

An Introduction to the Compute Express LinkTM (CXLTM) Interconnect
CXL简介:CXL论文
Panmnesia2023-09-18
CXL-SSDHello bytes, bye blocks | Proceedings of the 14th ACM Workshop on Hot Topics in Storage and File Systems
STARTBasic
An Introduction to the Compute Express LinkTM (CXLTM) InterconnectINTRODUCTION没有CXL的PCIe连接存在的挑战:
无法实现对系统和设备内存的一致性访问,设备内存无法映射到可缓存的系统地址空间 (有没有人做基于CXL的CPUGPU统一地址空间?)
内存可拓展性差:PCIe带宽不错,但是不支持一致性的内存空间,所以无法直接做内存拓展
由于资源闲置导致的内存和计算资源的浪费
分布式系统经常细粒度同步,通信延迟高导致需要数据共享
CXL能做的缓存一致性、可拓容、内存池、共享内存
CXL1.1CXL 68 byte FlitCXL协议的传输单元:Flit (FlowControl Unit).1.0 1.1 ...
What every programmer should know about memory
文档地址:What every programmer should know about memory
What every programmer should know about memoryintroduction内存性能的提升主要通过以下几个方面
RAM hardware design (speed and parallelism)
Memory controller designs.
CPU caches.
Direct memory access (DMA) for devices.
文章标题致敬
What Every Scientist Should Know About Floating-Point Arithmetic (oracle.com) 待阅读
关于南桥和北桥
北桥是负责连接CPU和高速组件的芯片组,包括内存控制器、图形处理器(如果有独立显卡)、高速系统总线(如前端总线)等。它通常位于主板上靠近CPU的位置,负责高速数据传输和协调CPU与其他主要组件的通信。
南桥则是连接北桥和其他低速外设的芯片组。它负责管理与外部设备的连接,包括硬盘驱动器、US ...

CMU 10-414/714 机器学习系统
CMU 10-414/714 机器学习系统lecture 0 机器学习数学基础线性代数空间:满足一定条件的集合
向量空间:定义了加法和数乘这两种运算的集合
向量:向量空间的元素
向量组:若干个同维数的列向量或行向量组成的集合叫做向量组
线性相关性:给定向量组A:a1,a2,a3,…,am,如果存在不全为零的λ1,λ2,…,λm使得λ1a1+λ2a2+…+λmam=0,则称A是线性相关的,反之则是线性无关。 ^8afaa2
内积:X点乘Y,即两个维数相同的向量每个对应的元素相乘,满足交换律,结合律,分配律
范数(Norm):范数定义向量空间的距离,可以将向量映射到非负实数,用||x||来表示
L1范数:曼哈顿距离,一个元素中所有元素绝对值之和,||x||1= |x1| + |x2| + … + |xn|
L2范数:欧几里得范数(Euclidean Norm),定义为向量各元素平方和的平方根,记作 ||x||2。对于n维向量x=[x1, x2, …, xn],其L2范数为:||x||2 = sqrt(x1^2 + x2^2 + … + xn ...



Cmake
cmake步骤
编写源代码
编写CMakeList.txt
cmake [`CMakeList.txt`所在的目录]
12345 这将生成makefile4. ```makefile make [makefile所在的目录]
编译完成
cmake关键字PROJECT关键字可以用来指定工程的名字和支持的语言,默认支持所有语言
PROJECT (HELLO) 指定了工程的名字,并且支持所有语言—建议
PROJECT (HELLO CXX) 指定了工程的名字,并且支持语言是C++
PROJECT (HELLO C CXX) 指定了工程的名字,并且支持语言是C和C++
该指定隐式定义了两个CMAKE的变量
_BINARY_DIR,本例中是 HELLO_BINARY_DIR
_SOURCE_DIR,本例中是 HELLO_SOURCE_DIR
MESSAGE关键字就可以直接使用者两个变量,当前都指向当前的工作目录,后面会讲外部编译
问题:如果改了工程名,这两个变量名也会改变
解决:又定义两个预定义变量:PROJECT_BINARY_DIR和PROJECT ...
open mlsys
编程接口编程接口:python等脚本语言作为上层接口,c/c++等底层语言来保证性能。
机器学习工作流
数据处理
模型定义:定义神经网络结构
定义损失函数和优化器
训练及保存模型
测试和验证
神经网络层
全连接(Full Connected,FC):当前层每个节点都和上一层节点一一连接,本质上是特征空间的线性变换。
卷积(Convolution):
先定义一个卷积核,通常是N*M的张量,NM通常是奇数,以便让卷积核有一个中心点,
将卷积核对准特征图的某个位置计算卷积。
卷积操作是将卷积核中的值与输入图像或特征图中的对应位置的像素值相乘并将所有成绩相加得到一个单一的值,这个值就是卷积核在当前位置的输出值
将卷积核在输入图像或特征图上沿x和y轴滑动,直到覆盖完整个输入图像或特征图。每次滑动都会计算出一个卷积核的输出值,最终得到一个新的输出图像或特征图。
在卷积神经网络中,通常会将多个卷积核组合在一起使用,以提取不同的特征。这些卷积核可以并行进行卷积操作,产生多个特征图,然后将这些特征图合并在一起,以进一步提高模型的表达能力。
池化(Pooling):
常见的降维操 ...

Kokkos编程指南
KOKKOS编程指南1.简介相比于其他并行编程模型的特点:可移植性
2.machine model为了实现跨架构的可移植性,并保证性能,kokkos有两个重要组件
内存空间:可以在其中分配数据结构
执行空间:使用一个或多个内存空间的暑假执行并行操作
kokkos抽象机器模型
执行空间执行空间用来描述一组并行执行资源,不同的执行空间可以队形不同的计算资源,例如多核CPU、GPU、加速器。Kokkos 模型抽象了为不同执行空间编译代码和将内核调度到实例的方法。这使得应用程序程序员无需使用特定于硬件的语言编写算法。
内存空间计算节点中多种类型的内存由kokkos通过内存空间抽象。
内存空间的实例为程序员提供了一种请求数据存储分配的具体方法,可以用多个内存空间对应不同种类的内存。
原子访问:对于race conditions,可以使用锁, critical regions, 原子操作来避免。
kokkos中的内存一致性问题:kokkos中 内存一致性极弱,程序员应当显示编程保证内存操作的顺序正确,kokkos提供了fence来达到这一点。
3.编程模型kokkos编程模型6个核心抽象:执 ...

Rocm
ROCm——open software platform for accelerated computing
拥有完善的库、工具和管理API
拥有开源的OpenMP和HIP编译器
规模从工作站到云到百万兆级计算
完善的生态系统
HIP:c++运行时api,支持AMD和nvidaGPU
AMD硬件架构GCN 硬件概述AMD GPU由一个或多个着色器引擎(SE)以及一个命令处理器组成,着色器引擎内又有负载管理器和计算单元(CU)。
命令处理器从命令队列中读取命令,提交给工作负载管理器,然后工作负载管理器将任务分配给计算单元。
以下部分AMD设备的SE、CUs/SE数量
workgroup–block
workitem–thread
wavefont–warp
amd硬件允许每个workgroup最多有16个wavefont
将硬件和抽象对应起来,AMD GPU的调度方式如下:
命令处理器从命令队列中获取kernel,创建workgroup,然后将其分发到SE,SE上的工作负载管理器为workgroup创建wavefont,并将其发送到CU。与cuda相同,一个workg ...
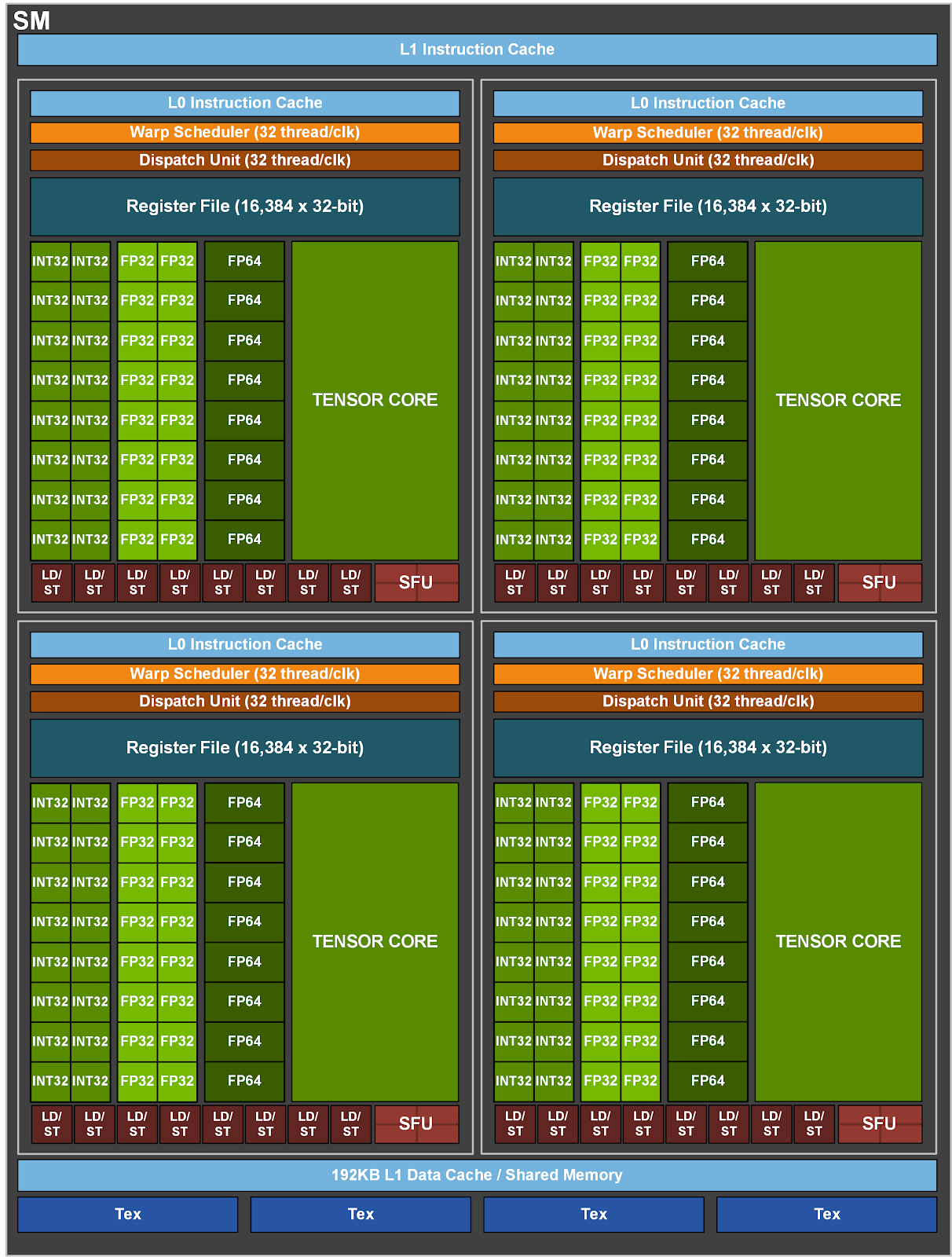
cuda c权威编程指南笔记
cuda c权威编程指南笔记一、基于CUDA的异构并行计算1.1并行计算并行性:包括任务并行和数据并行。
当多任务或函数可以独立的大规模的并行执行时,就是任务并行,任务并行的重点在于利用多核系统对数据进行分配。
当同时处理许多数据时,就是数据并行,数据并行的重点在于数据的分配。
CUDA编程非常适合解决数据并行计算的问题
数据划分方法:块划分和周期划分
块划分:每个线程计算一部分数据,通常这些数据有相同的大小
周期划分,每个线程计算数据的多部分
二、CUDA编程模型关于cudaMalloc()参数的解释
12int *da;cudaMalloc((void**)&da,size);
这里da是int指针,在cudaMalloc()的参数中需要一个指向指针的指针(即void**),来将这个指针的值改变为GPU中的内存地址。如果直接传这个指针,只能改变这个指针指向地址的值而不能改变该指针的指向地址(值传递,实际上形参只复制了指针指向的地址)。
关于cudaMemcpy()的同步问题:
a)同一个stream(包括默认stream)中的kernel后面的copy函数总是会等到ke ...

