 > 在当今的生产云中运行的数据密集型应用程序,例如图形处理[47]、数据分析[17]和深度神经网络(DNN)训练[44]通常使用批量同步并行(BSP)[65]或MapReduce来运行范式,这需要两个关键阶段的迭代执行:跨多个计算单元的数据计算(例如,DNN 训练中的前向和后向传播),以及这些单元之间的通信(例如,MapReduce 中的数据混洗)。此类应用程序是计算密集型的并且非常耗时。例如,在单个 TPU 上训练 BERT 模型需要超过 1.5 个月的时间由于CXL互联的长度限制,通常在只在机架内部,机架之间通过以太网连接。
然而,跨越多个主机或机架超出互连的到达极限,其通信效率不可避免地受到主机之间缓慢的网络链接的阻碍。
解决这一差距的直观方法是构建一个聚合容量大于互连容量的 NIC 池,旨在实现超出互连范围限制的高效通信。然而,由于带宽差异巨大,为每个节点的本地互连构建单独的池成本高昂。例如,为了匹配 CXL 3.0 链路的带宽,每个主机需要安装十个以上 200 Gbps NIC。相反,我们建议在更大规模(即机架级别)上使用快速互连来连接主机和计算节点,因此可以利用主机中足够数量的现有 NIC 来形成用于跨机架通信的 NIC 池。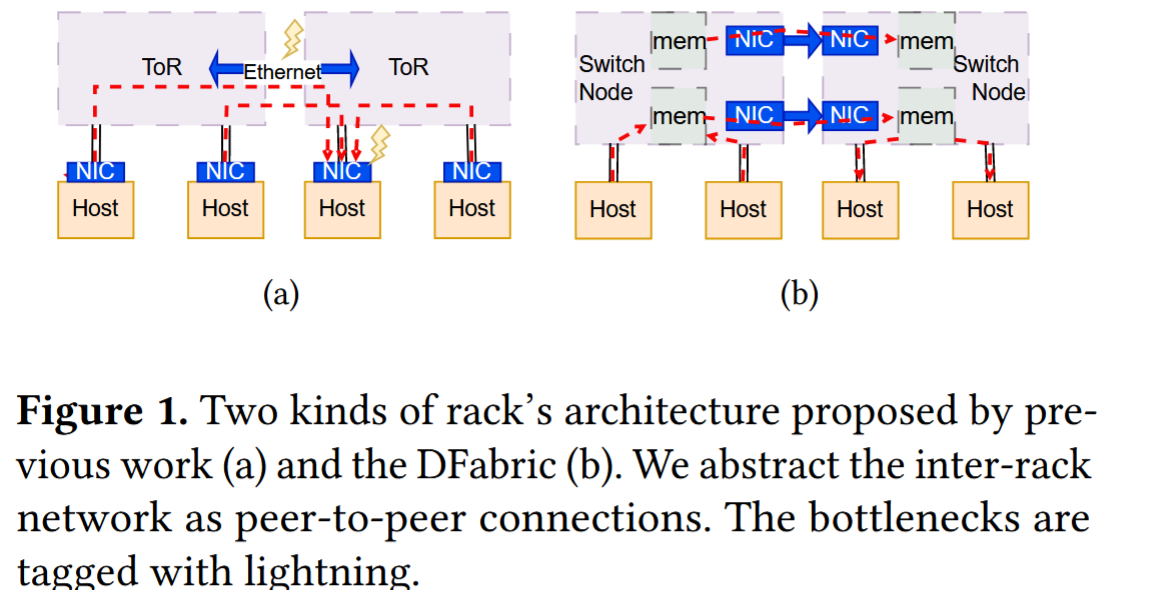
我们提出了 DFabric,一种两层互连架构。机架内CXL互联,机架间网络。
然而新问题是,内存带宽成为瓶颈,小于NIC带宽,当通过NIC进行DMA,内存带宽成为限制因素。解决办法是用CXL将所有的本地内存和附加内存分解为远程内存,并将他们映射到同一个地址空间中,构建一个可由任何设备连贯访问的共享内存池。因此,从 NIC 池接收的网络流量可以写入多个内存设备,聚合内存带宽大于 NIC 池的容量。同样,当通过池发送流量时,NIC 池使用 DMA 从多个内存设备读取数据。通过与共享内存池对网卡池进行补充,DFabric最大限度地缩短了跨机架通信周期,计算节点可以通过加载/存储指令(CXL.mem)直接访问内存池,而无需将数据移动到本地,从而释放硬件计算吞吐量
此外,无可否认,实现 DFabric 还存在其他几个关键挑战,例如,CXL.mem 加载/存储是同步的,基于缓存行的指令与 DMA 相比,访问大内存区域的效率较低,如何高效的使用pass by reference;给定的应用使用socket编程等等。
我们在设计中解决了这些挑战,并实现了一个全功能的 DFabric 原型,该原型具有四个定制的 MPSoC FPGA 和一个通过光纤连接的 X86 服务器,而不是在之前的工作中使用模拟器和 NUMA 节点
我们运行了微基准测试和真实的数据密集型应用程序,例如 DNN 训练、图形处理,结果表明,与使用传统的基于 ToR 的机架运行相比,DFabric 减少了 30.6% 的几何平均通信时间。 DFabric 运行 Redis 时的 p99 尾延迟也降低了 40.5%。
2 Background and Motivations
challenges
- 内存带宽相比NIC带宽成为瓶颈:用CXL池化所有内存资源,聚合带宽
- 远端内存访问延迟高:引入DRAM缓存,利用缓存来隐藏延迟
- 兼容性问题:大多数数据密集型应用使用套接字编程模型开发,为了改成引用传递语义,引入一个内核模块,可以将套接字系统调用转为.mem系统调用
- 网课池带宽共享:跨机架流量利用所有可用的 NIC 遍历多个路径。这增加了数据包无序到达的风险,可能会破坏 TCP 的有序语义。为了解决 C4 问题,DFabric 依靠内存池来缓冲无序到达,并让主机操作系统使用多路径 TCP (MPTCP) 对数据包进行排序
3 DFabric Overview
architecture
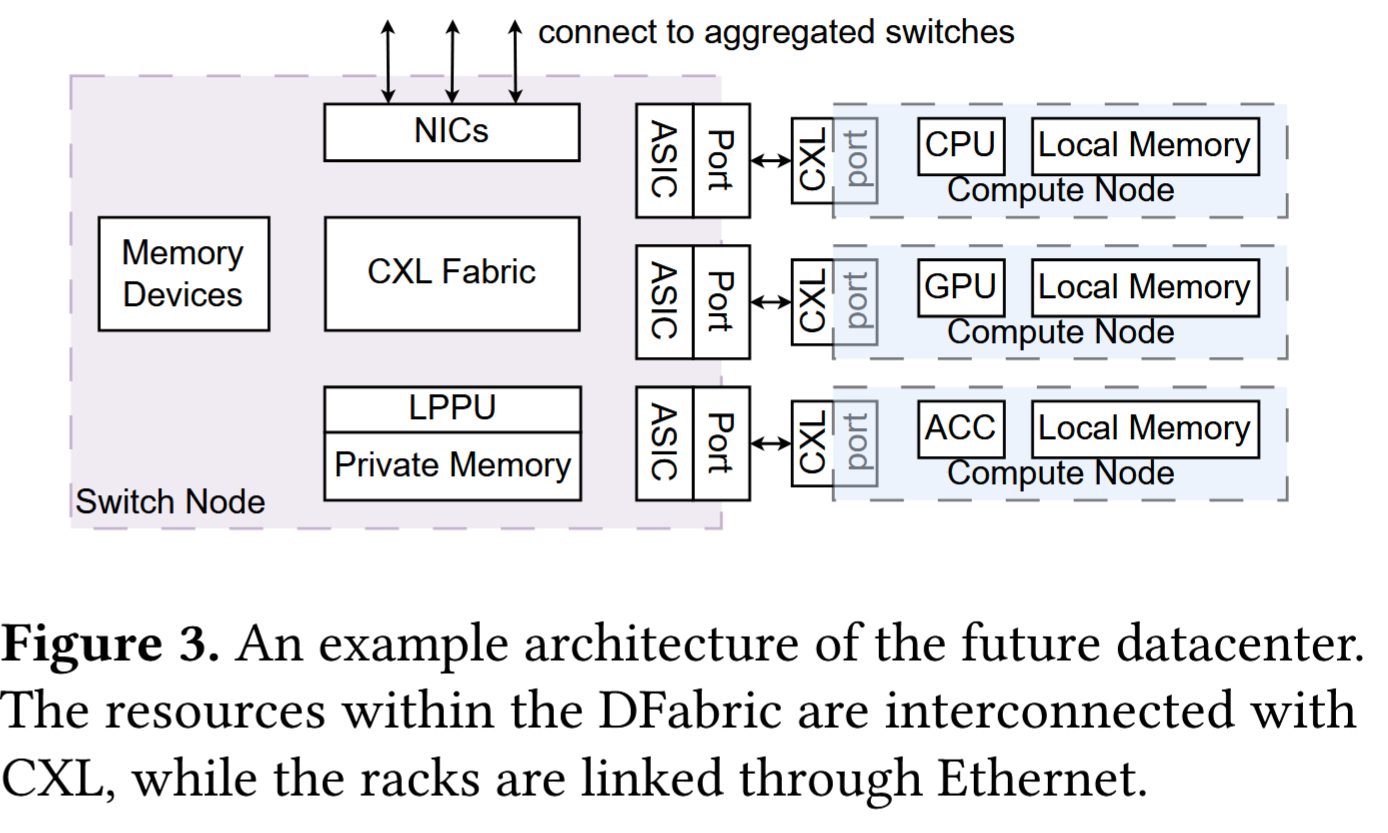
传统的host简化成CN,配备本地内存,部分本地内存被分解,与附加的远端内存一起构成逻辑共享内存,剩余的本地存储器被指定为CN的私有存储器。该内存池集成到统一的虚拟地址空间中。可通过 CXL.mem 和 CXL.io 协议实现一致的访问(只是type3),
网卡池可以容纳多种网卡类型,进一步增强了系统的灵活性,LPPU是一个特殊的CN,专用于一些簿记任务,例如枚举、注册和管理 NIC。
NIC 池作为单个“大”逻辑 NIC 集成到地址空间中来虚拟化 NIC 池,这将池暴露给所有 CN,并支持跨机架流量的基于数据包的调度,从而优化流量分布和带宽分配。所有资源节点,包括 CN、远程存储设备。
CN通过Fabric中的CXL交换访问远程资源设备,形成逻辑交换节点logical switch node(SN)。
workflow
尽管底层数据结构(无锁环形缓冲区)并不新鲜,并且在[21,62,75]之前就已经使用过,但我们的抽象使用相同的 Socket 编程模型统一了机架间和机架内通信。
对于机架内通信,CN 通过引用传递语义进行通信,该语义使用 CXL.mem 加载/存储来传递引用而不移动数据(第 4.3 节)
对于机架间通信,NIC 池 DMA 事务分为两部分(第 4.4 节)。每个 CN 在其本地内存中分配多个虚拟 TX/RX 队列对。在发送机架上,CN 将数据包描述符写入其本地内存中的虚拟 TX 队列。对于每个 CN,端口处都有一个特定的 ASIC 来轮询这些队列中的描述符。当读取到有效描述符时,ASIC将描述符写入NIC的工作队列。以上所有读取和写入均使用 CXL.mem 加载和存储指令。 NIC 和虚拟 TX/RX 队列之间的映射由 LPPU 确定。 LPPU 还负责 NIC 调度(第 4.2 节)和内存池分配(第 4.1 节)。
在接收机架处,接收缓冲区从内存池中分配,总内存带宽大于网卡池容量。因此,数据包可以以 NIC 池的全速 DMA 到内存池。有一个专用的 ASIC 来轮询 NIC 池的所有完成队列。对于每个就绪描述符,ASIC根据描述符的目的IP将描述符写入CN对应的虚拟RX队列,然后中断CN。
4 Design Details
4.1 Memory Pool

organization
LPPU 将共享内存池组织为一系列粗粒度的部分,每个部分的大小等于大页 (2 MB) 的大小。 LPPU还将N个连续的Section分组到一个区域中,其中N是可配置的,在我们的例子中N=512。将Section分配给CN后,Section可以进一步被CN划分为Buffer,缓冲区大小根据运行应用程序的需求设置(API如表2所示),例如具有1 KB Buffer的Section。
Bootstrap
LPPU 枚举 CXL Fabric 附加的远程内存设备和 CN 在内存池中的本地内存,并构建将 FAS 映射到内存物理地址的映射表。然后,每个 CN 枚举 FAS 和私有内存,以便它可以使用 CXL.mem 访问池。注意CN的私有内存有不同的地址空间,用于内核,缓存程序代码和热数据。我们进一步使用私有内存来实现 DRAM 缓存,用于向 CN 隐藏内存池的非均匀延迟
Memory allocation
每个CN上运行的守护进程负责提前分配Sections并管理它们。 LPPU更新从相应FAS到CN映射表中Section物理地址的映射。与Linux伙伴子系统类似,守护进程应用多个Section,每个Section具有不同的缓冲区大小、最小内存管理单元,例如具有2KB缓冲区的Section。
在 CN 中运行的应用程序在调用 alloc_shared_buffer 时将咨询守护进程以获取用户级内存分配。具体来说,守护进程将执行以下步骤:1)它根据应用程序语义选择具有所需缓冲区大小的Sections,2)它根据Sections的物理位置选择Sections。这是因为,从 CN 的角度来看,内存池的访问延迟曲线根据内存的物理位置而不同。例如,我们更喜欢本地部分来存储虚拟队列以最小化访问延迟。
4.2 NIC Pool
DFabric 将 NIC 与主机解耦,形成 NIC 池,并通过 CXL 结构将它们互连。 CXL 结构为 CN 提供单一 NIC 抽象。 LPPU负责NIC池的控制平面,包括配置NIC和NIC调度。为了高效、灵活地调度NIC池容量,LPPU以数据包为基础基于他们的工作状态进行NIC调度,例如 NIC 的工作队列深度。
NIC 池及其元数据如图 5 所示。元数据用于机架内和机架间通信。 LPPU 通过存储在内存池中的一组虚拟队列 (virt_queue) 将 NIC 池抽象为每个 CN 的单个 NIC。 virt_queue 包括 RX 队列(RxQ)和 TX 队列(TxQ)。 LPPU 在其私有内存中维护每个 NIC 的工作队列(physical_queue),并将它们用于 NIC 调度(参见第 4.3 节)。 CN 和 LPPU 分别负责在 bootstrap 启动 virt_queues 和 phy_queues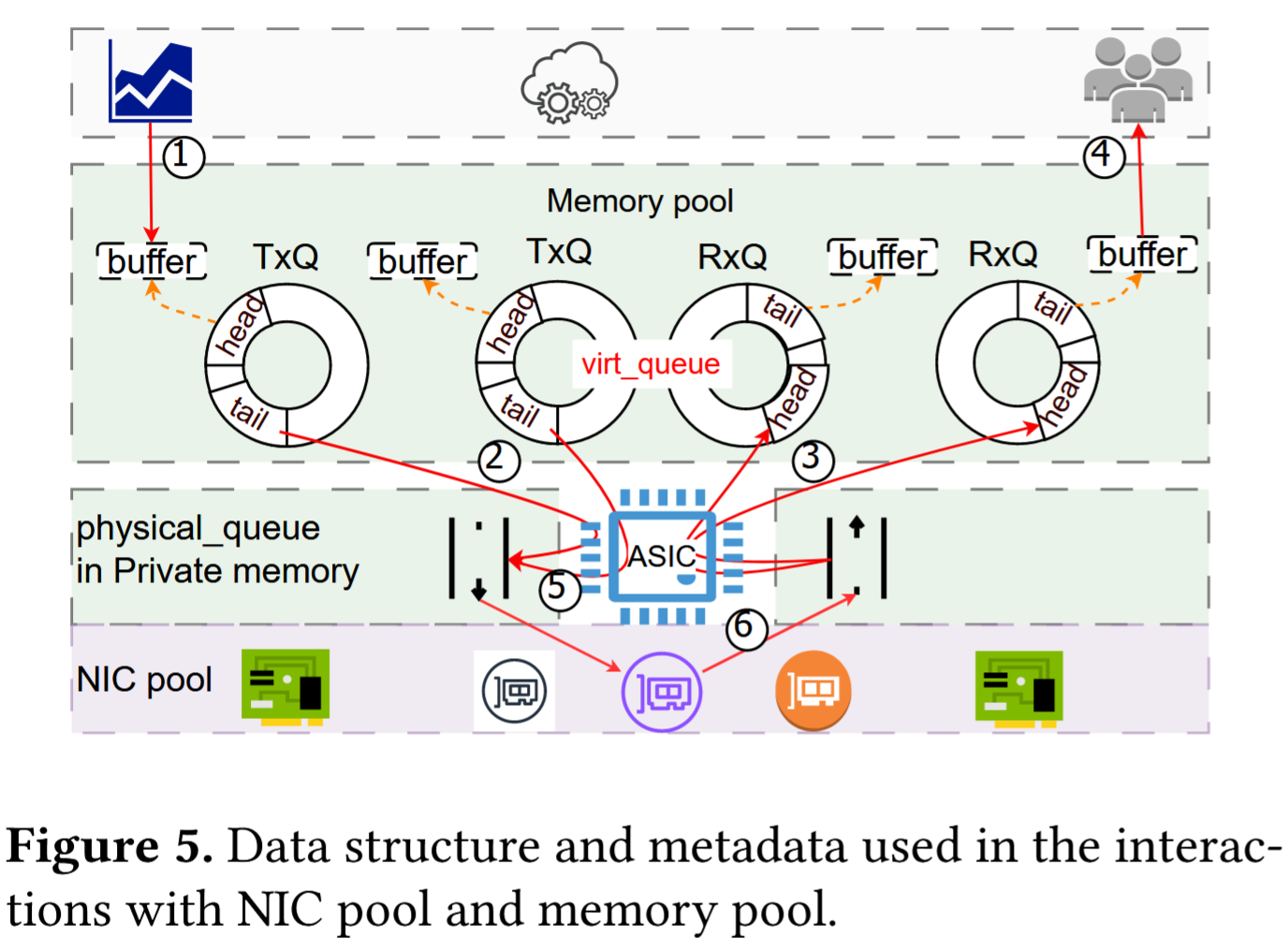
4.3 Intra-rack Communication
机架内使用传引用语义通信,无需移动数据,为了识别引用的目的地,每个 CN 都有一个唯一的 ID(例如 IP)。通信语义是将共享内存中数据的寻址引用从 CN I Dsrc 转移到 CN I Ddst ,以便 CN I Ddst 可以加载/存储它。
DFabric 将事务描述符存储到 virt_queue 中,其中每个条目包含事务的 I Ddst 和 I Dsrc 、引用以及它引用的数据的长度。
机架内通信分为以下几个阶段
- 数据准备:源地址直接读写数据①
- TxQ:源CN将缓冲区的描述符存储到TxQ的头条目,TxQ是环形缓冲区,srcCN轮询TxQ,通过检查TxQ的尾部来获取新的描述符②
- ASIC检查目的地是NIC还是另一个CN,前者通信实例化(见4.4),后者直接将缓存区的描述符存储到目的CN的RxQ头条目中,写入到中断寄存器。③
- RxQ:目的运行时加载 RxQ 的尾部条目,并通知应用程序数据引用➃
- 释放缓冲区,一旦应用程序或运行时不再使用 Buffer,它就会将 Buffer 的地址释放给守护进程。如果有足够的Buffer,守护进程会进一步释放Buffer给LPPU。
提出的按引用传递机制可实现零数据复制,并使用套接字编程模型与应用程序透明地协作(参见第 4.5 节)。我们还可以类似地将引用传递机制应用于 DPDK [20] 和 RDMA 动词。
4.4 Inter-rack communication
尽管 NIC 池允许 CN 利用多个 NIC 来实现更高的吞吐量。我们面临两个挑战。 1)由于每个网卡的physical_queue的工作状态及其背后的路径条件随着时间的推移而变化,因此设计灵活高效的网卡调度策略非常重要,该策略可以在更细的粒度(例如基于数据包的基础)上运行,同时充分利用网卡池的容量。 2) 当使用多个网卡调度一个流时,由于路径延迟可能不同,因此很难确保数据包按顺序到达。如果底层传输强制按顺序到达,例如 TCP,则无序到达将触发拥塞控制,从而不必要地降低发送吞吐量。因此,对于 NIC 调度策略来说,尽量减少无序到达也很重要。
DFabric 的 NIC 调度。 CN 将每个流均等地划分为子流,并将每个子流映射到 TxQ/RxQ 对。 LPPU 根据 NIC 的利用率(例如 NIC 的物理队列深度)将 TxQ 多对一映射到 NIC(例如通过网络适配器管理工具 NEO-Host [52] 使用 NVIDIA RNIC 的硬件计数器)。请注意,我们假设核心网络中不存在下行链路,并且每个子流在穿过网络核心时都通过 ECMP 映射到固定路径。因此,只有当 CN 能够生成足够数量的子流,同时确保子流内按顺序到达目的地时,DFabric 才能充分利用 NIC 池。为此,我们在发送 CN 的操作系统中利用类似 MPTCP 的间接性,它可以打开足够数量的 TCP 子流,同时在接收 CN 处将 TCP 子流重新排序为有序数据流 [25]。
对于机架间通信,我们假设每个网卡都有三个physical_queues; TX_phq、RX_phq 和completion_phq,如图 5 所示。
数据包传输。 I Dsrc 的 ASIC 轮询内存池中的所有 TxQ。对于每个 TxQ,LPPU 已调度 NIC 来发送 TxQ 中的条目引用的缓冲区。 ASIC 将 DMA 描述符存储在该 NIC 的 TX_phq ➄ 中。然后通知 NIC 的 DMA 引擎从引用的缓冲区收集数据并执行网络打包。
数据包接收。 LPPU预先在内存池中分配多个Buffer作为pool的接收缓冲区。 NIC 的接收缓冲区应具有比 NIC 池的吞吐量足够的内存带宽。 LPPU 还预先用引用接收缓冲区的 DMA 描述符填充每个 NIC 的 RX_phq。对于每个数据包的到达,NIC 的 DMA 引擎直接将有效负载写入有效队列中 DMA 描述符指定的缓冲区。一旦 DMA 引擎完成 DMA 操作➅,完成通知就会存储在 NIC 的completion_phq 中。专用 ASIC 负责轮询这些completion_phq并通知 CN 数据到达,方法是根据数据包的 IP 存储 CN 的中断寄存器,并使用 CXL 存储 ➂ 将缓冲区的引用存储在 RxQ 中。最终,CN 可以在计算期间加载/存储缓冲区
4.5 Software Runtime
为了使应用程序能够透明地享受按引用传递语义,DFabric 提供了一组用于 TCP/IP 堆栈的 API,以及堆栈下方的驱动程序来协调机架内通信。
。。。。。。
4.6 CXL-attached DRAM Cache.
CXL 加载/存储是同步且细粒度的内存访问,这限制了访问远程内存设备中分配的缓冲区的吞吐量,这在内存访问模式上表现出局部性。例如,将连续数据从内核复制到用户模式可能会表现出高空间局部性。由于 CXL 和 CPU 结构 (MSHR) 限制了加载/存储指令的最大未完成数量,因此通过缓存或迁移减少内存延迟是提高带宽的唯一方法。
最近的工作 [8,26,77] 验证了附加 CXL 的加速器可以在缓存行粒度上跟踪内存访问,并且我们可以在不修改整个机箱的情况下升级或替换它们。与缓存相比,页迁移[41,48,70]需要运行时识别热点页,将它们迁移到本地内存,并更新页表。我们设计在所有 CN 的一个 CXL 端口中安装 DRAM 缓存卡。
通过分析TCP/IP协议栈,我们总结了指导DRAM缓存设计的三个关键点。 1) 访问标头和有效负载之间的可变时间间隔。运行时分别在中断的下半部分和 recv 系统调用期间处理数据包标头和数据。因此,两者之间会有一个时间间隔,在此期间可以将数据逐出缓存。 2) 显式调用缓冲区释放函数。由于运行时显式调用缓冲区管理 API,因此一旦调用缓冲区释放函数(即 kfree_shared_skb),就会将缓冲区从缓存中刷新出来。 3) 可变数据包粒度。数据包大小可能是几个缓存行,例如 TCP SYN 和 ACK。粗粒度的缓存数据会导致缓存利用率低,延迟时间长,因此缓存前需要对数据包进行过滤。
图 6 所示,我们使用多路 DRAM 缓存来解决可变间隔期间冲突导致的潜在驱逐问题。元数据(Tags)单独存储在片内存储器中,这样一次读取即可获得整组元数据。 DRAM缓存的使用可以总结如下。 ➀ 驱动程序配置一个区域的FAS——连续数量的Section,其Buffer将被缓存在DRAM缓存中,以及缓存粒度,即Buffer大小。首次访问 Region➁ 中的 Buffer 时,会触发未命中,并通过 CXL.io ➂ 从内存池中获取 Buffer。然后,DRAM 缓存填充有效的元数据并逐出受害者缓冲区。以下对 Buffer➁ 的访问将命中本地 DRAM 缓存。当运行时决定释放缓冲区时,将显式调用 kfree_shared_skb 并刷新 DRAM 缓存。
目前,DFabric 使用 DRAM 缓存来提高加载/存储大内存段的吞吐量。然而,缓存设计是通用的并且独立于运行时,因此应用程序可以通过配置其区域的FAS来透明地使用DRAM缓存。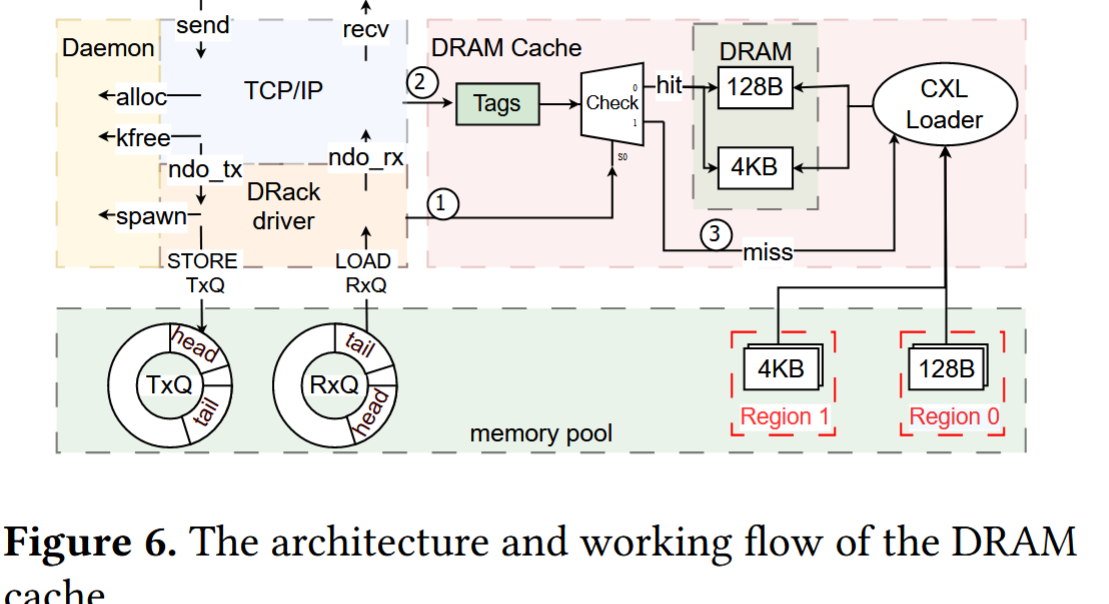
4.7 ASIC Architecture
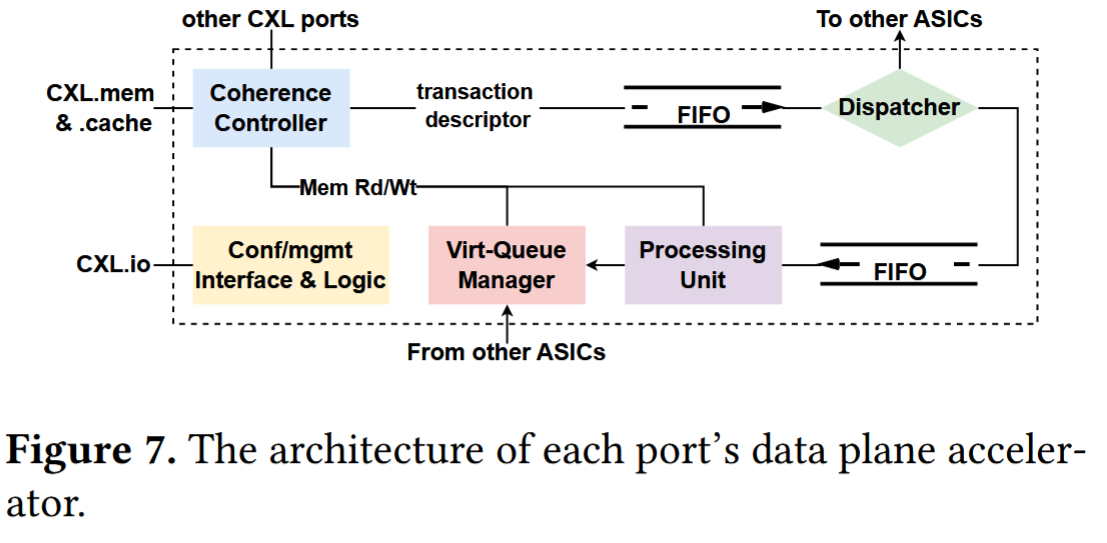
5 Implementation
考虑到没有支持 CXL 3.0 的商业产品,我们实现了一个概念验证双机架系统原型,如图 8 所示。我们使用该原型来模拟双 DFabric 架构以及基于双 ToR 的机架架构作为基线。在一个机架中,有两个定制的 MPSoC FPGA [73] 作为 CN。每个FPGA都有一个四核ARM CPU、两个内存通道和四个光纤端口。 MPSoC 通过 HP/HPC 端口将 CPU 内存总线导出到 FPGA 逻辑,可用于实现类似 CXL 的加载/存储。我们将两个 FPGA 连接到安装在 x86 服务器上的双端口 Intel 82599 NIC [30]。我们使用该 x86 服务器来模拟 DFabric 的两个 SN,以及用于基准系统的两个 ToR 交换机。我们使用在 x86 服务器中运行的基于 DPDK 的网络模拟器 [20] 来模拟 NIC 池和机架间通信。
在 CXL 3.0 中模拟 CXL 结构的关键是外部化加载和存储。这允许应用程序透明地访问内存池内的远程内存设备,从而实现遗留应用程序的无缝执行。为此,我们利用 DoCE [10],一个硬件协议栈作为我们类似 CXL 的协议层的基础。 DoCE 直接将所有 ARM AMBA AXI 片上互连信号封装在以太网框架内,这些信号可以通过标准以太网基础设施传送。我们没有使用 DoCE 将 AXI 信号打包到以太网数据包中,而是使用类似 CXL 的协议层增强了 DoCE,并将它们实现为 MPSoC FPGA 中的硬件模块(即 CXL-DoCE),它将 AXI 信号转换为相关的 CXL 事务,例如如 MemRd、MemWr、Cmp 和 MemData。如图 8(a) 所示,任何从 CPU 访问远程内存的内存事务都将通过硬件,硬件将其转换为具有类似 CXL 事务的以太网数据包,并通过光纤端口发送。同样,从端口接收到的任何以太网数据包都将通过该模块,如果该数据包包含类似 CXL 的事务,该模块会将其转换为 AXI 信号以访问本地内存。请注意,以太网数据包可以封装不限于类似 CXL 的事务,只要模块可以识别它们即可,例如,如果以太网数据包携带中断事务,则模块可以中断 ARM CPU。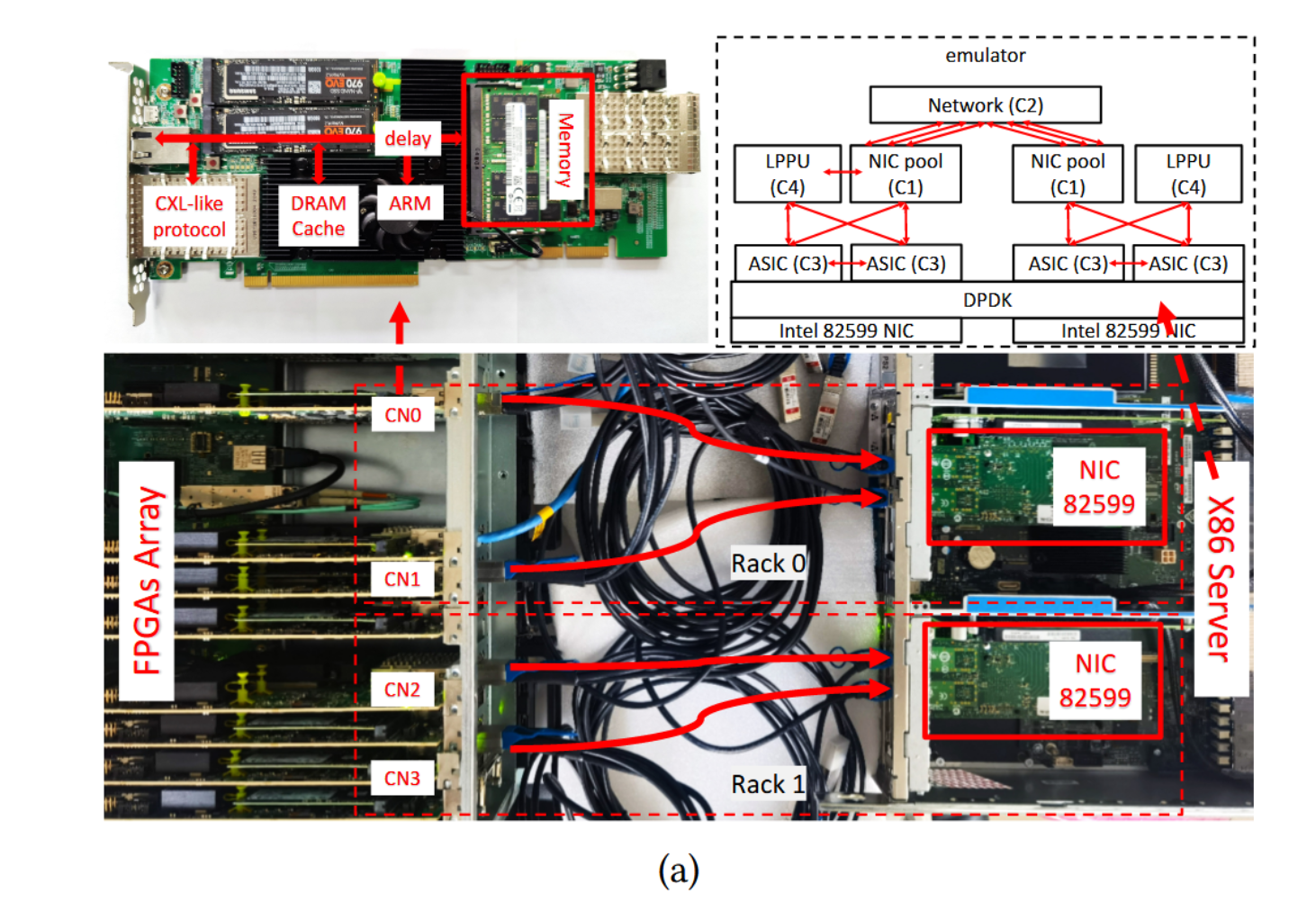

优点。与之前利用 NUMA 节点模拟类似 CXL 的加载/存储的工作相比,即对远程套接字内存的加载/存储模拟为 CXL,我们的平台可以调整加载和存储的延迟并转发 CXL-就像通过以太网跨多个设备进行事务来模拟 CXL 结构一样,而不是受到两节点(套接字)场景的限制 [41,48,56]。与在模拟器中实现 DFabric 相比,我们的原型可以在合理的时间内运行真实的应用程序。例如,全系统模式 Gem5 比真实系统慢数千倍[45],这使得它无法模拟完整的应用程序执行。
6 Evaluations
我们将两个原型的 MTU 设置为 4 KB,4KB 缓冲区属于 DRAM 缓存可缓存的区域。表 3 总结了实验中使用的配置参数值。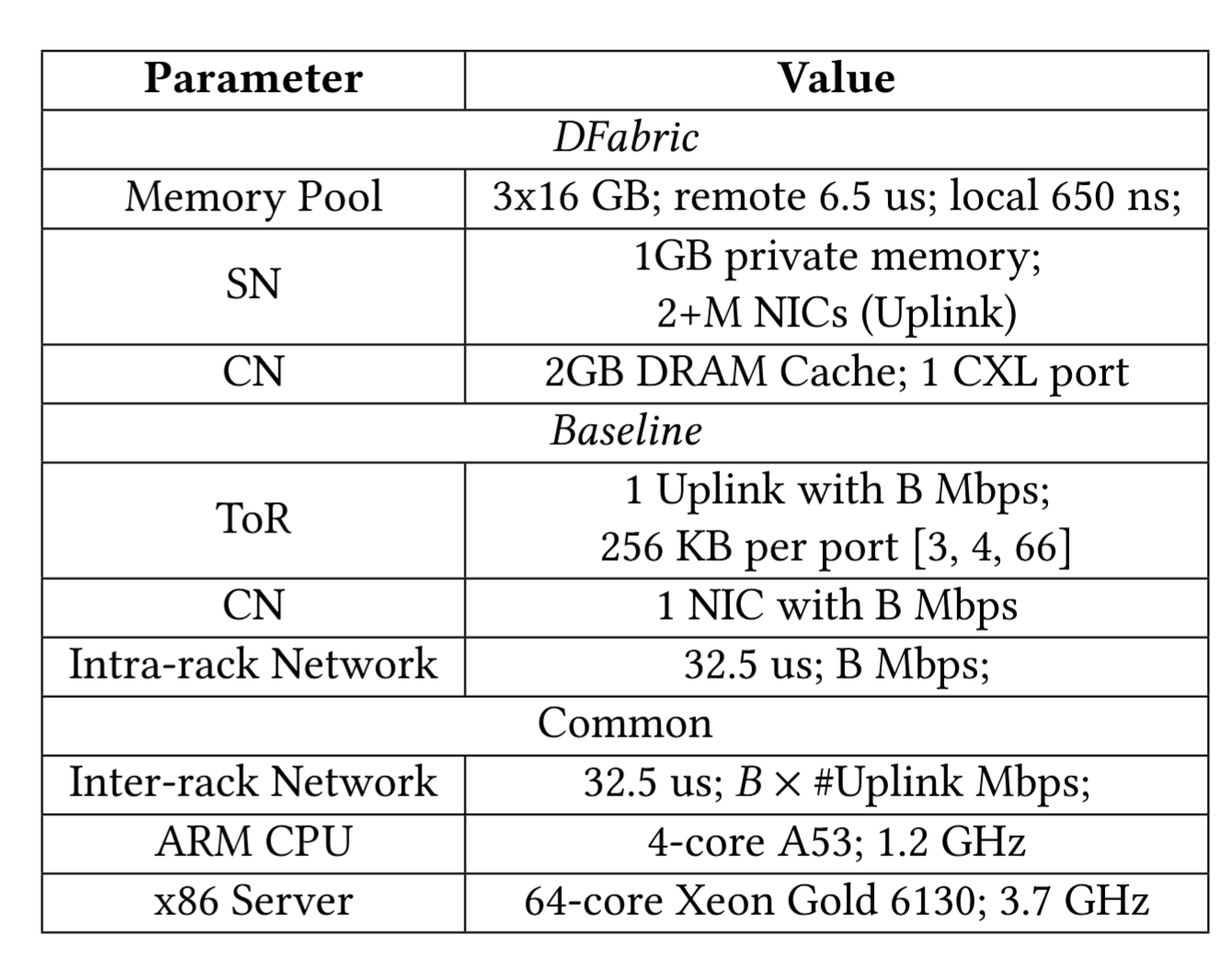
6.2 Real Application Workloads
- MapReduce
- GeminiGraph
- PyTorch Distributed Data Parallel (DDP)
- Redis
**Graph Processing.**:pagerank和BFS,数据为 LiveJournal 在线社交网络
DFabric 在最坏情况下(B = C 8 )平均可以减少 59.5% 的通信时间,在所有情况下可以减少 32.1% 的通信时间。每个 CN 将异步完成其顶点的迭代,以便 CN 在同步阶段可以独占使用 NIC 池。由于将数据包保存到内存池可以缓解 incast 等问题,因此 M 点(具有 C 4 的 NIC 池)的 DFabric 性能优于 N 点(具有 C 4 的 2 个 NIC)的基线。我们在图 9(f) 中展示了一次 PageRank 运行期间采样的通信吞吐量。与超级步数相同,存在 12 个带宽峰值,DFabric 与 Baseline 相比大大减少了通信时间。
Neural Networks:residual neural network ResNet18 [29] using the CIFAR-10 dataset
CXL 的高吞吐量和缓解 incast 问题的内存池导致通信时间平均减少 34.7%。
**WordCount.**:
我们通过配置一个 CN 来执行归约任务并配置其他三个 CN 来运行映射任务来运行 MapReduce WordCount
DFabric 将通信时间平均减少了 31.1%
Redis Cluster:我们在一个 CN 上作为客户端运行 Memtier_benchmark [55],并组织其他三个 CN 形成一个 Redis 集群。客户端根据键值对的分布向不同的服务器发送Get/Set请求。我们监控请求的平均延迟和 p99 延迟,因为 incast 问题会导致丢包,从而延长尾部延迟。在 DFabric 中,机架内的数据包丢失为零,因为传递的是引用而不是值,并且内存池将及时存储机架间数据包。如图 9(e) 所示,与 Baseline 相比,DFabric 将 p99 和平均延迟分别平均降低了 40.5% 和 22.8%。然而,当不存在网络瓶颈(B = C)时,由于内存池访问延迟较长,DFabric 会呈现较高的 p99 延迟。
7 Discussion
在 SN 中分离数据和控制平面是将任务分配给适当的计算资源的常见优化[28]。 DFabric将控制平面分配给LPPU,该控制平面不常被调用,复杂,充满控制路径,难以加速。 DFabric 将数据平面留给专用 ASIC,从而提供高数据处理吞吐量。然而,对于轮询任务,多核CPU或smartNIC可能有足够的能力[12]。例如,我们可以绑定一个核心来轮询一个CN或NIC
在 DFabric 中,子流根据其物理队列深度映射到一个 NIC。但还应考虑核心网的拥塞、跳数等因素。商业数据中心的拓扑需要模拟各种拥塞情况。我们假设本文中没有拥塞和一跳,并将其留待将来的工作
9 Conclusion
我们提出了一种新颖的互连架构 DFabric,它通过 NIC 池弥合互连和网络之间的带宽差距,并通过共享内存池和 DRAM 缓存等多种新颖设计优化其效率。我们构建了一个双机架原型并通过微基准测试和实际实验验证其性能
Back: you have read it ! Tags: cxl END
 wechat
wechat alipay
alipay


